이전의 Git 으로 데이터셋 API 공유하기에서 github 에 데이터셋을 다루는 파이썬 패키지를 올려 이용하자는 이야기를 하였습니다. 이 패키지는 파이썬 함수들만 업데이트 되어 있으며, 실제 데이터 파일과 학습된 모델 파일들은 외부 링크로 공유하였습니다. 이러한 파일들을 올려둘 목적으로 AWS S3 를 이용하기로 결정했습니다. 이번 포스트에서는 S3 에 bucket 을 만들고 파일을 업로드, public 으로 공유, acecss log 를 기록하는 과정을 정리하였습니다.
배경
이전의 Git 으로 데이터셋 API 공유하기에서 github 에 데이터셋을 다루는 파이썬 패키지를 올려 이용하자는 이야기를 하였습니다. 그러나 아직 만들고 있는 패키지와 데이터 파일은 고정되기 전까지 업데이트가 계속될 것입니다. 또한 git 은 이전 버전에 대한 로깅을 하기 때문에 혹여 데이터 파일의 내용이 바뀐다면 불필요한 로그들이 많이 남을 수 있습니다. 그래서 github 으로는 패키지의 파이썬 파일만 공유하고, 실제 데이터 파일은 드랍박스와 같은 외부 링크를 이용하였습니다. 그런데 최근에 드랍박스의 링크들이 깨지기도 하였고, AWS 에서 데이터를 수집할 일들이 있어서 S3 를 써보면 좋겠다는 생각을 하였습니다. 더욱이 AWS CLI (Ubuntu terminal 에서 aws 를 다룰 수 있도록 도와주는 Command Line Interface) 가 편리해 보였습니다. github io 외에, 하나 더 호스팅하고 싶은 블로그도 있기도 했고요.
AWS 웹페이지에서 S3 에서 Bucket 을 만들고 데이터를 올리는 과정이 어렵지는 않습니다만, public 으로 만들 때 몇 번의 시행착오를 겪었습니다. 이후에 해매지 않기 위해 그 과정을 정리하였습니다.
AWS S3
aws.amazon.com 에 가셔서 로그인을 합니다. 이미 다른 서비스를 이용하신 분들은 ‘최근 방문한 서비스’에 S3, EC2 와 같은 서비스들이 위치합니다. S3 는 쉽게 말해 데이터 저장 공간을 빌리는 서비스입니다. (S3 는 Simple Storage Service 의 약어입니다). 데이터를 저장하거나, 이를 다운로드 받거나, 정적 웹사이트를 호스팅하는 기능을 제공합니다. EC2 는 Elastic Compute Cloud 의 약어로, 쉽게 말해 machine 을 빌려주는 서비스 입니다. 실험용 머신을 빌릴 수도 있고, 동적 웹사이트를 호스팅할 수도 있습니다. 데이터를 저장하고 공유하는 기능만을 이용할 것이라면 S3 가 저렴합니다.
Bucket 만들기
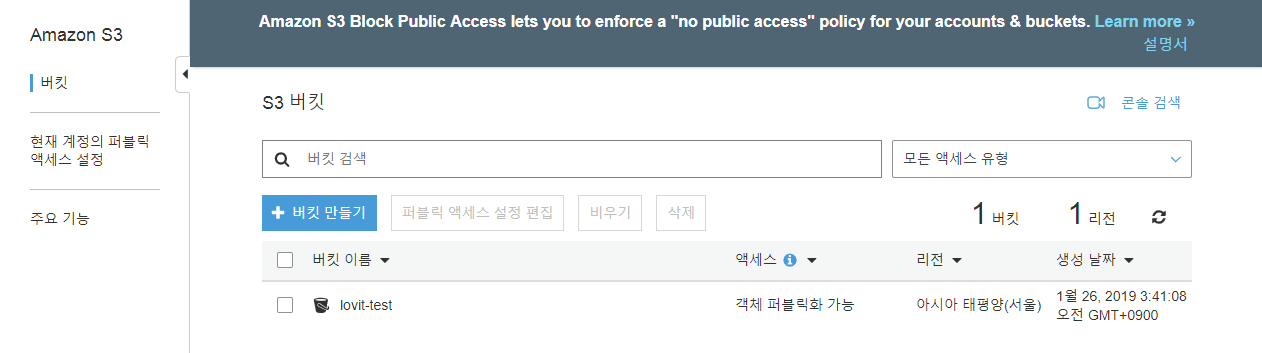
S3 를 들어오면 처음에 아무런 bucket 이 없는 화면이 나옵니다. Bucket 은 데이터를 공유하는 하나의 디스크라고 생각하면 좋습니다. bucket 의 이름이 디스크의 이름입니다. 만약 ‘lovit’ 이라는 이름의 bucket 을 만든다면, 이 bucket 안의 파일들은 아래와 같은 url 을 가지게 됩니다. Region 은 S3 서비스를 제공하는 지역입니다. 서울의 region 은 ap-northeast-2 인데, 이는 bucket 을 만들 때 설정할 수 있습니다. bucket 이야 개념적인 디스이지만, region 은 물리적인 개념입니다. 실제로 데이터를 보관하는 기계가 서울에 있다는 의미입니다. 그리고 region 과 접속하는 지역이 멀면 실제로 데이터 전송 속도가 느립니다.
https://s3.<REGION>.amazonaws.com/lovit/<FILEPATH>
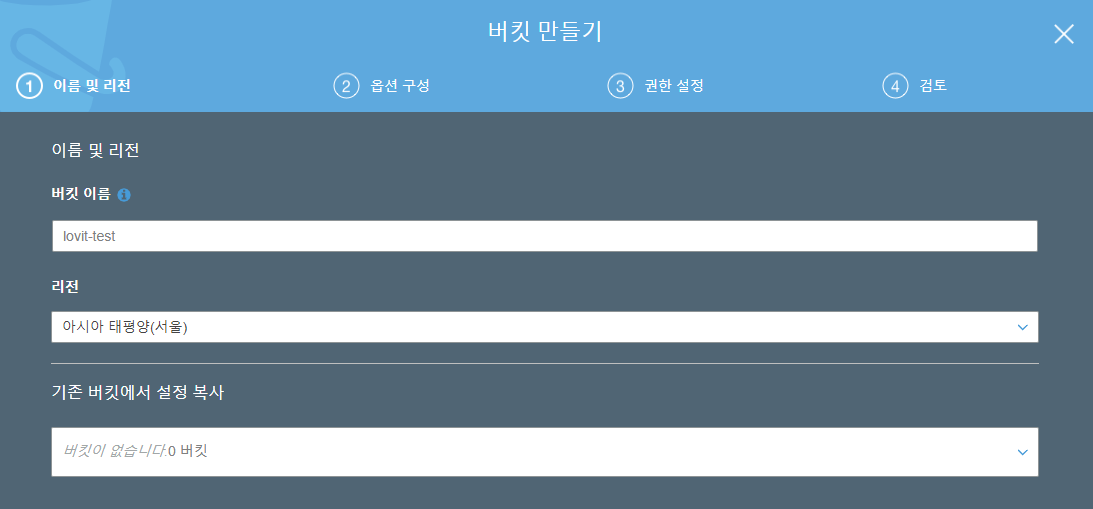
일단 버킷 만들기를 누릅니다. lovit-test 라고 버킷 이름을 지정합니다. 이 버킷 이름은 AWS S3 서비스 내에서 고유해야 합니다. 이미 존재하는 이름이라면 존재하는 이름이라고 오류 메시지가 출력됩니다. 그리고 리전 (region) 을 설정합니다. 저는 서울로 설정하였습니다. 다음을 누릅니다.
그 다음 페이지는 딱히 설정할 것이 없습니다. 또 다음을 누릅니다.
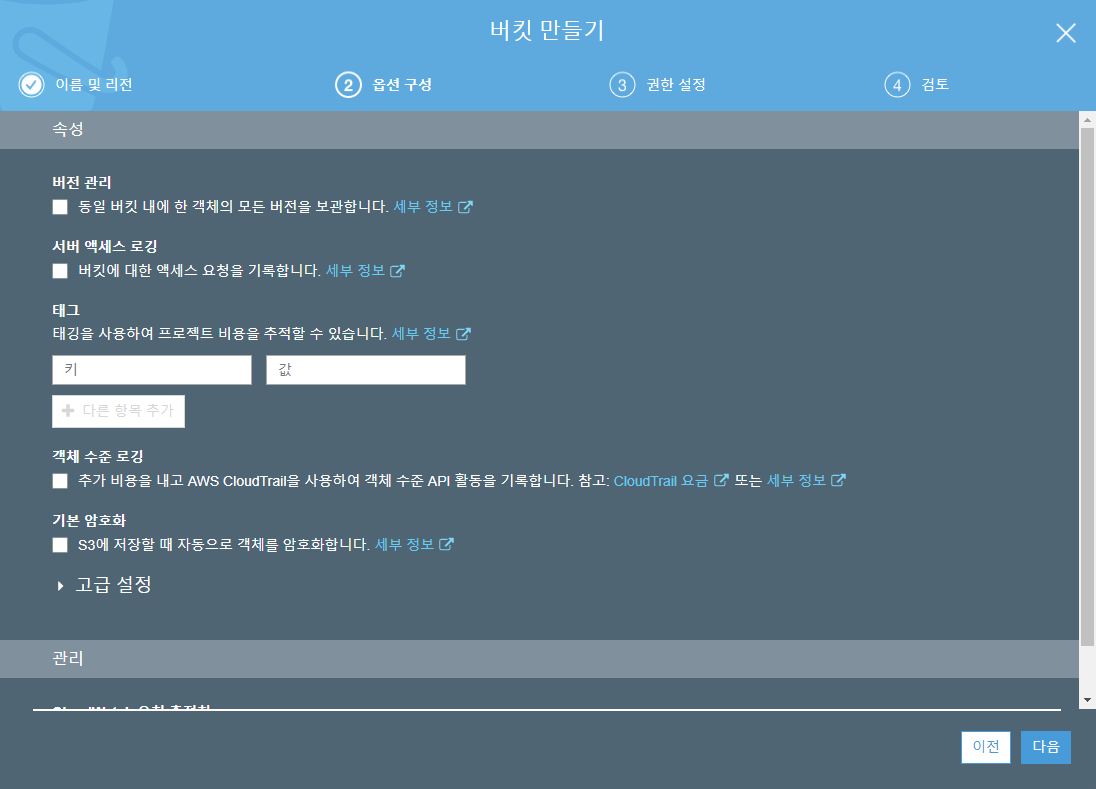
퍼블릭 엑세스 설정 메뉴가 나옵니다. 퍼블릭 (public) 이란 파일, 디렉토리, 혹은 버킷을 다른 임의의 사용자가 접근할 수 있다는 의미입니다. S3 는 기본적으로 private 로, 작성자와 권한을 부여한 일부의 사용자만이 접근 가능합니다. 그러나 웹사이트와 같은 서비스는 임의의 사용자들이 버킷 내 파일에 접근 가능해야 합니다. 하지만 데이터 보호를 위해서 기본은 private 로 설정되어 있습니다. 그리고 실수로 파일이나 버킷을 퍼블릭으로 변환하는 것을 방지하기 위하여 안정장치들을 두었습니다.
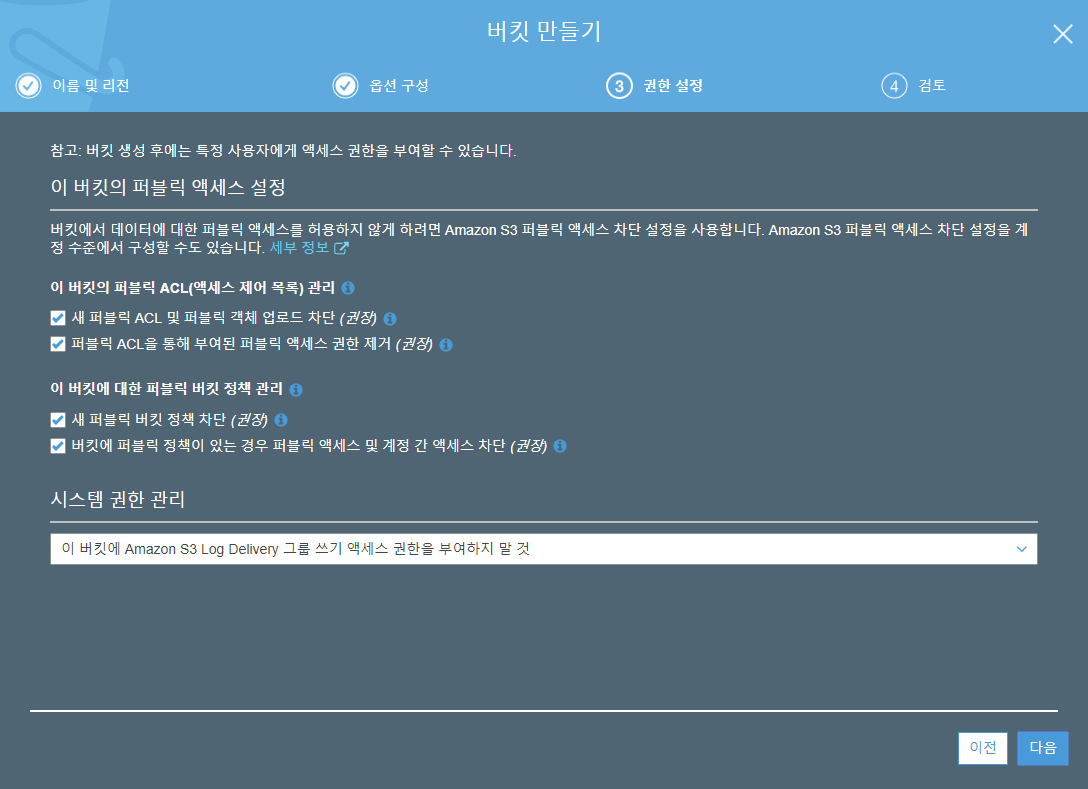
일단 위처럼 버킷을 만들어봅니다. 다음 화면도 다음, 버킷 만들기를 누릅니다.
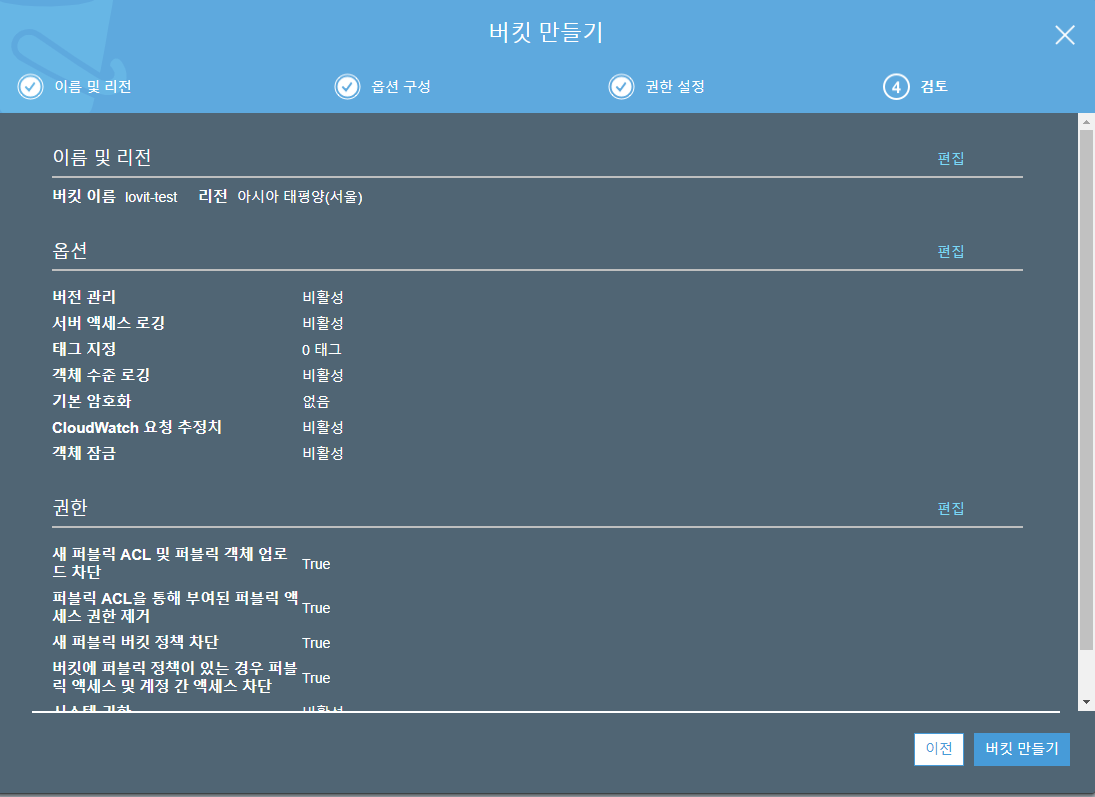
그 결과 이번에 만든 lovit-test 라는 버킷의 엑세스 (access)는 퍼블릭 아닌 버킷 및 객체 로 설정됩니다. 영어로 표기될 때 Bucket and object not public 입니다. 처음에 도대체 무슨 말인지 이해하질 못했습니다.

버킷을 만든 뒤에도 퍼블릭 엑세스 설정을 변경할 수 있습니다. 바로 위의 퍼블릭 엑세스 설정 변경 메뉴를 가셔서 아래처럼 설정합니다.
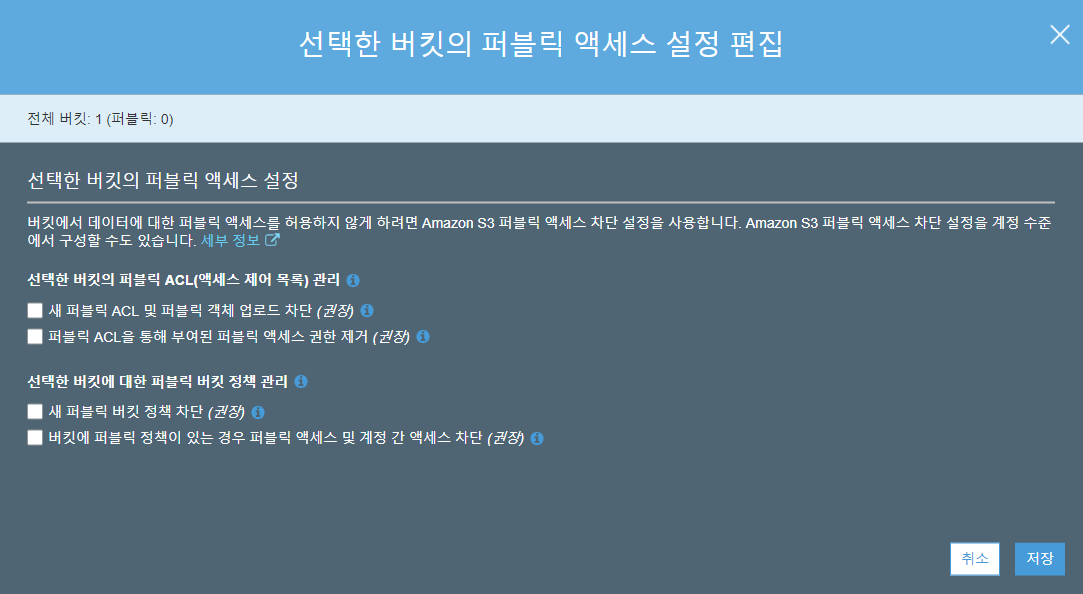
설정이 변경되면 아래처럼 객체 퍼블릭화 가능으로 표시됩니다. 이 상태가 되어야 파일의 공유가 가능합니다.
만약 이 과정이 되지 않는다면 화면 전체에서 좌측 두번째, 현재 계정의 퍼블릭 엑세스 설정에서 동일한 작업을 해줍니다. 설정 후 저장을 눌러야 설정이 반영됩니다.
버킷에 파일 업로드
이번에는 AWS CLI 를 이용하지 않고, 웹페이지에서 파일을 올려봅니다. AWS CLI 는 다른 포스트에서 정리합니다. 폴더 만들기나 업로드처럼 사용법은 직관적입니다.
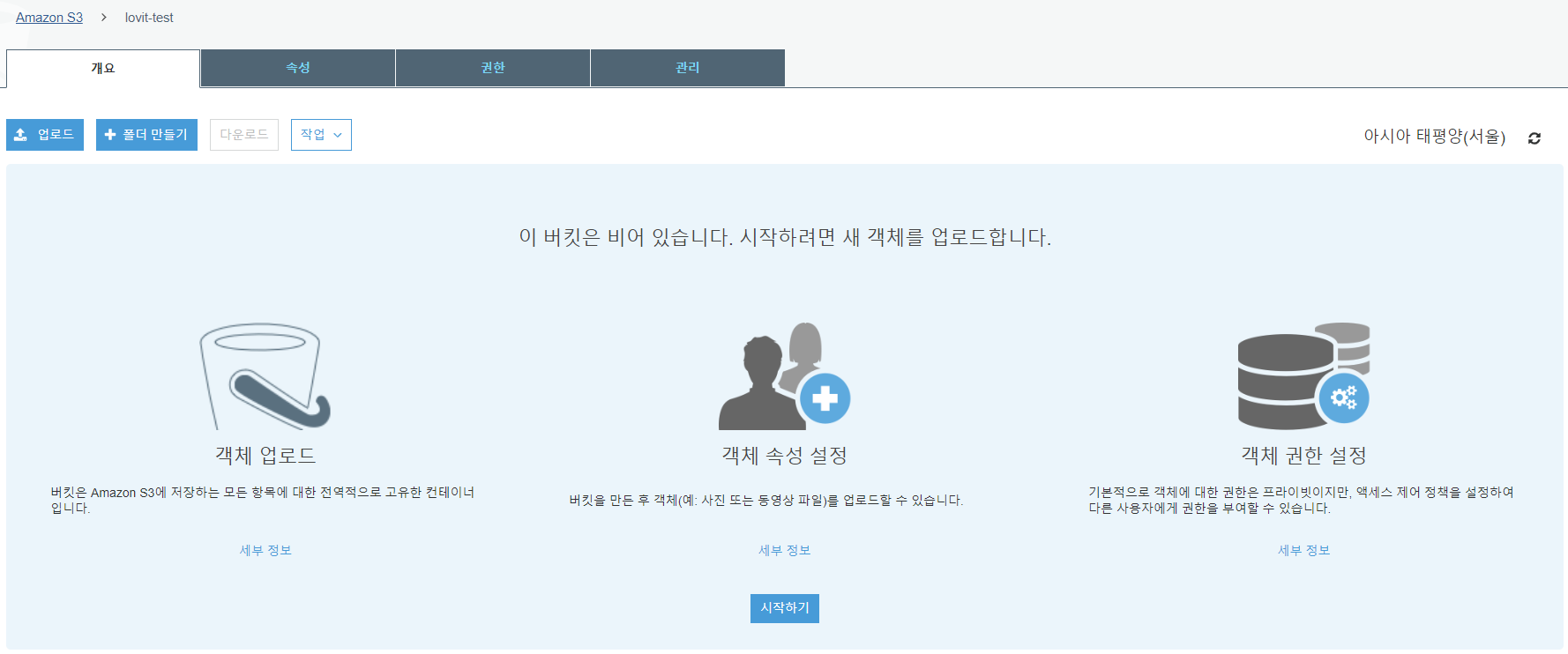
파일을 올릴 때 권한 설정에서 퍼블릭 권한 관리에서 퍼블릭 읽기 엑세스 권한을 부여함으로 설정해야 합니다.
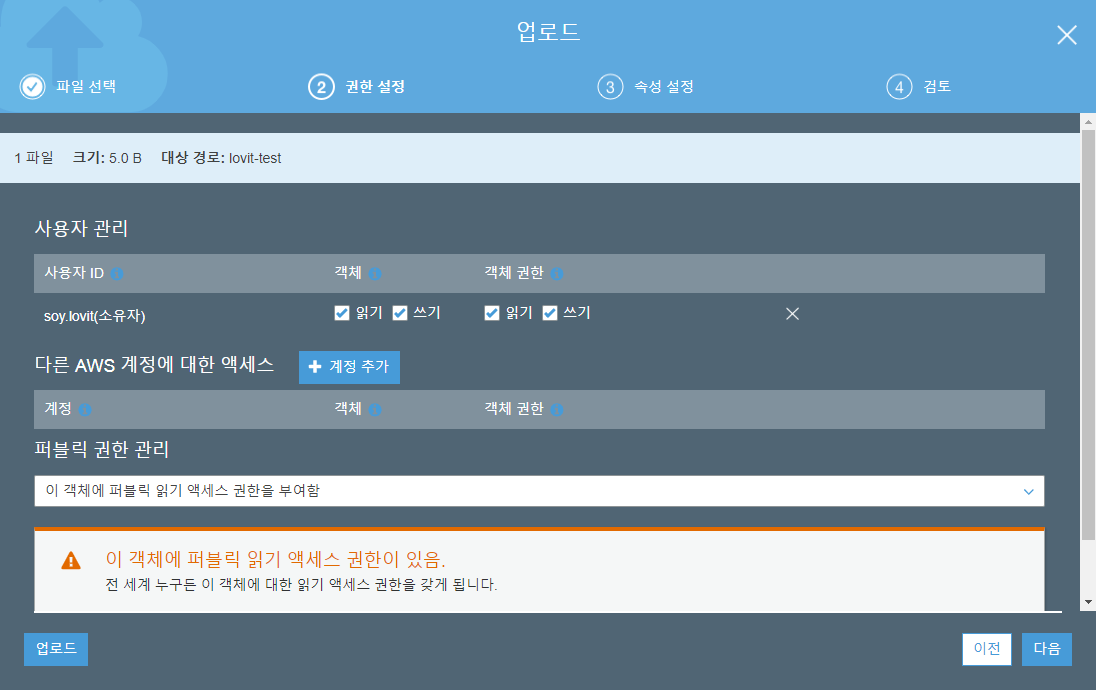
이를 설정하면 어떤 종류의 S3 를 이용할지 설정합니다. 빈번하게 수정되거나 빈번하게 다운로드 받는지, 혹은 한 번 저장한 뒤 간헐적으로 접근하는 것인지에 따라서 가격이 다릅니다. 각 Storage class (파일 활용 용도 설정) 에 따른 가격은 여기에 나와있습니다. 데이터 버전이 확정되어 오래도록 보관할 것이라면 Standard IA (Infrequent Access) 를 선택할 수도 있지만, 지금은 Standard 로 설정합니다.
파일이 성공적으로 업로드가 되면 파일을 클릭합니다. 고유 url 이 있습니다. 이를 클릭해봅니다. 만약 파일이 public 이 아니라면 아래와 같이 access denied 라는 메시지가 뜹니다.

업로드 된 파일을 퍼블릭으로 만드려면 파일을 클릭하여 권한을 누릅니다. 퍼블릭 엑세스의 Everyone 을 누르면 우측의 이 객체에 엑세스 아래 객체 읽기 가 있습니다. 이를 클릭해주면 해당 파일이 public 으로 변환됩니다.
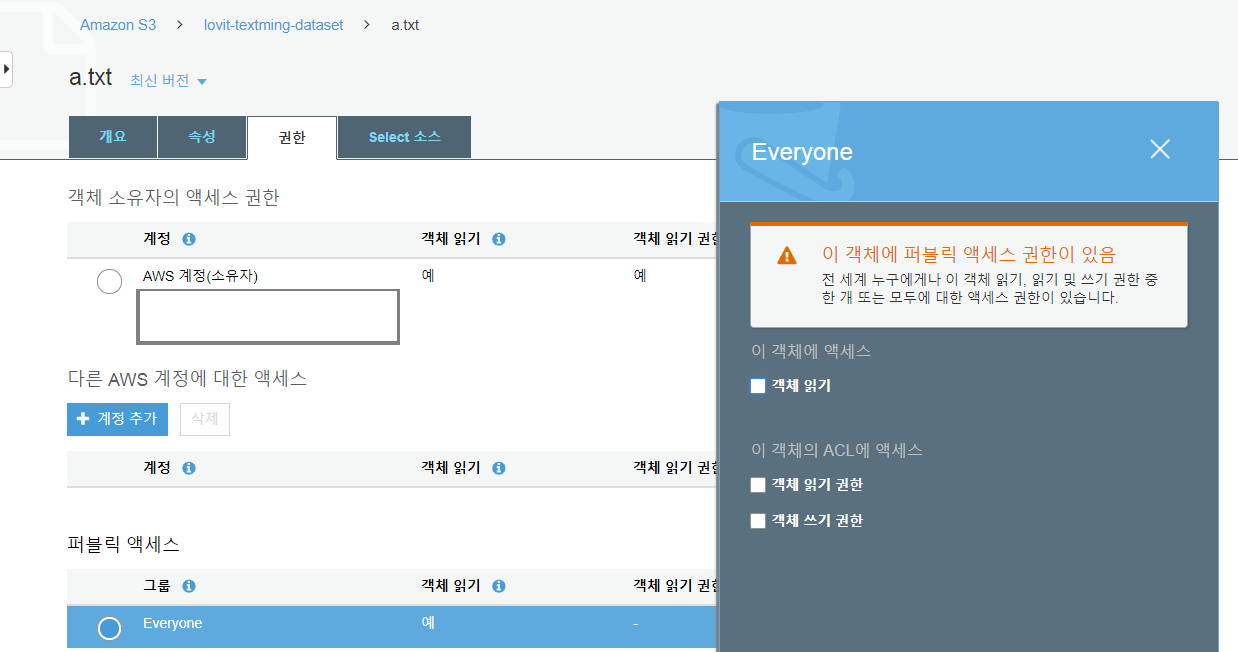
S3 는 파일에 대한 저장 비용도 있지만, 파일을 다운로드 받을 때마다의 통신 비용도 있습니다. (물론 매우 작습니다.) 또한 비공개여야 할 파일이 공개되지 않도록 관리도 해야 하니 권한 설정을 신경써야 합니다.
퍼블릭 엑세스 권한 설정을 한 뒤, 해당 파일 url 을 입력하면 파일이 다운로드 되거나, HTML, text 파일 등은 브라우저에서 읽어짐을 확인할 수 있습니다.
에러가 날 경우
만약 파일을 퍼블릭으로 올릴 수 있는 권한이 없을 때 위와 같이 파일의 권한을 바꾼다거나 퍼블릭으로 파일을 올리려 하면 에러가 발생합니다. 화면 하단에 <진행 중, 성공, 오류 발생> 세 가지에 대하여 로그가 쌓입니다. 오류 발생을 클릭해보면 어떤 작업에서 오류가 발생했는지 메시지를 보여줍니다.
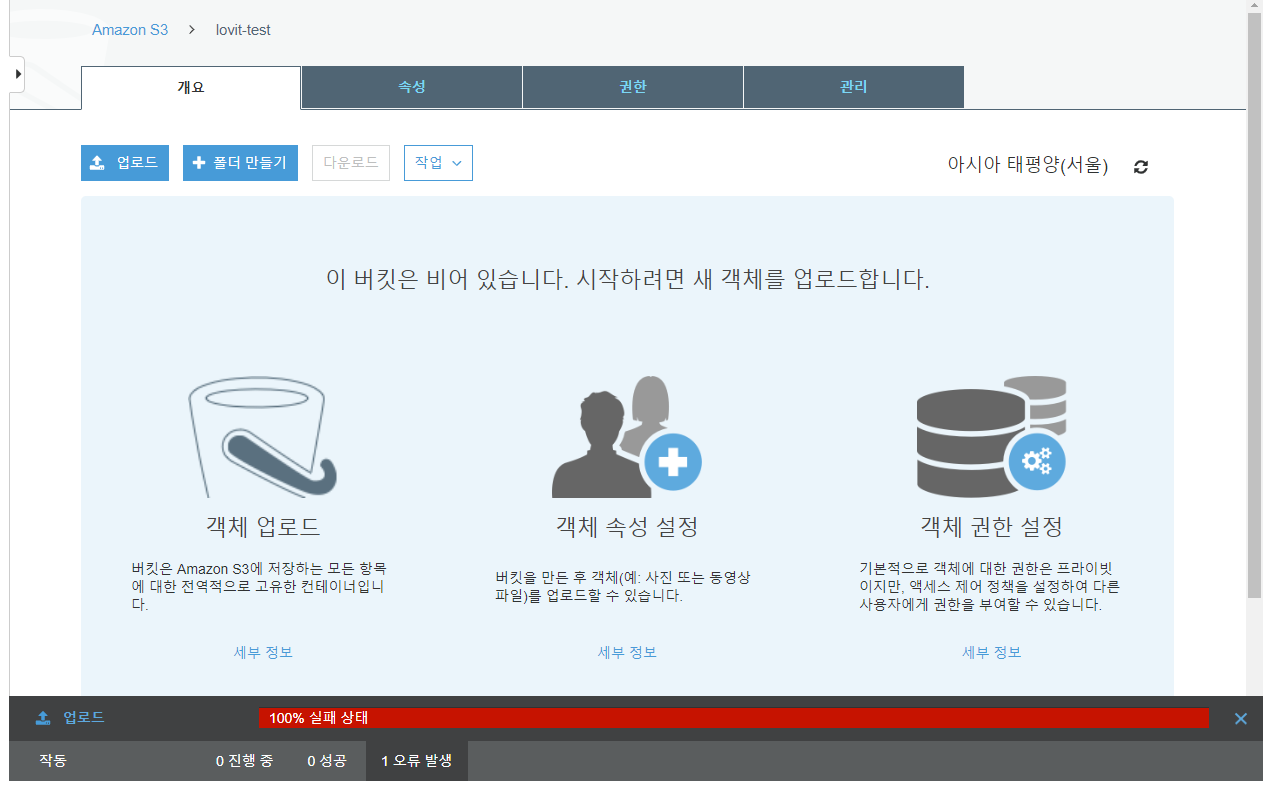
처음에 화면 맨 하단에 이와 같은 메뉴가 있는지도 몰랐습니다. 이런 중요한 정보를 너무도 평범한 색의 너무도 작은 글자로 표시하다니 …
그리고 이 에러는 버킷이 퍼블릭 아닌 버킷 객체 (Bucket and object not public) 으로 설정되어 있을 때 발생합니다. 퍼블릭 엑세스 설정 변경, 그리고 현재 계정의 엑세스 설정 변경의 옵션을 변경 » 저장하면 됩니다.
Access log
공유된 파일을 다른 사람들이 얼마나 접근하는지 알아보아야 합니다. 혹은 악의적인 공격은 없는지도 파악해야 합니다. (그럴 일은 적겠지만) AWS 는 다운로드 용량 단위로 과금이 청구되기 때문입니다. 그 외에도 어떤 시기에 어떤 데이터가 얼마나 많이 공유되는지도 살펴보려면 logging 을 해야 합니다.
AWS 는 bucket 의 파일 접근에 대한 로깅을 할 수 있도록 도와줍니다. 먼저 로깅할 버킷을 클릭합니다. 현재 상단의 개요 tap 이 활성화 되어 있을 겁니다. 그 옆의 속성 tap 을 누르면 여러 옵션들이 뜹니다. 저는 방금 access log 를 기록하기 시작했기 때문에 서버 액세스 로깅이 활성화 되어 있습니다. 이를 클릭합니다.
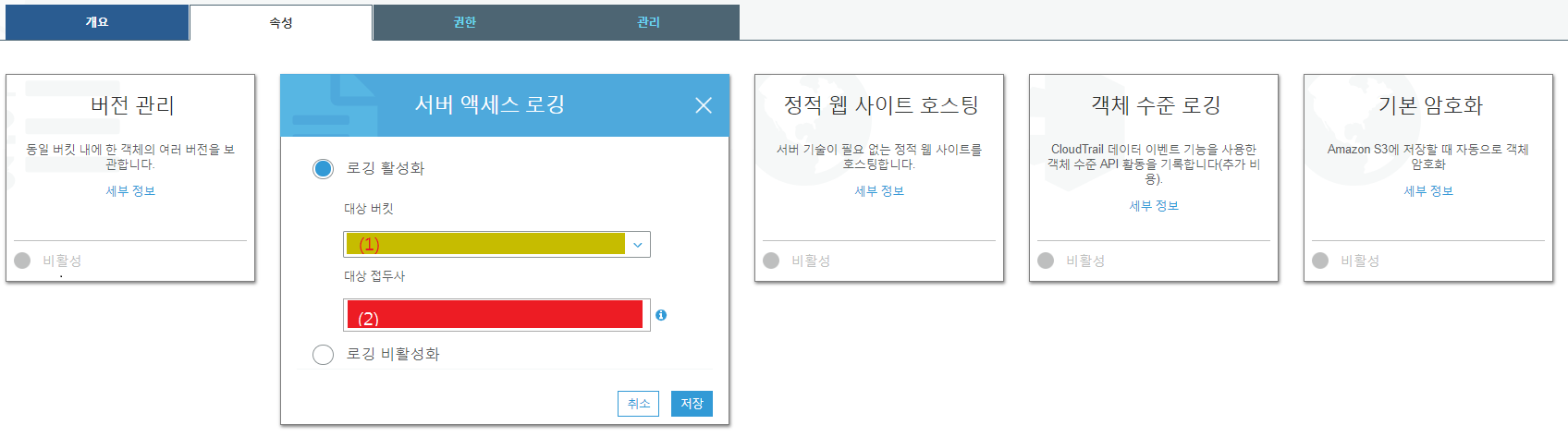
대상 버킷 (1) 과 대상 접두사 (2) 를 입력합니다. 대상 버킷은 log 를 쌓을 버킷입니다. 버킷의 root 에 로그가 쌓이기 때문에 로깅용 버킷은 따로 만드는게 좋습니다. 저는 제 버킷들의 access logs 를 모아두는 버킷을 하나 만들었습니다. 그 이름을 (1) 에 입력합니다. 클릭하면 보유한 버킷 리스트가 뜹니다. 그 중에서 클릭을 하면 됩니다.
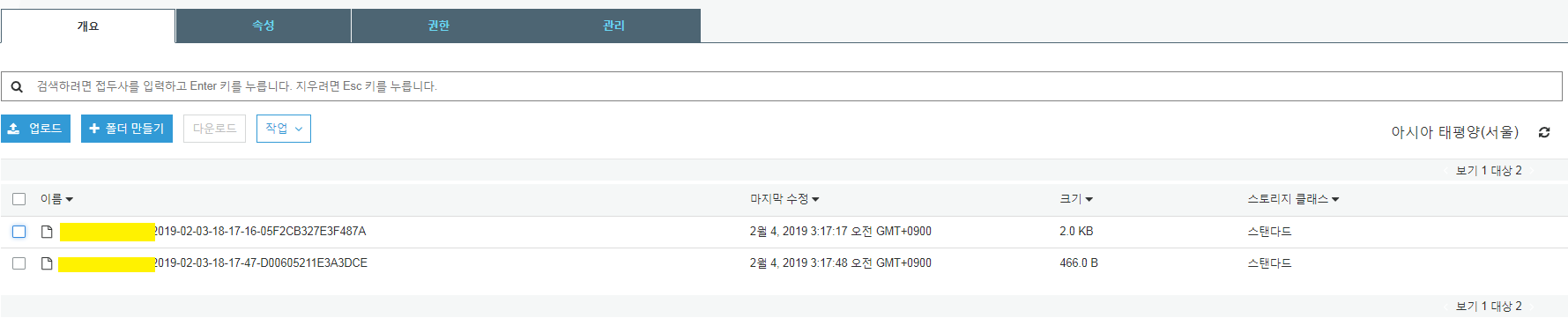
그러나 모든 버킷마다 각자의 로깅용 버킷을 만들 필요는 없습니다. 하나의 로그 버킷에 여러 버킷의 access logs 를 저장할 수 있습니다. 이때는 각 로그가 어떤 버킷에서 작성된 것인지를 파악하기 위하여 접두사 (prefix) 를 입력합니다. 파일 형식은 PREFIXyyyy-mm-dd-hh-MM-ss-hashvalue 형식입니다. prefix 의 마지막에 - 를 붙여두면 구분이 쉽습니다.
저장을 누른 뒤부터 해당 버킷의 파일을 access 할 경우 (1) 의 버킷에 로그가 쌓입니다. 로깅 버킷에 로그가 쌓일 때에는 수 초에서 수 분 정도 time delay 가 생길 수 있습니다. 확인 결과 아래와 같은 로그가 생겼습니다. 로그 파일 안에는 접속 환경, 접속 주소, 명령어 등이 포함되어 있습니다.