다양한 언어에서 미등록 단어를 데이터 기반으로 추출하려는 시도가 있었습니다. 중국어와 일본어는 띄어쓰기를 이용하지 않는 언어입니다. 자연어처리를 위해서는 문장에서 단어열을 인식해야 합니다. 이 문제를 word segmentation 이라 합니다. 중국어와 일본어는 한자어를 이용하는 표의문자이기 때문에 미등록단어를 알지 못하면 제대로된 segmentation 을 할 수 없습니다. 이를 해결하기 위하여 통계 기반으로 미등록 단어를 인식하기 위한 방법이 제안되었습니다. Accessor Variety 와 Branching Entropy 는 언어학자 Zelling Harris 의 단어 경계에 대한 가정을 직관적인 statistics 로 디자인한 단어 추출 기법입니다.
Out of vocabulary problem
말은 언제나 변화합니다. 새로운 개념을 설명하기 위해 새로운 단어가 만들어지기 때문에 모든 단어를 포함하는 사전은 존재할 수 없습니다. 학습데이터를 이용하는 supervised algorithms 은 가르쳐주지 않은 단어를 인식하기가 어렵습니다.
KoNLPy 의 트위터 한국어 분석기를 이용하여 아래 문장을 분석합니다.
from konlpy.tag import Twitter
twitter = Twitter()
twitter.pos('너무너무너무는 아이오아이의 노래입니다')사전에 등제되지 않은 ‘너무너무너무’와 ‘아이오아이’는 형태소 분석이 제대로 이뤄지지 않습니다.
[('너무', 'Noun'),
('너무', 'Noun'),
('너무', 'Noun'),
('는', 'Josa'),
('아이오', 'Noun'),
('아이', 'Noun'),
('의', 'Josa'),
('노래', 'Noun'),
('입니', 'Adjective'),
('다', 'Eomi')]
이는 한국어만의 문제가 아닙니다. 많은 언어에서는 새로운 개념을 표현하기 위하여 새로운 단어가 만들어집니다. 혹은 같은 시대의 한국어라 하더라도 뉴스 도메인에서 학습한 자연어처리기로 대화체 텍스트 데이터를 분석할 수는 없습니다. 쓰는 어휘가 다르기 때문입니다. 이처럼 미등록 단어 문제는 언제나 발생합니다. 통계 기반 단어 추출 기법은 ‘우리가 분석하려는 데이터에서 최대한 단어를 인식’하여 학습데이터를 기반으로 하는 supervised approach 를 보완하기 위한 방법입니다.
Uncertainty in Word Boundary
통계 기반 단어 추출 방법들을 살펴보면 언어학자인 Zellig Harris 의 직관이 자주 인용됩니다.
단어 혹은 형태소의 경계에서는 다른 단어나 형태소가 등장하기 때문에, 그 경계에서의 불확실성이 높다는 의미입니다. 쉽게 말하면, ‘자연어처’ 오른쪽에 등장할 글자는 예측하기 쉽습니다. 아마도 ‘자연어처리’를 떠올렸을 겁니다. 하지만 ‘자연어처리’ 오른쪽에 등장할 글자는 다양하기 때문에 어떤 단어가 등장한다고 쉽게 예상할 수 없습니다. 단어의 반대 방향에서도 위의 문장은 성립합니다. ‘연어처리’ 앞에 등장할 글자는 ‘자’임을 쉽게 예상할 수 있지만, ‘자연어처리’ 앞에 등장할 단어를 예상하기는 어렵습니다. 이처럼 단어나 형태소의 경계에서는 다양한 글자가 등장합니다. 다음 글자에 대한 불확실성이 커집니다.
아래의 그림에서 n, na 오른쪽에 등장할 글자가 매우 다양하기 때문에 불확실성이 큽니다. 그러나 natur 다음에 등장할 글자는 -e 아니면 -al 의 a 임을 짐작할 수 있습니다.
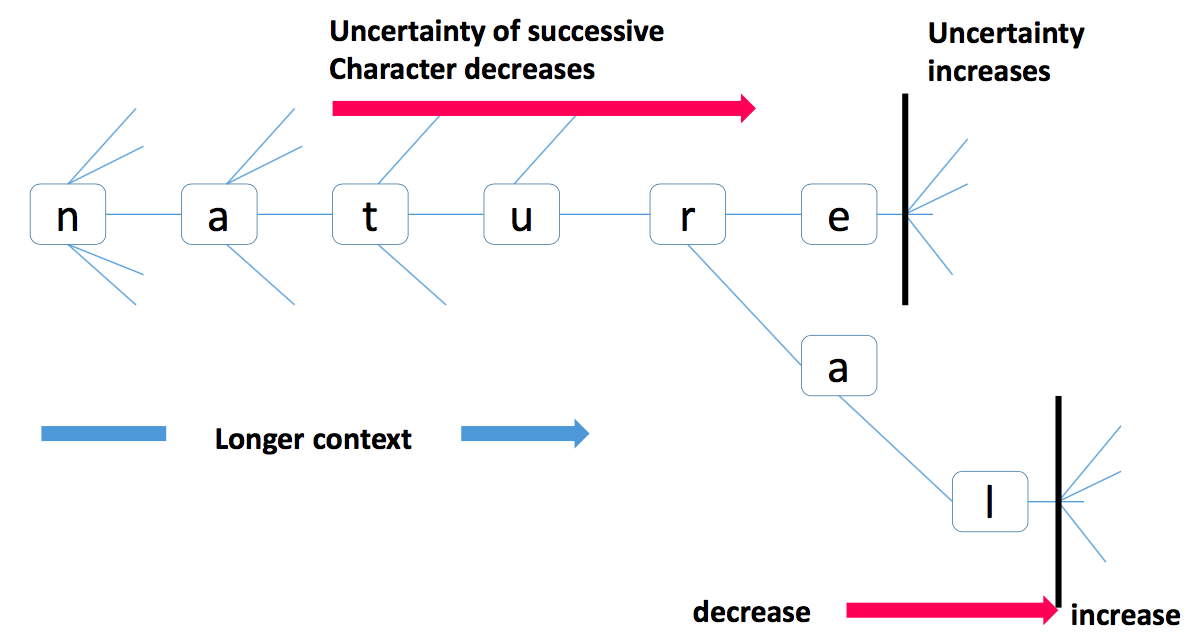
Accessor Variety 와 Branching Entropy 는 위와 같은 단어 경계에서의 불확실성을 각각 다른 방식으로 정의하며 단어의 경계를 찾습니다. 단어의 경계를 찾을 수 있다면, 그 지점을 나눔으로써 단어를 구분할 수 있기 때문입니다.
Accessor Variety 와 Branching Entropy 는 중국어와 일본어의 word segmentation 문제에 자주 이용되었습니다. 본래 두 나라의 언어는 띄어쓰기 없이 단어를 나열합니다. 영어의 알파벳이나 한국어에서 자주 쓰이는 글자보다도 훨씬 많은 수의 글자를 이용하기 때문에 (약 7000 자) 글자의 모호성도 영어나 한국어보다 작습니다. 그렇기 때문에 문장에서 word segmentation 만 하여도 품사 판별과 같은 과정이 거의 끝납니다 (모호성이 적으니까요).
Accessor Variety
Accessor Variety 는 2004 년에 제안된 방법입니다. Harris 의 단어 경계에서의 불확실성을 단어 경계 다음에 등장한 글자의 종류로 정의하였습니다. 아래 예시에서 ‘공연’ 오른쪽에 세 종류의 글자가 등장하였기 때문에 right-side accessor variety, \((av_r)\) 는 3 입니다.
공연은 : 30
공연을 : 20
공연이 : 50
반대로 ‘공연’의 왼쪽에 등장한 글자는 {번, 해} 이기 때문에 left-side accessor variety, \((av_l)\) 는 2 입니다.
이번공연 : 30
저번공연 : 20
올해공연 : 50
이번, 저번, 올해 처럼 세 종류의 단어가 등장하였는데 단어가 아닌 글자의 종류만을 이용하는 것은, 이 방법이 중국어의 word segmentation 을 해결하기 위하여 제안된 방법이기 때문입니다. 한국어에는 일부 띄어쓰기 정보가 포함되어 있기도 하지만 중국어는 띄어쓰기가 전혀 없습니다. 그리고 앞서 언급한 것처럼 중국어 글자의 모호성은 한국어 글자의 모호성보다 훨씬 적습니다. 글자의 종류만 고려하여도 됩니다.
단어 가능성 점수는 두 방향의 accessor variety 의 최소값으로 정의됩니다. 한쪽의 variety 가 작다면 이는 단어의 substring 이란 의미이기 때문입니다.
\[AV(s) = min(av_l(s), av_r(s))\]이 논문에서는 accessor variety value 에 threshold cutting 을 수행하여 단어를 추출하고, 해당 단어가 실제 단어인지를 확인하였습니다. 단어의 길이가 길더라도 추출이 잘 되며, threshold 는 어느 정도 이상으로 높여야함을 볼 수 있습니다.
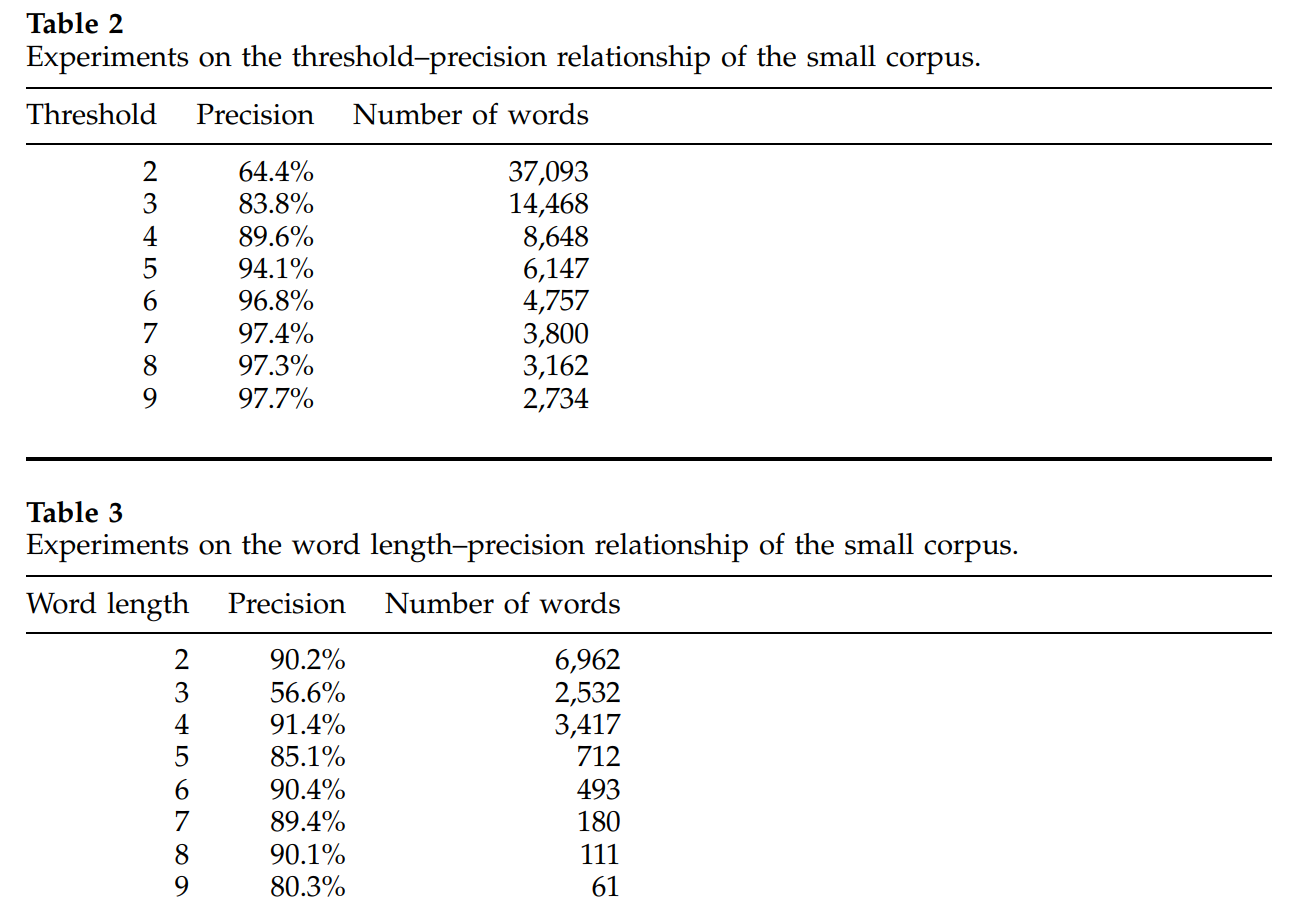
Threshold 에 universial parameter 는 없습니다. Threshold 는 corpus 의 크기에 따라 상대적으로 다르기 때문에 몇 번의 try & error 로 조절합니다.
Chinese word segmentation using Accessor Variety
Accessor Variety 를 이용한 unsupervised chinese word segmentation 방법은 같은 해에 동일한 저자인 Feng 에 의하여 제안되었습니다. 길이가 n 인 문장의 segmentation points 는 n-1 개 이며, 각각 [0, 1] 을 부여하는 labeling 문제입니다. 총 \(2^{n-1}\) 개의 solutions 중에서 가장 적절한 solution 을 찾는 문제입니다. 모든 solutions 중에서 best solution 을 찾는 것은 많은 비용이 들기 때문에 효율적으로 최선의 solution 을 찾는 많은 heuristics 이 제안되었습니다. Feng 의 segmentation algorithm 도 이에 해당합니다.
혹은 Conditional Random Field (CRF) 와 같은 sequential labeling 방법들도 이용될 수 있습니다. 상하이 교통대학의 Hai Zhao 는 unsupervised chinese word segmentation 에 대한 연구를 하셨던 분이며, CRF 를 많이 이용하였습니다. 그리고 supervised algorithm 인 CRF 에 out of vocabulary 를 인식하는 능력을 부여하기 위하여 accessor variety 를 함께 이용하기도 했습니다. 이 분야에 관심이 있는 분이라면 Zhao 의 연구를 살펴보시길 바랍니다 (저는 이 분 연구의 팬입니다).
다시 Feng 의 Accessor Variety 를 이용한 unsupervised word segmentation 으로 돌아옵니다. 풀어야 하는 문제는 문장 \(S\) 가 있을 때 이를 substrings 인 \(SS\) 로 나누는 것입니다. \(m \le n\) 입니다. Unsupervised segmentation of Chinese corpus using accessor variety 에서 제안된 방법은 \(SS\) 에 대한 criteria 와, 이를 찾기 위한 dynamic programming 기반 알고리즘입니다.
\(SS\) 에 대한 criteria 는 몇 개의 functions 입니다. \(\vert W \vert\) 는 단어 \(W\) 의 길이입니다. \(b, c, d\) 는 integer user configuration parameters 입니다.
사용자가 알아서 설정하는 임의의 parameters 이지만, 말은 됩니다. \(AV(W)\) 의 값이 클수록 단어일 가능성이 높습니다. \(\vert W \vert ^d\) 를 곱함으로써, 이왕이면 더 긴 단어가 선택되기를 장려합니다. Unsupervised approach 는 정확한 학습데이터가 없기 때문에, 알고리즘을 설계하는 사람이 옳다고 믿는 방향으로 solutions 을 유도해야 합니다.
Dynamic programming 기반 segmentation algorithm 은 아래와 같습니다. 단어의 최대 길이는 6 이라 가정한 뒤, i 를 1 씩 증가하며 best solusions 을 찾아갑니다.
- initialize: \(f_0 = 0\)
- initialize: \(f_1 = f(W_{11} = C_1)\)
- repeat: \(f_i = max_{1 \le j \le min(i, 6)} \left (f_{i-j}^{`} + f(W_{ij}) \right), 2 \le i \le n\)
- finally: \(f(S) = f_n\)
위 방법을 한국어 데이터에 적용해보지는 않았습니다. Accessor Variety 는 그 자체가 단어 추출 용으로 한국어에서도 잘 작동합니다. 알고리즘을 만들면 이 포스트를 업데이트 하겠습니다.
Branching Entropy
Branching Entropy 는 Jin and Tanaka-Ishii (2006)이 제안한 방법으로 Accessor Variety 와 거의 비슷합니다. Accessor Variety 는 단어의 앞 뒤에 등장하는 글자의 종류를 불확실성으로 이용하였습니다. Branching Entropy 는 entropy 를 불확실성의 정보로 이용합니다. 아래의 예제에서 ‘공연’의 right-side accessor variety 는 3 입니다. ‘손나은’의 오자로 ‘손나응, 손나으’가 적혔었다면 ‘손나’의 right-side accessor variety 는 3 입니다. 하지만, ‘손나’ 오른쪽에 대부분 ‘-은’ 이 등장하였기 때문에 ‘손나’ 보다는 ‘손나은’이 더 단어스럽습니다.
공연은 : 30
공연을 : 20
공연이 : 50
손나은 : 98
손나응 : 1
손나으 : 1
Branching Entropy 는 Accessor Variety 가 이용하는 글자 종류보다도 글자 빈도의 분포가 단어의 경계를 나타나는 더 좋은 정보라 판단하였습니다. Entropy 는 확률분포의 불확실성입니다.
‘손나’의 오른쪽에 등장할 글자는 명확하기 때문에 entropy 가 작습니다. 불확실성이 작습니다. 반대로 ‘공연’의 오른쪽에 등장할 글자는 다양하여 entropy, 불확실성이 높습니다.
\(entropy(손나) = - \left( 0.98 * log(0.98) + 0.01 * log(0.01) + 0.01 * log(0.01) \right) = 0.11\) \(entropy(공연) = - \left( 0.3 * log(0.3) + 0.2 * log(0.2) + 0.5 * log(0.5) \right) = 1.03\)
이처럼 글자 종류의 절대값이 아닌 분포를 이용함으로써 좀 더 정밀하게 단어 경계 점수를 수치로 표현할 수 있습니다.
이 방법은 단어의 좌/우에 대하여 모두 적용할 수 있습니다. 이런 정보들은 tokenizer 의 재료입니다. 토크나이저의 목적은 주어진 문장/어절에서 단어를 분리하는 것입니다. 아래 그림처럼 한 경계를 마주하는 두 단어의 right / left side branching entropy 의 값이 모두 높다면, 이 부분은 단어의 경계일 가능성이 높습니다.

Japanese word segmentation using Branching Entropy
Branching Entropy 의 논문에는 이를 이용한 word segmentation 방법이 함께 제안되었습니다. 물론 heuristic 이기 때문에 Feng 의 Accessor Variety based segmentation algorithms 에 Branching Entropy 를 이용하여도 됩니다. 이 방법은 하나의 segmentation heuristic 입니다.
이 논문에서는 두 가지 경우를 단어의 경계점 (word boundary points) 로 선택합니다. 첫번째 경우는 그림의 윗 subplot 처럼 \(x_{0:4}, x_{4:8}\) 의 두 단어로 문장이 이뤄진 경우입니다. 단어의 경계에 가까워질수록 entropy 는 감소하고, 단어의 경계에서 entropy 는 증가합니다. 문장에서 entropy 가 가장 높은 지점을 선택하면 \(x_{0:8}\) 을 \(x_{0:4}, x_{4:8}\) 로 자를 수 있습니다. 이 기준을 \(B_{max}\) 라 명합니다.
단, entropy \(h(x_{i:k})\) 는 길이가 2 이상인 substring 에 대해서만 계산합니다. 아래 그림에서도 \(h(x_{0,1})\) 은 가장 큽니다. 한 글자는 context 를 지니기 어렵습니다. 이는 중국어나 한국어 모두에 해당합니다.
그러면 그림 아래의 subplot 처럼 \(x_{0:4}, x_{4:5}, x_{5:8}\) 과 같은 길이가 1 인 유닛이 들어있는 경우는 단어를 자르지 못합니다. ‘단어 + 의’ 처럼 조사같은 suffix 들이 이에 해당합니다. 그런데 \(x_{4:5}\) 가 suffix 역할을 한다면, \(x_{0:4}\) 와 \(x_{0:5}\) 는 계속하여 entropy 가 증가합니다. ‘단어의’ 라는 어절 다음에 많은 글자들이 등장하기 때문입니다. 이처럼 한글자를 더하여 entropy 가 증가하는 경우에는 \(4, 5\) 모두 boundary points 로 선택합니다.
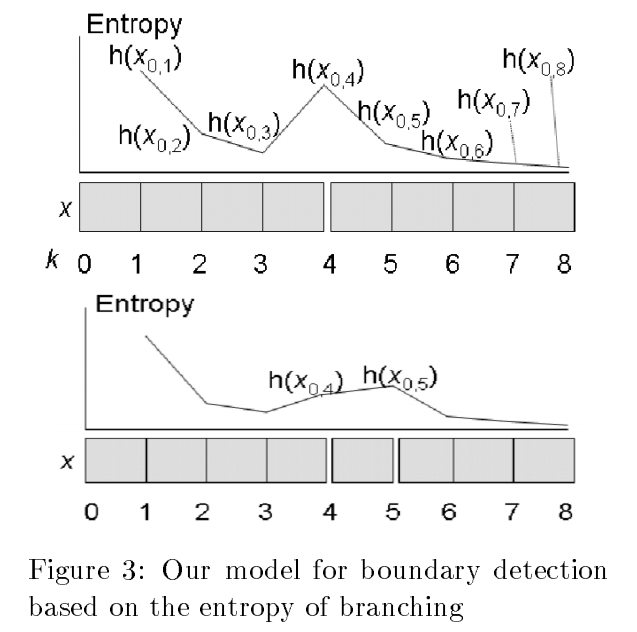
그런데 문장의 길이가 길면 \(h(x_{0:k})\) 가 없을 수도 있습니다. \(k=10\) 이 되면 몇 개의 단어가 연속으로 등장한 구 (phrase) 입니다. 그러나 데이터가 충분하여 \(h(x_{0:k})\) 가 크다면 \(h(x_{i:k})\) 도 큽니다. 이 논문에서도 최대 길이를 6 으로 이용하였습니다.
이를 정리하면 boundary points 규칙은 다음과 같습니다. 아래 규칙 중 \(valmax, valdelta, val\) 은 모두 사용자 정의 모델 페러메터 입니다.
- \(B_{max}\) : \(h(x_n)\) is local maximum and \(h(x_n) > valmax\)
- \(B_{increase}\) : \(h(x_{n+1}) - h(x_n) > valdelta\)
- \(B_{ordinary}\) : \(h(x_n) > val\)
사실 이 spec 만 이용하면 구현이 완벽히 되지 않습니다. \(h(x_{i:k})\) 의 \(i\) 가 바뀔 때, \(h(x)\) 의 경향이 변하면 어떤 선택을 해야 하는지에 대해서는 적혀있지 않습니다. 이에 대한 해법을 만든 뒤 한국어에 대한 branching entropy tokenizer 를 만드는 일도 해봐야 겠습니다.
Apply statistical word extractors to Korean
한국어에 Accessor Variety 와 Branching Entropy 를 그대로 적용하면 안됩니다. 한국어는 일부라도 띄어쓰기 정보가 존재하며, 한국어의 통계 기반 단어 추출 기법에서는 이를 적극적으로 이용해야 합니다. 일부의 띄어쓰기 정보는 모호성을 줄여줍니다. 길이가 10 인 문장의 boundary points 는 총 9 개, 경우의 수는 \(2^9\) 입니다. 이때 띄어쓰기가 2 개만 있어도 우리가 고려해야 하는 boundary points 는 25% 로 줄어듭니다.
그보다 더 중요한 이유는 불필요한 단어 후보를 제거하는 것입니다. 우리말의 조사의 종류는 매우 한정적이며, ‘-이, -가, -도’ 등은 빈번히 이용됩니다. 아래의 경우에 대부분의 데이터에서는 ‘공연이 좋았다’ 처럼 띄어쓰기가 있을 것입니다. 이 띄어쓰기를 제거한 뒤 branching entropy 를 계산하면 ‘공연 - (이좋) - 았다’ 처럼 ‘이좋’이라는 잘못된 substring 이 단어 후보가 될 수 있습니다.
공연 + 이 + 좋다
공연 + 이 + 좋았다
수업 + 이 + 좋구나
Packages in soynlp
soynlp 에서 두 알고리즘을 제공합니다. 한국어의 특성에 맞춰서 띄어쓰기 정보를 반영하였습니다. 2016-10-20 의 뉴스 기사를 이용하여 실험하였습니다.
WordExtractor 는 Accessor Variety, Branching Entropy, Cohesion score 를 한 번에 학습합니다. 빈도수 5 이상인 단어 후보에 대하여 각 방법의 수치를 계산합니다.
from soynlp import DoublespaceLineCorpus
from soynlp.word import WordExtractor
corpus = DoublespaceLineCorpus(corpus_path, iter_sent=True)
from soynlp.word import WordExtractor
word_extractor = WordExtractor(min_count=5)
word_extractor.train(corpus)
word_scores = word_extractor.extract()dict 형식인 word_scores 에 단어 후보를 입력하면 namedtuple 이 출력됩니다. 이 중 left / right branching entropy 는 다음처럼 가져올 수 있습니다.
for word in '연합 연합뉴 연합뉴스'.split():
if word in word_scores:
score = word_scores[word]
(lbe, rbe) = (score.left_branching_entropy, score.right_branching_entropy)
else:
(lbe, rbe) = (0.0, 0.0)
print('word = {:4}, lbe = {:.3}, rbe={:.3}'.format(word, lbe, rbe))뉴스 기사이기 때문에 ‘연합뉴스’는 매우 많이 등장합니다. ‘연합뉴’ 는 right branching entropy 가 너무 작아 WordExtractor.extract() 의 과정에서 이미 탈락되었습니다.
word = 연합 , lbe = 3.2, rbe=0.427
word = 연합뉴 , lbe = 0.0, rbe=0.0
word = 연합뉴스, lbe = 3.02, rbe=3.9
Accessor Variety 역시 다음처럼 이용할 수 있습니다.
for word in '연합 연합뉴 연합뉴스'.split():
if word in word_scores:
score = word_scores[word]
(lav, rav) = (score.left_accessor_variety, score.right_accessor_variety)
else:
(lav, rav) = (0.0, 0.0)
print('word = %s, lav = %d, rav=%d' % (word, lav, rav))‘연합’ 의 오른쪽에 42 개의 글자가 등장하였지만, entropy 자체는 크지 않습니다. 대부분의 단어가 연합뉴스 였음을 의미합니다.
word = 연합, lav = 154, rav=42
word = 연합뉴, lav = 0, rav=0
word = 연합뉴스, lav = 138, rav=158
통계 기반 단어 추출 방법은 한계가 있습니다. 통계 기반 방법들은 major pattern 을 잘 찾습니다. 통계라는 말을 붙이려면 몇 번 이상의 관찰이 필요합니다. 즉, 우리가 예상하지 못했지만 도메인에서 빈번하게 사용되는 단어를 추출하는 용도로 이용해야 합니다. Infrequent words 는 통계적인 특징을 파악하기에 등장 횟수가 적습니다. 이들은 template 과 같은 보완책이 필요합니다.
Reference
- Feng, H., Chen, K., Deng, X., & Zheng, W. (2004). Accessor variety criteria for Chinese word extraction. Computational Linguistics, 30(1), 75-93.
- Feng, H., Chen, K., Kit, C., & Deng, X. (2004, March). Unsupervised segmentation of Chinese corpus using accessor variety. In International Conference on Natural Language Processing (pp. 694-703). Springer, Berlin, Heidelberg.
- Harris, Z. S. (1970). From phoneme to morpheme. In Papers in Structural and Transformational Linguistics (pp. 32-67). Springer, Dordrecht.
- Jin, Z., & Tanaka-Ishii, K. (2006, July). Unsupervised segmentation of Chinese text by use of branching entropy. In Proceedings of the COLING/ACL on Main conference poster sessions (pp. 428-435). Association for Computational Linguistics