Max Score Tokenizer 는 soynlp 에서 띄어쓰기가 잘 되어있지 않은 한국어 문장의 토크나이징을 위하여 단어 추출 방법과 함께 이용하는 unsupervised tokenizer 입니다. 이 포스트에서는 Max Score Tokenizer 의 컨셉과 개발 과정을 기술하였습니다.
Max Score Tokenizer
이 포스트에는 soynlp tokenizers 포스트의 내용이 포함되어 있습니다.
Max Score Tokenizer 는 띄어쓰기가 잘 되어있지 않은 한국어 문장을 단어열로 분해하기 위한 토크나이저입니다. 단어 추출 기법으로 학습된 subwords 의 단어 가능 점수를 기반으로, 문장에서 가장 단어스러운 부분부터 단어로 잘라냅니다.
구현체는 soynlp repository 에 있으며, 설치는 git clone 과 pip 이 가능합니다.
git clone https://github.com/lovit/soynlp.git
pip install soynlp
사용법은 아래와 같습니다.
from soynlp.tokenizer import MaxScoreTokenizer
word_scores = {'단어': 0.3, ... } # 단어 가능 점수 사전
maxscoretokenizer = MaxScoreTokenizer(scores = word_scores)
maxscoretokenizer.tokenize('아이오아이의무대가방송에중계되었습니다')
# ['아이오아이', '의', '무대', '가', '방송', '에', '중계', '되었습니다']Concept
우리에게 아래의 네 가지 subwords 의 점수표와 예문이 있다고 합니다.
sent = '파스타가좋아요'
scores = {'파스': 0.3, '파스타': 0.7, '좋아요': 0.2, '좋아':0.5}
단어 길이의 범위를 [2, 3]이라고 가정하면 아래와 같은 subword score를 얻을 수 있습니다. 아래는 (subword, begin, end, score) 입니다.
[('파스', 0, 2, 0.3),
('파스타', 0, 3, 0.7),
('스타', 1, 3, 0),
('스타가', 1, 4, 0),
('타가', 2, 4, 0),
('타가좋', 2, 5, 0),
('가좋', 3, 5, 0),
('가좋아', 3, 6, 0),
('좋아', 4, 6, 0.5),
('좋아요', 4, 7, 0.2),
('아요', 5, 7, 0)]
이를 점수 순서로 정렬하면 아래와 같습니다. 사람도 아는 단어부터 잘 인식한다는 것을, sorting 통하여 단어 점수가 가장 높은 단어 후보를 리스트의 맨 위로 올리는 것으로 구현하였습니다.
[('파스타', 0, 3, 0.7),
('좋아', 4, 6, 0.5),
('파스', 0, 2, 0.3),
('좋아요', 4, 7, 0.2),
('스타', 1, 3, 0),
('스타가', 1, 4, 0),
('타가', 2, 4, 0),
('타가좋', 2, 5, 0),
('가좋', 3, 5, 0),
('가좋아', 3, 6, 0),
('아요', 5, 7, 0)]
‘파스타’라는 subword 의 점수가 가장 높으니, 이를 토큰으로 취급합니다. ‘파스타’의 범위인 [0, 3)과 겹치는 다른 subwords 을 리스트에서 지워주면 아래와 같은 토큰 후보들이 남습니다.
파스타가좋아요 > [파스타]가좋아요
[('좋아', 4, 6, 0.5)]
('좋아요', 4, 7, 0.2),
('가좋', 3, 5, 0),
('가좋아', 3, 6, 0),
('아요', 5, 7, 0)]
다음으로 ‘좋아’를 단어로 인식하면 남은 토큰 후보가 없기 때문에 아래처럼 토크나이징이 되며, 남는 글자들 역시 토큰으로 취급합니다.
파스타가좋아요 > [파스타]가[좋아]요 > [파스타, 가, 좋아, 요]
Development
위 컨셉을 Python 을 이용하여 알고리즘으로 구현합니다. 위의 ‘파스타가좋아요’ 예문을 토크나이징하기 위하여 네 개 subwords 의 단어 점수가 저장된 score dict 를 이용합니다.
from pprint import pprint
score = {'파스': 0.3, '파스타': 0.7, '좋아요': 0.2, '좋아':0.5}
sent = '파스타가좋아요'초기화를 위하여 가능한 모든 subwords 를 추출하고, 해당 점수를 부여합니다. score dict 에 포함되지 않은 subwords 는 점수를 부여하지 않습니다. 이는 후처리 과정에서 다룹니다.
subtokens 에 입력되는 tuple 의 형식은 (word, begin, end, score) 입니다
subtokens = []
for b in range(0, len(sent)):
for r in range(2, 3+1):
e = b + r
if e > len(sent):
continue
subtoken = sent[b:e]
# (subtoken, 시작점, 끝점, 단어 점수)
subtokens.append((subtoken, b, e, score.get(subtoken, 0)))
pprint(subtokens)
# [('파스', 0, 2, 0.3),
# ('파스타', 0, 3, 0.7),
# ('스타', 1, 3, 0),
# ('스타가', 1, 4, 0),
# ('타가', 2, 4, 0),
# ('타가좋', 2, 5, 0),
# ('가좋', 3, 5, 0),
# ('가좋아', 3, 6, 0),
# ('좋아', 4, 6, 0.5),
# ('좋아요', 4, 7, 0.2),
# ('아요', 5, 7, 0)]문장에서 가장 단어스러운 subword 를 단어로 선택합니다. 즉, 단어 점수를 기준으로 subtokens 를 정렬합니다. ‘파스타’, ‘좋아’, … 순서로 정렬됩니다. 단어 점수가 같을 경우에는 길이 기준으로 정렬합니다. 같은 점수라면 더 긴 단어를 선호합니다.
subtokens = sorted(subtokens, key=lambda x:(x[3], -(x[2] - x[1])), reverse=True)
pprint(subtokens)
# [('파스타', 0, 3, 0.7),
# ('좋아', 4, 6, 0.5),
# ('파스', 0, 2, 0.3),
# ('좋아요', 4, 7, 0.2),
# ('스타', 1, 3, 0),
# ('스타가', 1, 4, 0),
# ('타가', 2, 4, 0),
# ('타가좋', 2, 5, 0),
# ('가좋', 3, 5, 0),
# ('가좋아', 3, 6, 0),
# ('아요', 5, 7, 0)]list.pop(0) 은 0번째 item을 return 하고, 해당 item 을 list 에서 제거합니다. 가장 단어스러운 subword 를 subtokens 에서 선택한 뒤, 이 subword 와 문장에서 겹치는 부분을 subtokens 에서 제거합니다.
results = []
word, b, e, s = subtokens.pop(0)
print('subtoken = %s\n' % word)
# subtoken = 파스타
pprint(subtokens)
# [('좋아', 4, 6, 0.5),
# ('파스', 0, 2, 0.3),
# ('좋아요', 4, 7, 0.2),
# ('스타', 1, 3, 0),
# ('스타가', 1, 4, 0),
# ('타가', 2, 4, 0),
# ('타가좋', 2, 5, 0),
# ('가좋', 3, 5, 0),
# ('가좋아', 3, 6, 0),
# ('아요', 5, 7, 0)]‘파스타’는 (b=0, e=3) 에 위치합니다. 다른 subword 의 끝부분 (e_) 이 b 보다 크고 시작부분 (b_) 이 e 보다 작은 모든 subwords 를 removals list 에 추가합니다.
점수가 가장 높은 subword 을 선택한 뒤, subtokens 에서 위치가 겹치는 후보들을 제거해야 합니다. 위치가 겹칠 수 있는 경우는 네가지 입니다. 점수가 가장 높은 subword 의 시작과 끝점을 b, e 라 하고, 위치가 겹치는지 확인해야 하는 subword 의 시작과 끝점을 b_, e_ 라 정의합니다.
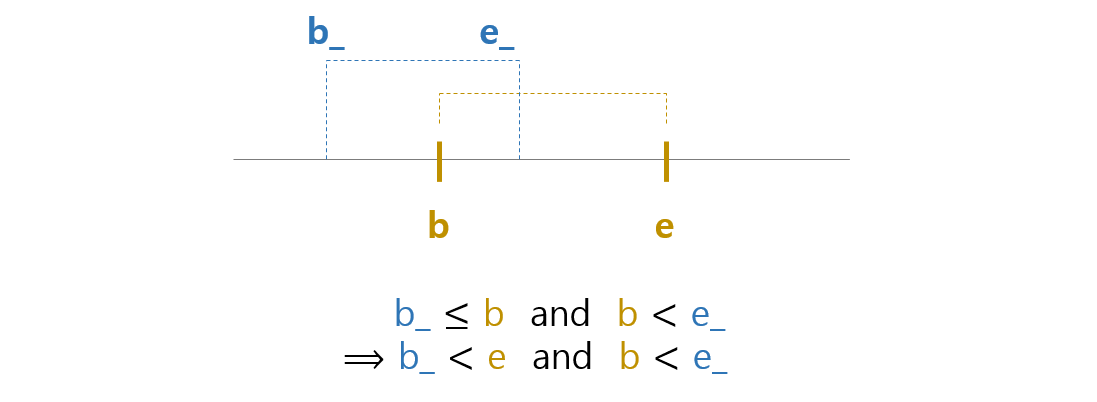
첫번째 경우는 다른 후보가 subword 의 왼쪽에 곂치는 경우입니다. 두 subwords 의 시작점이 같은 경우도 포함합니다. b_ <= b and b < e_ 입니다. b < e 이기 때문에 아래 식이 성립합니다.
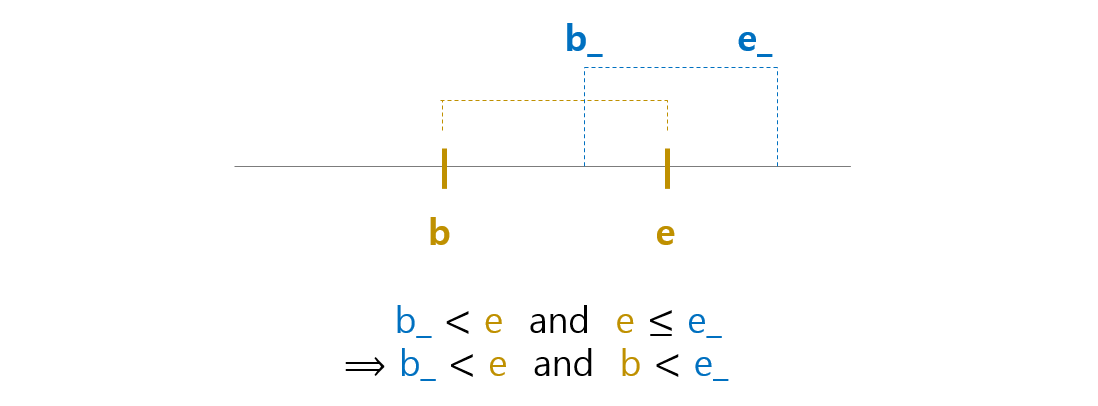
두번째 경우는 다른 후보가 subword 의 오른쪽에 겹치는 경우입니다. 두 subwords 의 끝점이 같은 경우도 포함합니다. b < b_ and e <= e_ 이고 b < e 이기 때문에 아래의 식이 성립합니다.
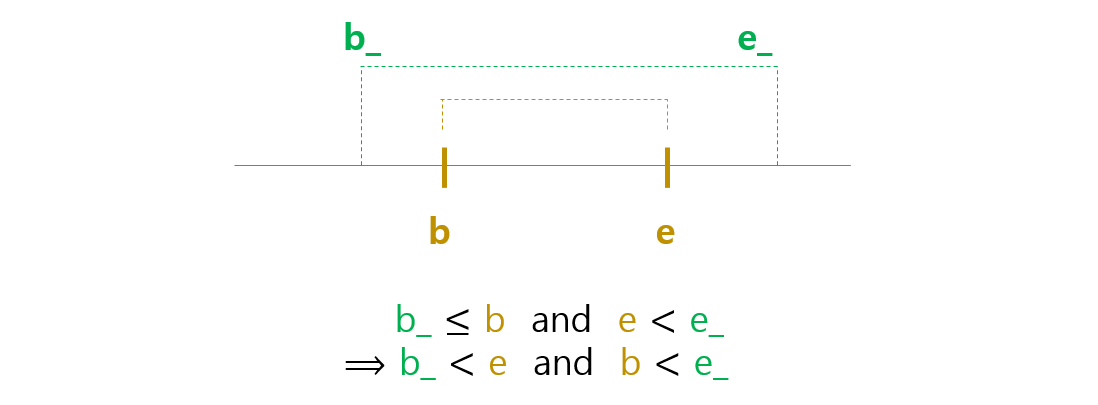
세번째는 다른 후보가 subword 를 포함하는 경우입니다. b < e 이기 때문에 아래의 식이 성립합니다.
마지막은 다른 후보가 subword 에 포함되는 경우입니다. 다른 후보가 subword 에 포함되려면 b < b_ and e_ < e 이고 b_ < e_ 이기 때문에 b_ < e and b < e_ 입니다.
모든 경우에 b_ < e and b < e_ 가 성립합니다. 이 부등식을 subtokens list 에서 겹치는 다른 후보를 찾는데 이용합니다.
results.append((word, b, e, s))
removals = []
for i, (word_, b_, e_, _) in enumerate(subtokens):
# word와 오버랩 되는 word_
if (b_ < e and b < e_):
removals.append(i)
for i in removals:
print(subtokens[i])
## 파스타와 겹치는 부분
# ('파스', 0, 2, 0.3)
# ('스타', 1, 3, 0)
# ('스타가', 1, 4, 0)
# ('타가', 2, 4, 0)
# ('타가좋', 2, 5, 0)list 에서 item 을 제거할 때에는 뒤에서부터 제거해야 합니다. subtokens = [‘a’, ‘b’, ‘c’, ‘d’, ‘e’]에서 ‘b’와 ‘e’를 삭제하고 싶다면 ‘e’를 먼저 삭제하고 ‘b’를 삭제해야 합니다. ‘b’를 먼저 삭제하면 리스트가 [‘a’, ‘c’, ‘d’, ‘e’]이 되기 때문에 ‘e’의 위치가 4 -> 3으로 바뀌게 됩니다. 하지만 ‘e’부터 지우면
del subtokens[4]: 'e' 삭제
del subtokens[1]: 'b' 삭제
가 되기 때문입니다. removals 라는 list에는 지워야 하는 subtokens의 index i가 순서대로 들어있습니다. 이를 반대로 출력하기 위해서는 reversed(list)를 하면 됩니다.
혹은 list comprehension 과 if 를 이용할 수도 있습니다.
subtokens = [subtoken for i, subtoken in enumerate(subtokens) if not (i in remomvals)]‘파스타’와 겹치는 부분을 제거한 뒤 subtokens 는 다음과 같습니다.
for i in reversed(removals):
del subtokens[i]
pprint(subtokens)
## 중복된 subtokens을 지운 뒤
# [('좋아', 4, 6, 0.5),
# ('좋아요', 4, 7, 0.2),
# ('가좋', 3, 5, 0),
# ('가좋아', 3, 6, 0),
# ('아요', 5, 7, 0)]이 작업을 subtokens 가 empty list 가 될때까지 반복합니다.
def _tokenize(subtokens):
results = []
while subtokens:
word, b, e, s, l = subtokens.pop(0)
results.append((word, b, e, s, l))
# Select overlapped subtoken
removals = []
for i, (word_, b_, e_, _1, _2) in enumerate(subtokens):
if (b_ < e and b < e_):
removals.append(i)
# Remove them
for i in reversed(removals):
del subtokens[i]
# Sort by begin point
results = sorted(results, key=lambda x:x[1])
return results‘파스타’ 와 ‘좋아’ 는 단어로 선택되었지만, ‘가’ 와 ‘요’ 는 아직 단어로 선택되지 않았습니다. subtokens list 는 이미 empty list 가 되었습니다. 이처럼 단어로 선택되지 않는 부분들을 문장에서 찾아내어 단일 단어로 입력하는 후처리 기능이 필요합니다.
results 의 단어 중 begin index 가 0 인 단어가 없으면, 처음부터 가장 빠른 begin index 까지를 하나의 단어로 results 에 입력합니다.
# 맨 앞글자가 비었을 경우,
if results[0][1] != 0:
b = 0
e = results[0][1]
word = sent[b:e]
results.insert(0, (word, b, e, 0, e - b))end index 가 문장의 길이보다 작다면 뒤의 글자가 results 에 포함되지 않은 것입니다. 가장 큰 end index 부터 문장 끝까지를 하나의 단어로 입력합니다.
# 맨 뒷글자가 비었을 경우
if results[-1][2] != len(sent):
b = results[-1][2]
e = len(sent)
word = sent[b:e]
results.append((word, b, e, 0, e - b))begin index 기준으로 정렬된 results 에서 앞 단어의 end index 뒷 단어의 begin index 가 다르다면 그 사이가 results 에 포함되지 않은 것입니다. 이를 단어로 results 에 추가합니다.
# 중간 글자가 비었을 경우
adds = []
for i, base in enumerate(results[:-1]):
if base[2] == results[i+1][1]:
continue
b = base[2]
e = results[i+1][1]
word = sent[b:e]
adds.append((word, b, e, 0, e - b))다시 한 번 results list 를 정렬하여 최종 단어열을 만듭니다.
results = sorted(results + adds, key=lambda x:x[1])이 과정을 정리하여 tokenize() 함수를 만듭니다.
def tokenize(sent, score, max_len=3):
def initialize(sent, score, max_len=3):
subtokens = []
for b in range(0, len(sent)):
for r in range(2, max_len+1):
e = b + r
if e > len(sent):
continue
subtoken = sent[b:e]
subtokens.append((subtoken, b, e, score.get(subtoken, 0), r))
if not subtokens:
return subtokens
# Sort by (score and its length)
subtokens = sorted(subtokens, key=lambda x:x[3], reverse=True)
# subtokens = sorted(subtokens, key=lambda x:(x[3], x[4]), reverse=True)
return subtokens
def _tokenize(subtokens):
results = []
while subtokens:
word, b, e, s, l = subtokens.pop(0)
results.append((word, b, e, s, l))
# Select overlapped subtoken
removals = []
for i, (word_, b_, e_, _1, _2) in enumerate(subtokens):
if (b_ < e and b < e_):
removals.append(i)
# Remove them
for i in reversed(removals):
del subtokens[i]
# Sort by begin point
results = sorted(results, key=lambda x:x[1])
return results
def postprocess(sent, results):
# 맨 앞글자가 비었을 경우,
if results[0][1] != 0:
b = 0
e = results[0][1]
word = sent[b:e]
results.insert(0, (word, b, e, 0, e - b))
# 맨 뒷글자가 비었을 경우
if results[-1][2] != len(sent):
b = results[-1][2]
e = len(sent)
word = sent[b:e]
results.append((word, b, e, 0, e - b))
# 중간 글자가 비었을 경우
adds = []
for i, base in enumerate(results[:-1]):
if base[2] == results[i+1][1]:
continue
b = base[2]
e = results[i+1][1]
word = sent[b:e]
adds.append((word, b, e, 0, e - b))
results = sorted(results + adds, key=lambda x:x[1])
return results
subtokens = initialize(sent, score, max_len)
if not subtokens:
return [(sent, 0, len(sent), 0)]
results = _tokenize(subtokens)
results = postprocess(sent, results)
return results문장 ‘난파스타가좋아요’는 아래처럼 단어열로 토크나이즈 됩니다.
tokenize('난파스타가좋아요', score)
# [('난', 0, 1, 0, 1),
# ('파스타', 1, 4, 0.7, 3),
# ('가', 4, 5, 0, 1),
# ('좋아', 5, 7, 0.5, 2),
# ('요', 7, 8, 0, 1)]글자만 선택하면 깔끔한 output 이 만들어집니다.
[w for w, _1, _2, _3, _4 in tokenize(sent, score)]
# ['난', '파스타', '가', '좋아', '요']