Word embedding 은 단어의 의미정보를 벡터에 잘 반영함으로써 다양한 자연어처리 문제의 성능을 향상시켰습니다. Word2Vec 은 대표적인 word embedding 방법으로, Word2Vec 의 학습 과정에 대해서는 잘 알려져 있습니다. 이 포스트에서는 학습 방법을 넘어 Word2Vec 이 학습한 벡터 공간 자체를 살펴봅니다. 고차원 공간에 각 정보들이 어떤 형식으로 저장되어 있는지 알아봄으로써, word embedding 공간에 대한 이해를 높입니다. 이 포스트에는 All-but-the-top: simple and effective postprocessing for word representations (ICLR 2018) 의 리뷰 일부와 open questions 이 포함되어 있습니다.
Brief reviews of Word2Vec
Word2Vec 은 Softmax regression 을 이용하여 단어의 의미적 유사성을 보존하는 embedding space 를 학습합니다. 문맥이 유사한 (의미가 비슷한) 단어는 비슷한 벡터로 표현됩니다. ‘cat’ 과 ‘dog’ 의 벡터는 매우 높은 cosine similarity 를 지니지만, 이들은 ‘topic modeling’ 의 벡터와는 매우 작은 cosine similarity 를 지닙니다.
Word2Vec 은 softmax regression 을 이용하여 문장의 한 스냅샷에서 기준 단어의 앞/뒤에 등장하는 다른 단어들 (context words) 이 기준 단어를 예측하도록 classifier 를 학습합니다. 그 과정에서 단어의 embedding vectors 가 학습됩니다. Context vector 는 앞/뒤 단어들의 평균 임베딩 벡터 입니다. [a, little, cat, sit, on, the, table] 문장에서 context words [a, little, sit, on] 를 이용하여 cat 을 예측합니다.
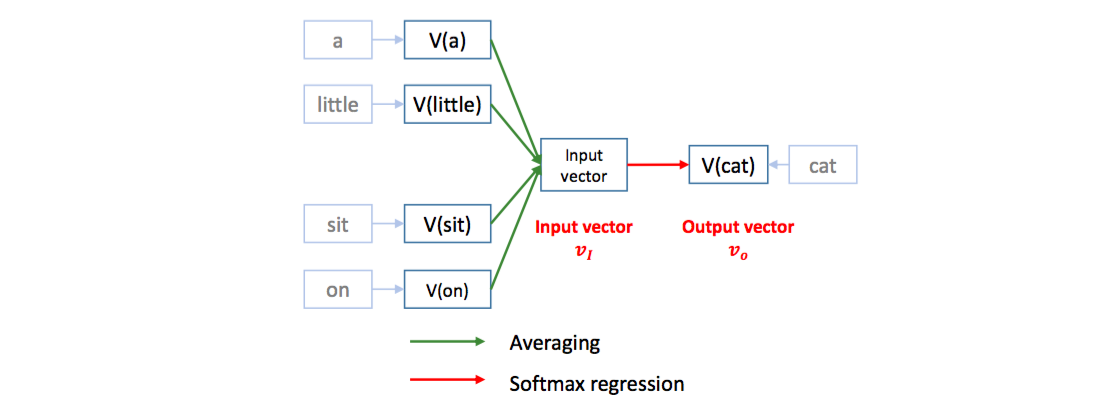
이는 cat 의 임베딩 벡터를 context words 의 평균 임베딩 벡터에 가깝도록 이동시키는 역할을 합니다. 비슷한 문맥을 지니는 dog 도 비슷한 context words 의 평균 임베딩 벡터에 가까워지기 때문에 cat 과 dog 의 벡터가 비슷해집니다.
Word2Vec 은 feed-forward neural language model (Bengio et al., 2003) 을 간소화 한 모델입니다. 불필요한 hidden layers 를 제거하고, concatenation 을 averaging 으로 바꿈으로써 모델이 학습해야 하는 벡터 공간의 크기를 줄였습니다. 하지만 본질이 langauge model 이기 때문에 softmax 는 그대로 유지하였습니다.
이외의 자세한 Word2Vec 의 설명은 이전 포스트를 참고하세요.
The neighbors of frequent words are frequent
Gensim 의 Word2Vec 을 이용하여 cosine similarity 기준 유사한 벡터를 검색합니다. 네이버의 영화 커멘트 데이터의 최소 빈도수 5 이상인 단어들을 학습한 Word2Vec 의 모델을 살펴봅니다. most_similar() 를 이용하여 비슷한 단어를 검색합니다. 단어 옆 괄호 안의 숫자는 질의어, 검색된 단어의 빈도수 입니다.
# Similar word search from Word2Vec model trained with movie comments
for word in '영화 관람객 재미 연기 관상 클로버필드'.split():
similars = word2vec_model.most_similar(word)영화의 유사 단어로 [애니, 애니메이션, 작품, 명화, 드라마, …] 가 학습되었습니다. ‘재미’ 역시 [재미, 잼, 잼미, …] 처럼 ‘funny’ 를 의미하는 단어와 오자들이 검색됩니다. ‘클로버필드’의 유사어들은 모두 영화 제목입니다. 또한 대부분 단어들이 최소 빈도수 5 보다 큰 빈도수를 보입니다.
| 영화 (1412516) | 관람객 (585858) | 재미 (344634) | 연기 (255673) | 관상 (988) | 클로버필드 (136) |
|---|---|---|---|---|---|
| 애니 (6075) | 굿굿 (14681) | 제미 (630) | 케미 (2257) | 광해 (4143) | 투모로우 (598) |
| 애니메이션 (7456) | 그치만 (1616) | 재이 (197) | 가창 (104) | 베를린 (2441) | 다이하드 (277) |
| 작품 (39544) | 이지만 (8276) | 잼이 (730) | 영상미 (11800) | 도둑들 (2954) | 쿵푸팬더 (94) |
| 명화 (708) | 유쾌하고 (2810) | 잼 (13098) | 목소리 (3489) | 역린 (1256) | 매트릭스 (928) |
| 드라마 (16306) | but (809) | 짜임새 (3739) | 캐미 (562) | 놈놈놈 (529) | 실미도 (337) |
| 에니메이션 (577) | 그러나 (9951) | 기다린보람이 (98) | 아역 (4463) | 부당거래 (676) | 헝거게임 (121) |
| 엉화 (126) | 듯하면서도 (72) | 잼미 (120) | 카리스마 (3034) | 과속스캔들 (850) | 레지던트이블 (199) |
| 수작 (5048) | 아주 (24571) | ㅈㅐ미 (27) | 노래 (24689) | 감시자들 (654) | 메트릭스 (121) |
| 양화 (164) | 다만 (9957) | 특색 (164) | 열연 (3326) | 전우치 (1863) | 분노의질주 (194) |
| 블록버스터 (5015) | 였지만 (5319) | 잼도 (39) | 배우 (139416) | 숨바꼭질 (470) | 새벽의저주 (215) |
그러나 infrequent words 의 유사어들은 유독 빈도수가 작습니다.
| 켄시로 (5) | 나우유씨 (5) | 클러버필드 (7) | 와일더 (5) |
|---|---|---|---|
| 클러버필드 (7) | 씨미 (47) | characters (5) | 짱예 (11) |
| 디오디오디오디오디오 (8) | 로보 (408) | 미라클잼 (5) | 생스터 (23) |
| 역스 (5) | 트레 (42) | 유월에 (5) | 룰라 (13) |
| qf (5) | 뱅 (13) | 디오디오디오디오디오 (8) | 존섹 (20) |
| 숨도못쉴만큼 (5) | 죤 (19) | 잡잡잡잡 (5) | 윌터너 (39) |
| 좋갯다 (5) | 썩시딩 (9) | 내꼬야 (5) | 이뻐이뻐 (16) |
| 구웃구웃 (9) | 니이이 (6) | qf (5) | 이뿌구 (13) |
| 굳ㅋ굳ㅋ굳ㅋ굳ㅋ굳ㅋ (5) | 피아 (469) | 굳굿굳굿굳 (5) | 77ㅑ (10) |
| 마니마니마니 (7) | 빠이 (50) | 애앰 (6) | 긔요미 (19) |
| 유월에 (5) | 합류하 (14) | romantic (5) | 세젤예 (5) |
혹시 한국어 데이터의 특징일까요? 이를 확인하기 위하여 Reuters 의 뉴스 기사를 이용하여 영어에 대해서도 테스트를 하였습니다. 토크나이저는 최대한 알파벳 기준으로 나뉠 수 있도록 간단하게 작성하였습니다.
import re
def tokenize(sent):
pattern = re.compile('[\"\s\'`!.?,]')
return pattern.sub(' ',sent).split()약 30 만개의 단어를 학습한 Word2Vec 모델에 빈번한 단어와 희귀한 단어의 유사어 검색을 수행하였습니다. 빈번한 단어의 유사어는 대부분 빈번합니다. lost 의 유사어로는 동사나 형용사가, point 의 유사어로는 명사, 특히 points 나 point; 와 같이 토크나이저에 의하여 잡히지 않았던 복수형 등이 retrieve 됩니다. Word2Vec 모델은 학습이 잘 되고 있습니다.
| offer (70274) | source (70065) | point (69646) | game (69570) | clear (69270) | lost (68763) |
|---|---|---|---|---|---|
| offering (35315) | sources (66331) | moment (19169) | games (34483) | sure (31732) | gained (28668) |
| bid (56866) | official (118857) | points (94945) | match (30192) | obvious (4959) | regained (2074) |
| purchase (20995) | person (36569) | juncture (650) | movie (27569) | unclear (15638) | dropped (36074) |
| proposal (37150) | aide (10990) | stage (31008) | tournament (18732) | surprising (5217) | slumped (5126) |
| buy (73425) | diplomat (12020) | point; (35) | format (3497) | true (13114) | plummeted (2188) |
| receive (22050) | banker (7946) | time (270178) | season (62459) | helpful (2757) | plunged (7605) |
| offers (16412) | staffer (834) | level (65495) | franchise (7941) | correct (5363) | tumbled (7720) |
| deal (208557) | matter (46652) | outset (1212) | lineup (3504) | clearly (16796) | surged (10280) |
| appeal (23098) | participant (1081) | least (99186) | comedy (9174) | wrong (15615) | soared (6401) |
| unsolicited (1427) | spokesperson (3471) | bhatt (11) | matchup (512) | question (34575) | climbed (12394) |
Rare words 는 rare 하여 어떤 의미인지는 모르겠습니다만, 사람 혹은 단체의 이름으로 짐작되는 단어들이 많습니다. 최소빈도수 5 에 가까운 단어들이 많이 등장함을 확인할 수 있습니다. 물론 Shellback 의 co-writer 나 Suchman 의 Screenwriters 처럼 최소빈도수보다 자주 등장한 단어가 유사어로 검색되기도 합니다.
| Shellback (5) | Reflektor (5) | Lazaretto (5) | Suchman (5) | Kissin (5) | Maccabees (5) |
|---|---|---|---|---|---|
| keyboardist (82) | naveen (5) | MINISERIES/TELEVISION (6) | Doctorow (29) | GAPEN (8) | ici (9) |
| Frideric (7) | Kaczorowski; (5) | Groupings (5) | Bub (7) | anup (6) | (Outside (7) |
| Chick (48) | com/gen92k (8) | Kinosis (5) | deWitt (6) | roy (6) | ET/GMT (17) |
| co-writer (146) | alonso (7) | Davis/Greg (5) | Ross: (11) | ASHWORTH (6) | CGC-12-520719 (27) |
| singer) (17) | Davis/Greg (5) | 2017-2027 (9) | Helfer (6) | samajpati (10) | GRIZZLIES (6) |
| Sings (15) | guttsman (5) | 09-md-02036 (11) | Swank: (14) | DETROIT/PARIS (10) | Government-Related (7) |
| Ralph: (5) | yoon (8) | Acquino (8) | Screenwriters: (27) | Maso (5) | Place/Paolo (5) |
| saxophonist (56) | LUZERNE (6) | SAUGUS (7) | Pittendrigh (6) | neetha (5) | emploi (7) |
| Menken; (5) | SKOLKOVO (6) | 13-900 (17) | producer/director (9) | 6386 (7) | Only) (10) |
| Amis (53) | 13-09173 (6) | 2017-2041 (6) | Manganiello (11) | 9202 (5) | (Brooklyn) (19) |
한국어와 영어의 Word2Vec embedding 학습 품질은 차이가 있는 걸까요? 어쩌면 토크나이저 때문일지도 모르겠습니다.
하지만 빈번한 단어들은 빈번한 단어끼리, 희귀한 단어들은 희귀한 단어끼리 cosine similarity 기준으로 비슷한 패턴은 두 데이터 모두 존재합니다.
Word2vec encodes word frequency as meaningful component?
17년 2월, arXiv 에 한 편의 논문이 올라왔습니다. All-but-the-top: simple and effective postprocessing for word representations (ICLR 2018) 은 word embedding 모델에 의하여 학습된 embedding space 에는 많은 단어들이 공유하는 components 가 존재하고, 이때문에 벡터 공간이 isotropic 하지 않다고 주장합니다. 그리고 단어들이 공유하는 common components 를 제거함으로써 유사어 검색과 같은 NLP tasks 의 성능을 향상할 수 있다고 주장합니다.
Isotropic 은 벡터 공간의 성질에 대한 수학 용어입니다. 우리가 아는 isotropic 한 공간은 2차원에서 원점을 중심으로 하는 동그란 원입니다. 원을 바라보는 시점이 달라도 원의 모양이 같습니다. 하지만 중심이 (1,0) 인 찌그러진 타원이라면 그 타원을 바라보는 위치마다 타원의 모양이 다릅니다. 이 타원의 중심을 평행이동하고 찌그러진 긴 축의 성분들을 제거하면 원에 가깝게 됩니다. 이 논문은 isotropic 의 의미 정도만 집고 넘어가도 됩니다.
한 공간이 isotropic 인지 확인하기 위하여 이 논문에서는 Principal Component Analysis (PCA) 를 수행합니다. PCA 는 벡터 공간의 회전변환입니다. 100 차원의 벡터에서 학습된 10 개의 principal components 만을 선택하는 것은 여러 개의 축이 함께 설명하는 하나의 component 가 있을 때, 이를 하나의 축으로 설명하기 위함입니다. 그렇다 하더라도 일단 PCA 는 본래 공간에 대한 회전변환을 합니다. Wikipedia 의 PCA 페이지에 있는 아래 그림처럼 2 차원의 데이터에 대한 PCA 모델을 학습하면 2 개의 축을 얻습니다. 데이터의 분포가 타원에 가깝다면 각 component 의 variance 가 다릅니다. 널리 퍼져있는 축과 오밀조밀하게 모여있는 축이 존재합니다.

이 논문에서는 300 차원으로 학습되어 공개된 Word2Vec, GloVe, 그 외의 word embedding 방법들을 이용하였습니다. 300 차원의 embedding vectors 에 대하여 PCA 를 학습한 뒤, 각 차원의 variance ratio 에 대한 plot 을 그렸습니다. Variance ratio 는 전체 variance 에 대하여 각 component 가 차지하는 비율입니다. PCA 모델의 \(\lambda\) 의 상대크기입니다. 일정하지 않은 variance ratio 는 공간이 찌그러진 타원 형태임을 의미합니다. 다른 말로는 벡터들이 공유하는 components 가 존재합니다.
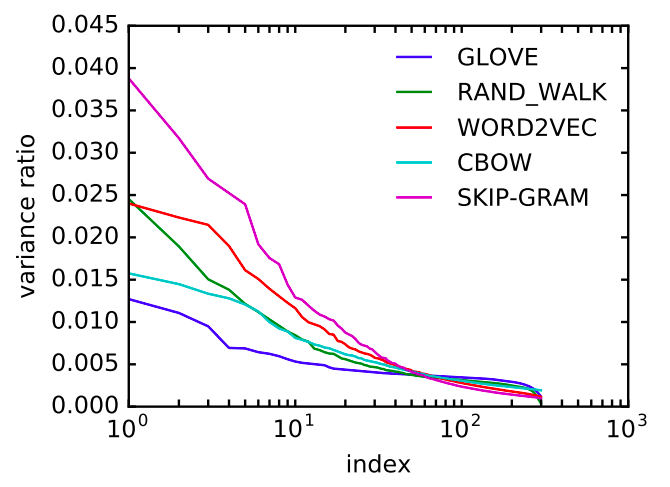
데이터의 평균 벡터도 원점이 아닙니다. \(avg. \lVert v(w) \rVert_2\) 와 \(\lVert \mu \rVert_2\) 의 비율이 0.2 ~ 0.5 에 가깝습니다. 원점이 중심이 아닌 타원일 가능성이 점점 더 높아집니다.
PC1 과 PC2 를 각각 \((x, y)\) 축으로 scatter plot 을 그렸습니다. 색은 단어의 빈도수 입니다. Word2Vec 구조인 skip-gram 과 CBOW 는 원점 근처에 frequent words 들이 몰려있고, rare words 들이 흩뿌려져 있습니다. GloVe 도 원점에 frequent words 들이 몰려있지만, 그 모양이 찌그러진 타원은 아닙니다.
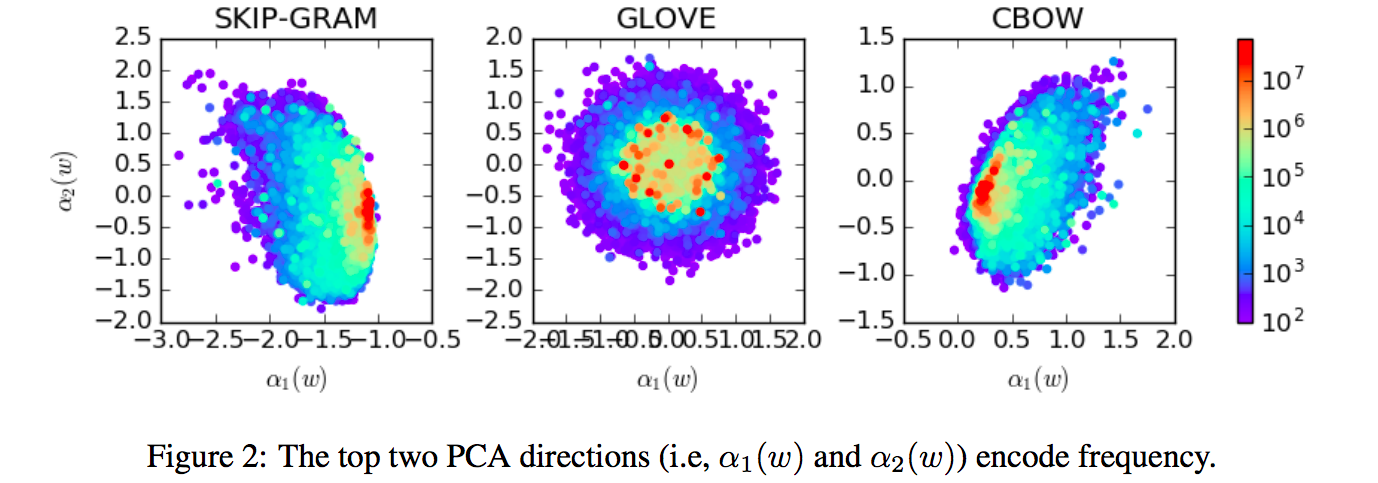
그러나 공통적으로 단어의 빈도수에 관련된 정보가 PC1, PC2 에 존재합니다. 비슷한 문맥의 단어를 검색하기 위해서는 문맥 정보만 있어도 됩니다. 그러나 word embedding 알고리즘들은 단어의 빈도수 정보까지 모두 학습을 하였습니다. 논문은 이 정보를 제거하면 word embedding space 에 semantic information 만 남을 수 있고, 그렇기 때문에 NLP tasks 의 성능이 향상된다고 주장합니다.
이를 위한 후처리 (post-processing) 방법도 제안하였습니다. PCA 를 학습한 뒤, top \(d\) 개의 components 를 제거합니다. Top principal components 가 여러 단어들이 공유하는 common components 라 생각하였습니다. \(d\) 는 embedding space 차원의 1/100 정도면 충분하다고 적혀있습니다.

My assumption
저도 Word2Vec 이 학습한 공간은 단어의 빈도수에 관련된 정보가 뚜렷한 패턴으로 학습된다고 생각합니다. ‘The neighbors of frequent words are frequent’ 에서 이를 확인하였습니다. 하지만 공간의 모습은 다르게 상상하고 있습니다. 상상인 이유는 “고차원의 공간의 구조를 잘 반영하며 2 차원의 벡터로 확인할 수 있는 편한 차원 축소 방법”을 찾지 못했기 때문입니다.
제가 생각하는 Word2Vec 의 공간은 아래와 같습니다. 전체 공간의 대부분은 frequent words 들이 semantic information 을 저장하는데 이용합니다. cat 과 dog 처럼 자주 등장하는 단어들은 넓은 공간에서 문맥을 반영하여 위치합니다. 그리고 cat 은 athlete 문맥이 다르기 때문에 많이 떨어져 있습니다. 하지만 infrequent words 들은 아주 작은 공간에 빽빽하게 몰려있습니다. 그 공간 안에서도 semantic information 이 녹아 있을 수는 있지만, 좁은 공간에 너무 많은 단어를 몰아넣어 그 패턴이 잘 보이지 않을 거라 상상합니다.

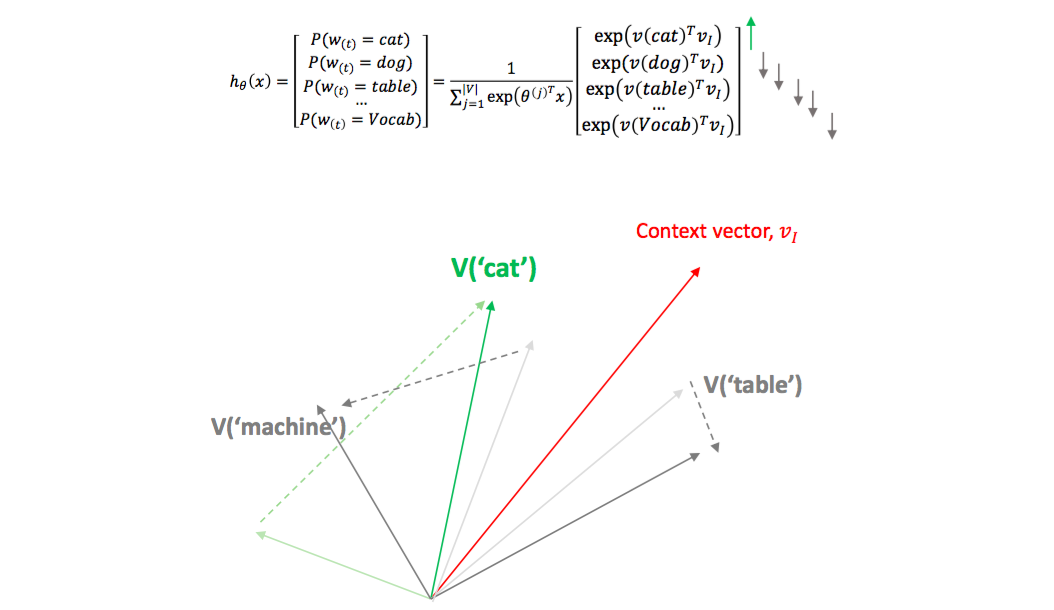
이런 생각의 근거는 Word2Vec 이 학습을 위하여 softmax regression 을 이용하기 때문입니다. 아래 식을 만족시키기 위해서는 frequent \(w_t\) 는 충분히 큰 값을 지녀야 합니다. 다른 frequent words 들과 멀리 떨어져 있어야 합니다. Softmax regression 은 두 단어 벡터의 내적에 exponential 을 취합니다. 내적이 0 보다 작은, 90 도 이상 떨어진 두 단어는 일단 다른 단어처럼 보입니다. 그래서 frequent words 들은 넓은 공간에 골고루 퍼져있습니다.
Infrequent words 들은 \(w_t\) 의 확률값이 매우 작아야 합니다. \(w_c\) 의 문맥에서 등장할 확률이니까요. Frequent words 들이 context words 일 가능성이 높습니다. 이 단어들과 멀리 떨어지면 아래의 softmax 식에 매우 잘 맞습니다. 그렇다면 infrequent words 들을 어느 작은 공간에 모두 몰아넣어도 될 것입니다. Infrequent words 의 semantic 을 고려하지 않는다는 점은 속상하지만, Word2Vec 의 시작은 language model 입니다. 그 입장에서는 frequent words 에 집중하는 것이 당연합니다.
\[P(w_t \vert w_c) = \frac{exp(w_t^T w_c)}{\sum_{w \in V} exp(w^T w_c) }\]
그래서 (Mu et al., 2017) 의 논문이 잘 이해되지 않았습니다. Infrequent words 가 좁은 공간안에 몰려있다면 이들이 (PC1, PC2) 의 scatter plot 에서 원점이 위치해야 하기 때문입니다. 이를 확인하기 위하여 논문과 같이 scatter plot 을 그려봤습니다. 아래 그림은 네이버 영화평과 Reuters 의 Word2Vec 학습 결과에 대한 (PC1, PC2)의 scatter plot 입니다. 색이 진할수록 infrequent 합니다. 한국어 데이터에 대해서는 infrequent words 들이 원점이 몰려있습니다.
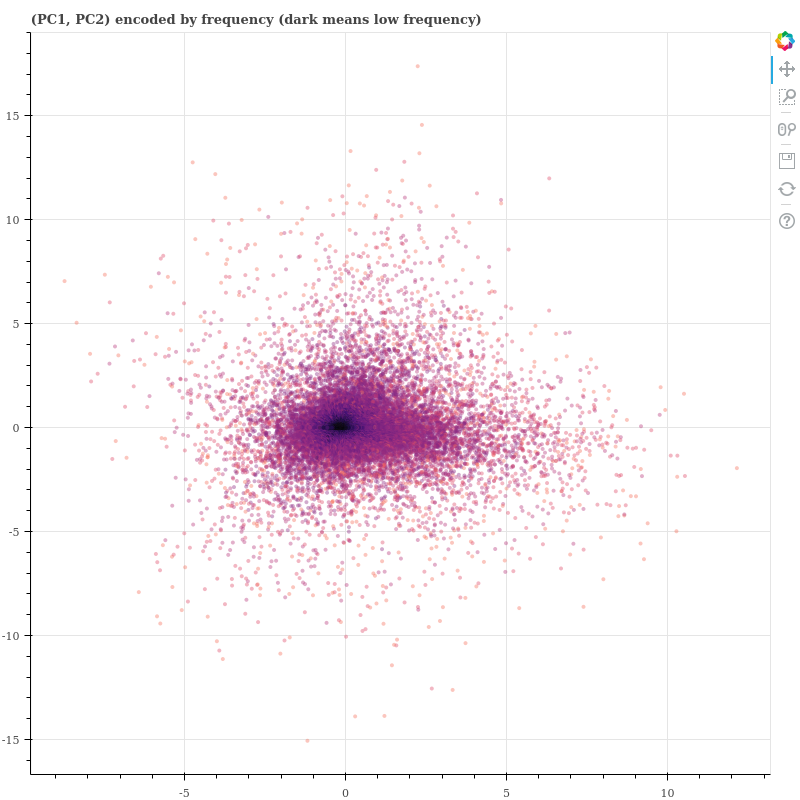
Retuers 에서도 패턴은 마찬가지입니다. 이는 논문과 정 반대의 패턴입니다. 논문에서는 frequent words 가 원점 근처에 위치하였습니다. 왜일까요? 며칠간 멘붕에 빠졌습니다. 공간을 확인하고 싶어도 제 목적에 쓸만한 2 차원 임베딩 방법을 찾지 못했습니다.
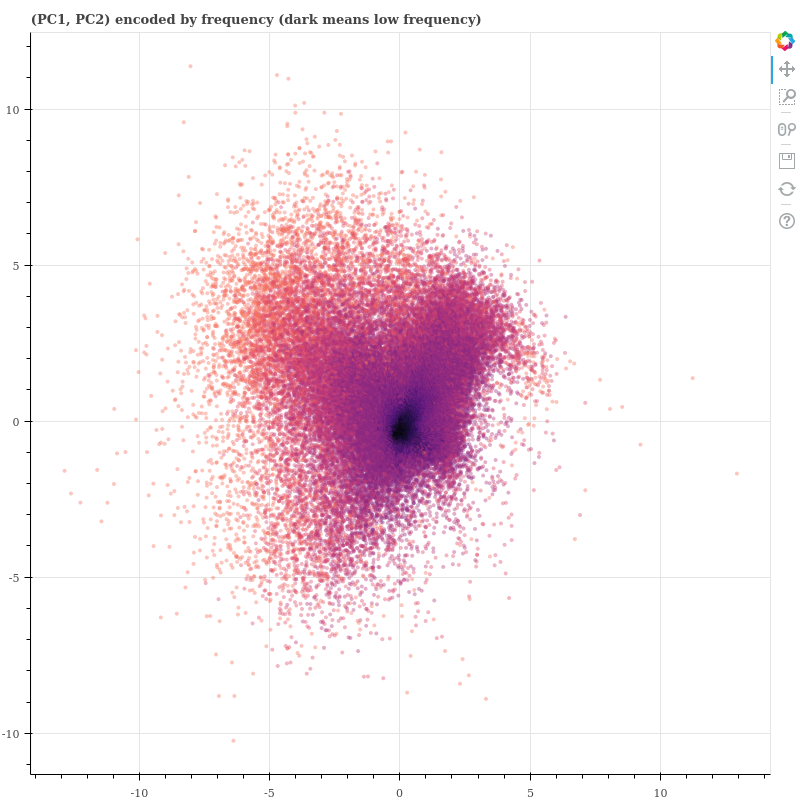
Common components 는 존재합니다. 각 components 별 variance ratio 는 분명 다릅니다. 저는 100 차원의 word embedding space 를 이용했기 때문에 x-axis 의 scale 은 다릅니다.
혹시나 하는 마음에 windows 과 iterations 모두 다르게 설정하고서 학습하였지만 그 패턴은 같았습니다. 제 가설대로라면 학습이 immature 한 것만 아니라면 windows 나 iterations 은 영향이 없습니다.
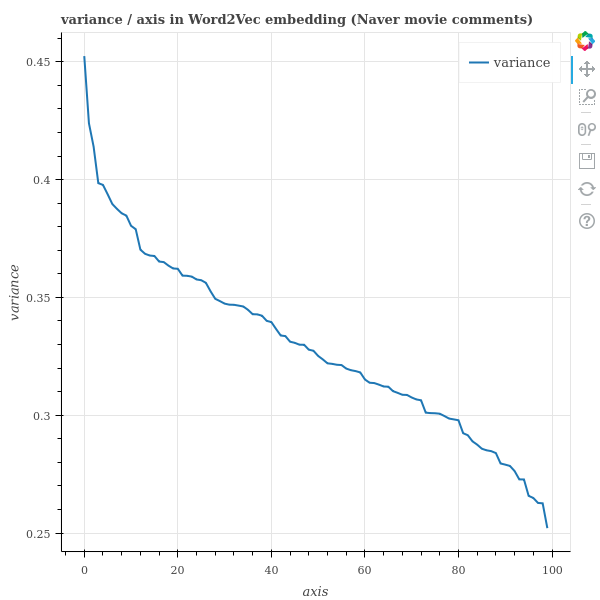
학습된 principal common components 에는 단어의 semantics 뿐만 아니라 frequency 에 대한 정보도 어느 정도 포함되어 있습니다. 그리고 principal components 의 semantics 은 infrequent words 을 설명하는 정보는 아닐 가능성이 높습니다. 그래야 infrequent words 들이 원점에 몰려 있을 수 있기 때문입니다.
논문이 재현이 안되는 정도가 아니라, 패턴이 반대로 나와서 당황하였습니다. 저는 Gensim version 3.1 의 Word2Vec 을 이용하였습니다. Pre-trained 벡터를 가져와서 다시 확인해야 할 상황입니다. 일단은 그 벡터들을 가져와서 직접 PCA plot 을 그리는게 가장 먼저 할 일이겠네요.
Open questions
How to project embedding vector to 2-D, preserving density of original space?
고차원 공간을 2 차원으로 변환하는 시각화 방법들은 많습니다. Locally Linear Embedding (LLE), ISOMAP, t-SNE 와 같은 방법들은 고차원의 벡터를 저차원의 벡터로 압축할 수 있기 때문에 데이터 시각화에 자주 이용됩니다. 고차원에서 저차원으로 차원을 줄이다보면 잃어버리는 정보가 있습니다. 큰 집에서 작은 집으로 이사하니 버릴 짐들이 생깁니다. 각 알고리즘들은 보존하고 싶은 정보들이 다릅니다. 하지만 세 가지 알고리즘 모두 본래 공간의 neighbor structure 를 보존합니다. 고차원에서 가까운 이웃이었다면 저차원에서도 가까운 이웃이도록 차원을 변환합니다. 그러나 고차원의 밀도 정보가 보존되지는 않습니다. 서로 떨어진 거리가 달라도 됩니다. 위 알고리즘들이 보존하는 정보는 점들간의 가까운 순서이지, 얼마나 가까운지에 대한 거리가 아닙니다.
Multi-Dimensional Scaling (MDS) 는 점들 간의 거리를 보존하는 2 차원 전사 (projection) 방법입니다만, MDS 는 모든 점들 간의 pairwise distance 를 고려합니다. 문제는 고차원에서는 closer 는 의미가 있지만, distant 는 큰 의미가 없습니다. 거리가 멀다라는 말은 정보가 없습니다. 그래서 모든 점들 간의 pairwise distance 를 고려하면 엉뚱한 정보를 보존하게 됩니다.
아직까지는 고차원 공간의 밀도를 반영하며 2 차원으로 공간을 압축하는 방법을 찾지 못했습니다. Kernel PCA 는 그나마 잘 될것 같았지만, kernel matrix 계산을 위하여 \(n^2\) 의 메모리 공간을 요구합니다. 제 실험환경에서는 30 만 단어의 kernel matrix 를 계산하지 못했습니다.
이 문제는 더 고민해야겠습니다.
Word2Vec can capture semantics even if the words are infrequent?
Scatter plot 에서 반대의 패턴이 보여 post-processing 은 실험을 하지 않았습니다. 하지만 앞서 관찰한 결과에서도 infrequent words 의 semantic 이 잘 학습되지 않는 모습을 볼 수 있습니다. 이러한 현상의 근본적인 이유는 애초에 Word2Vec 은 infrequent words 에 대해서는 크게 관심이 없는 모델이기 때문이라 생각합니다. 하지만 몇 번 등장한 단어라 하더라도 문맥은 존재합니다. 이런 rare words 의 문맥을 잘 보존할 수 있는 방법은 없을까요?
Reference
- Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C. (2003). A neural probabilistic language model. Journal of machine learning research, 3(Feb), 1137-1155.
- Mu, J., Bhat, S., & Viswanath, P. (2017). All-but-the-top: simple and effective postprocessing for word representations. arXiv preprint arXiv:1702.01417.