토크나이징 (tokenizing) 은 문장을 토큰으로 나누는 과정입니다. 토큰의 정의는 분석의 목적에 따라 어절, 단어, 형태소가 될 수 있습니다. 토크나이징이 된 결과는 term frequency matrix 혹은 doc2vec 과 같은 형식의 벡터로 데이터를 표현하는데 이용됩니다. 트렌드 분석, 키워드 추출에서는 미등록단어 문제를 반드시 풀어야 합니다. 미등록단어들이 트렌드의 키워드일 가능성이 높기 때문입니다. 그러나 문서 판별, 감정 분류, 번역과 같은 문제를 풀 때는 토크나이저가 반드시 제대로 된 단어를 인식할 필요는 없습니다. 분석의 대상이 단어가 아닌 문장이나 문서이기 때문에 질 좋은 벡터만 만들어지면 됩니다. 단어를 제대로 인식할 필요가 없는 경우에 쓸만한 토크나이저에 대하여 이야기합니다.
Trained tokenizer is necessary ?
토크나이징은 데이터와 텍스트 마이닝이 만나는 첫 지점입니다. 토크나이징의 결과에 따라 마이닝 결과의 품질이 달라질 수 있습니다. 좋은 토크나이저의 기준은 목적에 따라 다릅니다. 반드시 단어가 제대로 인식되어야 하는 것도 아닙니다. 키워드 분석을 위해서는 단어가 제대로 인식되어야 합니다. 분석의 단위가 단어이기 때문입니다. 하지만 문서 판별이나 문장의 감성 분석을 위해서는 문장이 제대로 된 단어열로 표현될 필요는 없습니다. 대신 질 좋은 features 를 포함하는 질 좋은 벡터로 표현되면 됩니다. 아래의 문장을 단어열이 아닌 subwords 로 토크나이징 하여도 이 문장은 긍정문이라는 것을 예측할 수 있습니다. ‘재미있’이 감성 분석의 중요한 feature 가 되기 때문입니다.
문장: '이영화 정말 재미있다'
단어열: [이, 영화, 정말, 재미, 있다]
subwords: [이영화, 정말, 재미있]
질 좋은 features 로 이뤄진 벡터 공간의 조건 중 하나는 ‘같은 정보가 같은 feature 에 저장’되는 것입니다. ‘재미있는, 재미있고, 재미있당’ 이 모두 ‘재미있’ 이라는 subword 로 표현된다면 같은 정보가 하나의 차원에 저장됩니다.
세 어절이 각각 ‘재미있는 = 재미있 + 는’, ‘재미있고 = 재미 + 있고’, ‘재미있당 = 재 + 미있당’으로 토크나이징 되었다면, ‘재미있다’는 개념을 표현하기 위해 여러 개의 features 가 이용됩니다. 물론 세 features 모두 긍정의 의미를 나타내기 때문에 감성 분석의 성능에는 큰 영향이 없습니다. 하지만 같은 정보를 여러 차원에 중복하여 저장하는 것은 벡터 공간을 효율적으로 쓰지 못함을 의미합니다. 때로는 알고리즘에 따라서는 패러매터 학습이 제대로 되지 않는 경우도 있습니다.
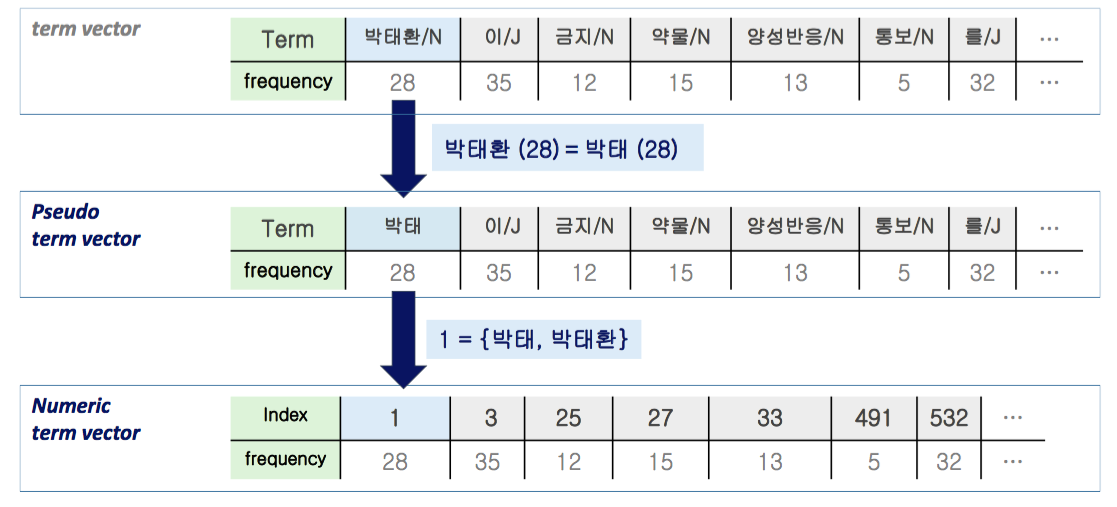
아래는 꼬꼬마 형태소 분석기를 박태환 선수에 대한 기사에 적용한 뒤, 명사와 동사의 단어 빈도수를 계산한 예시 입니다. 박태환 선수의 이름에 조사가 결합된 ‘박태환의’는 ‘박태 + 환의’ 로 분할 되었습니다. 그 외에도 박태환 이라는 하나의 개념이 [박, 태환, 박태, 환] 과 같이 여러 개의 features 로 나뉘어졌습니다.
이=18, [[ 태환=16 ]], [[ 박=15 ]], 원장=14, 하=14,
호르몬=13, 김=13, [[ 박태=13 ]], 주사=11, 남성=11,
월=11, 받=10, 말하=10, 누나=10, 것=10,
병원=9, 고=8, 작년=7, 측=6, 대하=6,
맞=6, [[ 환의=6 ]], [[ 환=6 ]], 있=6
하나의 개념이 여러 개의 subwords 로 나뉘어지면, co-occurrence 를 기반으로 하는 연관어 분석이나 토픽 모델링은 잘못된 패턴을 학습합니다.
Substring (Left-side syllables) tokenizer
간단한 미봉책을 소개합니다. 띄어쓰기가 잘 지켜진다면 어절은 띄어쓰기 기준으로 잘 나뉘어집니다. 대표적으로 뉴스 문서가 이에 해당합니다. 이처럼 띄어쓰기가 잘 지켜진 문서 집합이라면 어절 왼쪽의 k 개의 글자만 subword (psuedo term) 으로 취하는 토크나이저를 적용해도 어느 정도의 정보를 지닌 bag of words model 을 만들 수 있습니다. 황당하죠? 생각보다 성능이 좋습니다.
실험에 이용할 뉴스 기사는 위의 예제입니다. 저작권이 있으니 원문은 링크를 걸어뒀습니다. 이 기사의 어절들의 왼쪽의 2글자만을 subword 로 취했습니다. 길이가 1인 어절은 제외합니다. 박태환 이라는 하나의 개념은 ‘박태’ 라는 글자에 모였습니다.
[[ 박태=28 ]], 원장=14, 주사=11, 남성=10, 말했=10,
누나=10, 병원=9, 작년=7, 대해=6, 검찰=5,
간호=5, 문제=5, 했다=4, 측은=4, 몰랐=4,
알려=4, 밝혔=4, 질문=4, 도핑=4, 다른=3,
없다=3, 주치=3, 있다=3, 월에=3, 성분=3,
받았=3, 측이=3, 받는=3, 그런=3, 치료=3,
것으=3, 청문=3, 맞고=3, 모두=3, 되풀=3,
회원=3, 생각=3
이번에는 어절 왼쪽의 3글자를 subword 로 취하는 토크나이저를 적용합니다. 길이가 2 이하인 어절은 제외합니다. 박태환이라는 개념은 정확히 ‘박태환’ 이라는 feature 로 모였습니다. ‘남성호’ 라는 단어는 남성호르몬을 지칭합니다. 사람이 제대로 된 단어도 아닌 subwords frequency vector 로부터 문서의 내용을 유추할 수 있다면, 알고리즘 역시 이 subwords frequency vector 를 이용하여 문서 판별을 할 수 있습니다.
[[ 박태환=28 ]], 말했다=10, 남성호=10, 원장은=9, 간호사=5,
밝혔다=4, 누나가=4, 것으로=3, 누나는=3, 되풀이=3,
검찰에=3, 주치의=3, 청문회=3, 문제없=3, 병원에=3,
수차례=2, 것처럼=2, 주사를=2, 있다고=2, 대답했=2,
호르몬=2, 그리고=2, 마찬가=2, 알려졌=2, 고소하=2,
운동하=2, 프로그=2, 통보를=2, 치료를=2, 병원을=2,
질문을=2, 회원들=2, 내용을=2, 양성반=2, 소속사=2,
몰랐던=2, 변호사=2, 이야기=2, 했다고=2, 없다고=2,
받았다=2
길이가 2인 글자를 취할 때 ‘박태’의 빈도수는 28 이었습니다. ‘박태’는 ‘박태환’을 의미하는 feature 입니다. 하나의 개념이 하나의 feature 에 해당만 된다면 term frequency matrix 는 동일하게 만들어지기 때문에 토크나이저가 문장을 제대로된 단어로 자르지 못하더라도 성능이 많이 떨어지지 않습니다.
이 토크나이저는 다음의 상황에 유용합니다. 파일럿 실험으로 문서 군집화나 문서 판별을 빠르게 수행해야 합니다. 하지만 가지고 있는 품사 판별기, 형태소 분석기가 해당 데이터에 적합하지 않는데, 다행이도 띄어쓰기 기준으로 어절이 잘 구분될 때 이 토크나이저를 이용할 수 있습니다.
Experiments
실험에 이용할 데이터는 2016-10-20 의 30,091 건의 뉴스 기사 입니다. 뉴스는 띄어쓰기 기준으로 어절이 잘 나뉘어져 있기 때문에 left-side subword tokenizer 를 이용하기에 적합합니다. 코퍼스는 list of str (like) 형식입니다. 하나의 str 이 하나의 문서입니다. DoublespaceLineCorpus 는 From text to matrix post 에서 다뤘기 때문에 이를 참고해 주세요.
토크나이저는 간단히 만들었습니다. 길이가 n 이상인 어절에 대하여 어절 왼쪽의 길이가 n 인 substring 을 취했습니다.
from soynlp import DoublespaceLineCorpus
text_path = 'FILEPATH'
corpus = DoublespaceLineCorpus(text_path, iter_sent=False)
def subword_tokenizer(sent, n=3):
return [token[:n] for token in sent.split() if len(token) >= n]sklearn.feature_extraction.text.CountVectorizer 의 tokenizer 를 subword_tokenizer 로 바꿔줍니다.
2016-10-20 의 뉴스는 45Mb 크기의 문서입니다. 글을 쓰고 있는 맥북에어에서 vectorization 을 수행하였는데 4.1 초면 충분합니다. Substring 과 length 연산만 수행하기 때문입니다.
from sklearn.feature_extraction.text import CountVectorizer
vectorizer = CountVectorizer(tokenizer=subword_tokenizer)
x = vectorizer.fit_transform(corpus)x 와 vectorizer 를 이용하여 문서를 샘플링하고, (idx, weight) 리스트를 (vocab, weight) 형식으로 바꾸는 함수를 만듭니다. idx2vocab 은 vectorizer.vocabulary_ 의 items 를 value 기준으로 정렬한 list of str 입니다. get_bow(idx) 는 x 에서 idx 에 해당하는 row vector 를 가져옵니다. (idx, weight) 리스트를 만든 뒤, weight 의 크기 역순으로 정렬합니다. bow2doc(bow) 는 idx2vocab 을 이용하여 단어의 idx 를 vocab 으로 치환합니다.
idx2vocab = sorted(vectorizer.vocabulary_, key=lambda x:vectorizer.vocabulary_[x])
def get_bow(idx):
bow = x[idx,:]
bow = [(idx, bow[0,idx]) for idx in bow.nonzero()[1]]
bow = sorted(bow, key=lambda x:-x[1])
return bow
def bow2doc(bow):
return [(idx2vocab[idx], w) for idx, w in bow]
bow = get_bow(28969)
bow2doc(bow)샘플로 idx=28969 문서를 살펴보았습니다. 방탄소년단, 엠카운트다운 등의 아이돌 공연 관련 뉴스 문서입니다.
[('방탄소', 5),
('엠카운', 4),
('뉴스1', 2),
('자랑했', 2),
('출연했', 2),
('20일', 2),
('유수경', 1),
('노래다', 1),
('열창했', 1),
...
이 문서와 cosine distance 기준으로 가까운 다른 문서들을 찾습니다. sklearn.metrics.pairwise_distances 를 이용하여 문서 간 cosine distance 를 계산한 뒤, 거리 기준 정렬을 합니다.
from sklearn.metrics import pairwise_distances
dist = pairwise_distances(x, x[28969,:], metric='cosine')
closest = sorted(enumerate(dist.flatten()), key=lambda x:x[1])[:10]
for doc_idx, d in closest:
if doc_idx == 28969:
continue
bow = get_bow(doc_idx)
bow = bow2doc(bow)[:30]
bow = ' '.join([term for term, _ in bow])
print('\ndoc id = {}, cosine-dist = {:.3}\n{}'.format(doc_idx, d, bow))Query document 였던 doc_idx == 28969 를 제외한 문서들의 bag of words 입니다. 모두 음악방송 관련 문서들임을 알 수 있습니다. 이처럼 학습된 모델을 이용하지 않더라도 비슷한 문서를 찾는데 이용할 수 있는 토크나이저는 손쉽게 만들 수 있습니다.
doc id = 28947, cosine-dist = 0.334
몬스타 엠카운 20일 뉴스1 넘치는 다비치 레이디 맨스에 멤버들 무대를
무대에 방송됐 방송된 방출했 방탄소 백퍼센 빅브레 샤이니 선보였 선보이
신용재 아이오 에이핑 열창했 오블리 유수경 의상을 재배포 출연했 카리스
doc id = 16492, cosine-dist = 0.354
방탄소 다비치 엠카운 레이디 몬스타 샤이니 스포츠 아이오 에이핑 올랐다
10위 10일 1위에 20일 2관왕 5위를 감사를 갓세븐 걸그룹 공약으
공약했 귀여운 귀요미 그대인 김영록 누르고 두번째 드러냈 매력을 맨스에
doc id = 28966, cosine-dist = 0.373
아이오 엠카운 20일 뉴스1 출연했 과시했 귀여운 깜찍한 너무너 다비치
뒤흔들 레이디 마음을 매력을 맨스에 몬스타 몸짓이 무대를 물오른 미모와
방송된 방탄소 백퍼센 빅브레 상큼함 샤이니 선보였 신용재 에이핑 오블리
doc id = 28931, cosine-dist = 0.375
엠카운 20일 뉴스1 세븐은 세븐이 8개월 꾸몄다 노련미 녹슬지 다비치
레이디 매너와 맨스에 몬스타 무대를 발표한 방송됐 방송된 방탄소 백퍼센
빅브레 샤이니 선보였 성숙한 신용재 실력을 아이오 에이핑 오블리 유수경
doc id = 16485, cosine-dist = 0.381
다비치 방탄소 엠카운 스포츠 10일 13일 1위를 20일 갓세븐 그대인
김영록 대결로 레이디 맞대결 맞붙었 맨스에 몬스타 발표한 백퍼센 벌이게
빅브레 샤이니 신용재 아이오 압축됐 에이핑 오블리 월드돌 음원강 재배포
doc id = 9180, cosine-dist = 0.391
엠카운 방탄소 정국의 트위터 20일 갓세븐 게재됐 공개됐 공개된 곽경민
귀엽기 기사제 나라에 다비치 담겨져 대기실 덧붙였 따듯한 레이디 마음을
맨스에 모습이 몬스타 무단전 문화재 미소를 백퍼센 보도자 보이며 빅브레
doc id = 28982, cosine-dist = 0.394
1위를 방탄소 엠카운 남성미 뉴스1 다비치 몬스타 무대를 샤이니 아이오
에이핑 19일 1위에 1위의 20일 8개월 감성을 갓세븐 강렬해 과시했
끌었다노련미 돌아온 뒤흔들 레이디 마음을 맨스에 무대도 발표한 방송된
doc id = 21674, cosine-dist = 0.441
방탄소 다비치 무대에 엠카운 올랐다 무대를 샤이니 10위 갓세븐 그대인
뜨거운 레이디 몬스타 에이핑 타이틀 헤럴드 현장에 100 10월 1위를
1위에 1위의 20일 497 가창력 감사드 감사하 감성을 강렬한 결과가
doc id = 18072, cosine-dist = 0.453
엠카운 방탄소 공개했 대기실 원해많 피땀눈 100 13일 20일 6시부
갓세븐 게시물 고정하 기습적 나올거 다비치 댄투댄 뒤이어 디지털 레이디
멤버들 모습을 몬스타 무대부 방송될 백퍼센 변신한 봅시다 빅꿀잼 빅브레
Conclusion
어절의 왼쪽만 취해도 비슷한 문서를 찾는데는 쓸만한 토크나이징을 할 수 있습니다. 하지만 제대로된 단어가 아니기 때문에 해석은 어렵습니다. 또한 어절 왼쪽의 3 글자를 단어로 취하는 과정에서 길이가 2 이하인 단어들은 제외가 되었습니다. Subword 의 길이를 global parameter 로 이용하였기 때문입니다. 우리는 이런 문제들을 unsupervised word extraction methods 를 이용하여 해결하려 합니다.