한국어는 5언 9 품사로 이뤄져 있습니다. 그 중 한국어로 이뤄진 텍스트의 70 % 이상이 체언 (명사, 수사, 대명사) 입니다. 명사는 어떤 개념을 설명하기 위한 단어입니다. 텍스트의 도메인마다 다른 개념들이 존재하기 때문에 각 도메인마다 서로 다른 명사들이 존재합니다. 그렇기 때문에 명사에 의한 미등록단어 문제가 가장 심각합니다. 그러나 사람은 새로운 도메인이라 하더라도 몇 개의 문서만 읽어보면 새로운 명사를 제대로 인식할 수 있습니다. 이는 한국어 어절 구조에 특징이 있기 때문입니다. 이번 포스트에서는 한국어 어절 구조의 특징인 L-R pattern 을 이용하여 통계 기반으로 명사를 추출하는 방법을 소개합니다. 이 포스트에는 Pycon KR 2017 의 발표내용이 포함되어 있습니다.
Out of “NOUN” vocabulary problem
한국어 단어의 품사 구조는 5언 9품사 입니다. 이 중 동사와 형용사는 형태가 변합니다. ‘이다’는 ‘있고, 이니까’ 처럼 어미가 활용됩니다. 하지만 그 외의 단어는 형태가 변하지는 않습니다. 형태소 분석은 단어의 구성 요소를 인식하는 것입니다. ‘이니까’는 어근 ‘이-‘와 어미 ‘-니까’ 로 이뤄진 형용사입니다. 복합명사는 여러 개의 명사들이 연속으로 이어져 만들어 집니다. ‘국악공연 = 국악 + 공연’입니다. 이처럼 단어의 구성 요소를 파악하는 문제를 형태소 분석 (morphological analysis)라 하며, 용언의 활용과 관계없이 ‘이니까’를 형용사로 인식하는 것을 품사 판별 (part of speech tagging) 이라 합니다. 형태소 분석은 품사 판별을 위해 이용될 수는 있지만, 품사 판별을 위하여 반드시 형태소 분석이 필요한 것은 아닙니다.
| 언 | 품사 |
|---|---|
| 체언 | 명사, 대명사, 수사 |
| 수식언 | 관형사, 부사 |
| 관계언 | 조사 |
| 독립언 | 감탄사 |
| 용언 | 동사, 형용사 |
품사 판별을 위해서는 질 좋은 단어 사전과 문법만 있어도 충분합니다. ‘아이오아이는’ 이라는 어절이 ‘아이오아이는 = 아이오아이/명사 + 는/조사’ 라는 규칙을 알고 있지 않더라도 다음과 같은 사전과 문법 규칙을 지니고 있다면, ‘아이오아이는’ 이라는 어절을 인식할 수 있습니다.
dictionary = {
'명사': {'아이오아이', '아이', '오'},
'조사': {'는'}
}
pattern = [('명사', '조사'), ('명사',)]
그러나 말은 언제나 변화합니다. 새로운 개념을 설명하기 위해 새로운 단어가 만들어지기 때문에 모든 단어를 포함하는 사전은 존재할 수 없습니다. KoNLPy (ver 0.4.4) 의 트위터 분석기를 이용하여 다음 문장의 품사 판별을 수행하였습니다.
from konlpy.tag import Twitter
twitter = Twitter()
twitter.pos('너무너무너무는 아이오아이의 노래입니다')두 개의 미등록단어 문제가 보입니다. ‘너무너무너무’가 ‘너무 + 너무 + 너무’로 나뉘어졌습니다. ‘아이오아이’는 ‘아이오 + 아이’로 나뉘어졌습니다. 트위터분석기에 ‘너무’, ‘아이오’, ‘아이’는 명사 사전에 등록이 되었지만, ‘너무너무너무’, ‘아이오아이’는 명사 사전에 존재하지 않기 때문입니다. KoNLPy 에 Twitter 분석기가 포함될 때에는 아이오아이라는 그룹이 존재하지 않았거든요.
[('너무', 'Noun'),
('너무', 'Noun'),
('너무', 'Noun'),
('는', 'Josa'),
('아이오', 'Noun'),
('아이', 'Noun'),
('의', 'Josa'),
('노래', 'Noun'),
('입니', 'Adjective'),
('다', 'Eomi')]
미등록단어 문제들은 주로 하나의 단어가 여러 개의 잘못된 단어로 나뉘어지는 형태로 발생합니다. 형태소 분석기, 품사 판별기는 학습 데이터를 바탕으로 주어진 문장을 이해합니다. 위와 같은 결과가 나온 이유는 학습 데이터를 이용한 모델에서 score(‘너무너무너무/unknown’ + ‘는/Josa’) < score(‘너무/Noun + 너무/Noun + 너무/Noun + 는/Josa’) 이기 때문입니다. 학습데이터에서 보지 못했던 단어를 모르는 단어로 인식하는 것보다 아는 단어의 조합으로 나누는 것을 더 선호하면 이러한 문제가 발생합니다.
이러한 미등록단어 문제는 명사에서 특히 심합니다. 명사의 역할은 어떤 개념이나 대상을 표현하기 위함입니다. 각 도메인마다 새로운 개념이 존재하고, 이를 표현하기 위해 새로운 명사들이 이용됩니다. 매일매일 새로운 사건과 새로운 엔터테이너, 영화들이 만들어집니다.
더욱이 중요한 사실은 한국어의 어절에서 가장 많이 이용되는 단어가 명사라는 점입니다. 명사는 그 자체로 자주 이용되기도 하지만, 전성어미와 함께 동사나 형용사로 치환되어 이용되는 경우도 많습니다. ‘시작하다/동사’는 정확히는 ‘시작/명사 + 하/동사형전성어미 + 다/어말어미’로 구성됩니다. 명사가 특정한 개념을 표현하기 때문에 쉽게 만들어 질 수 있는 반면, 세상의 어떤 성질을 표현하는 동사나 형용사는 쉽게 만들어지지 않습니다. 새롭게 만들어 질 때에는 명사와 전성어미가 함께 이용되는 경우가 많습니다.
명사는 자주 이용되면서 미등록단어 문제가 가장 많이 발생하는 단어입니다. 특히 키워드 추출이나 emerging topic detection 을 위해서는 신조어들을 잘 인식할 수 있어야 합니다.
그런데 사람은 새로운 도메인의 문서라 하더라도 어렵지 않게 새로운 단어를 학습할 수 있습니다. 한 사건에 대한 몇 편의 뉴스만 보더라도 그 사건의 명사들은 쉽게 배웁니다. 그 이유 중 첫째는 ‘하늘 아래 새로운 것은 그다지 많지 않다’는 점 때문 입니다. 많은 류의 명사들은 기존의 명사들의 결합으로 만들어집니다. 둘째는 명사를 포함한 어절에는 패턴이 있기 때문입니다. 명사 뒤에는 조사가 자주 등장합니다. 전성어미와 함께 ‘-하다’와 같은 형용사로 보이는 (형용사로 취급해도 데이터 분석 관점에서는 문제가 없습니다) 단어들이 등장합니다.
사람은 위와 같이 명사가 포함된 어절의 구조적인 패턴을 통하여 새로운 단어를 명사로 유추합니다. 이번 포스트에서는 이러한 패턴을 이용하여 분석을 해야 하는 데이터셋에 등장한 명사들을, 분석에 이용할 데이터를 이용하여 스스로 추출하는 unsupervised noun extraction 에 대하여 이야기합니다. 이 포스트에는 Pycon KR 2017 의 발표내용이 포함되어 있습니다.
한국어 어절의 구조, L + [R]
한국어의 어절은 L + [R] 구조입니다. 띄어쓰기가 제대로 되어있다면 한국어는 의미를 지니는 단어 명사, 동사, 형용사, 부사, 감탄사가 어절의 왼쪽 (L part)에 등장합니다. 문법 기능을 하는 조사는 어절의 오른쪽 (R part)에 등장합니다. 앞서 전성어미를 이야기하였습니다. ‘시작했던 ‘의 ‘했던’을 조사로 취급한다면 ‘시작/명사 + 했던/조사’이 됩니다. 어미는 단어가 아닌 형태소이지만, 잠시만 단어로 생각한다면 용언의 어근은 어절의 왼쪽에, 용언의 어미는 어절의 오른쪽에 등장합니다. 명사, 부사, 감탄사는 그 자체로 단일 어절을 이루기도 합니다. 반드시 R part 가 필요하지 않습니다. 그렇기 때문에 어절의 구조를 L-R 로 생각할 수 있습니다.
형태소 분석의 관점에서는 복합명사는 여러 개의 연속된 명사열입니다. 우리는 이를 단일명사로 생각합니다. ‘국악공연이 = 국악 + 공연 + 이’이 아니라, ‘국악공연 + 이’ 입니다. ‘시작했던 = 시작 + 하 + ㅆ던’이 아니라 ‘시작 + 했던’으로 단순화 할 수 있습니다. 복합형태소를 단일 단어로 가정하면 한국어 어절의 구조는 명확히 L + [R] 입니다.
다음 문장을 살펴봅시다. A가 어떤 단어인지는 모르지만 명사로 유추할 수 있습니다. A 오른쪽에 우리에게 익숙한 조사들이 3번 모두 등장하였기 때문입니다.
- 어제 A라는 가게에 가봤어
- A에서 보자
- A로 와줘
하지만 규칙을 이용하는 것은 무리가 있습니다. ‘-은, -는, -이, -가’는 우리가 자주 이야기하는 조사들입니다. 하지만, ‘하/어근 + 는/어미’, ‘받/어근 + 은/어미’ 처럼 대표적으로 이용되는 어미이기도 합니다. 에이핑크 맴버인 ‘손나은’도 ‘손나/명사 + 은/조사’가 아닙니다. 그러나 ‘손나은 + -이, -의, -에게’ 처럼 ‘손나은’의 오른쪽에 다양한 조사들이 등장합니다. 하나의 규칙보다는 전체적인 R parts 의 분포를 살펴봐야 합니다.
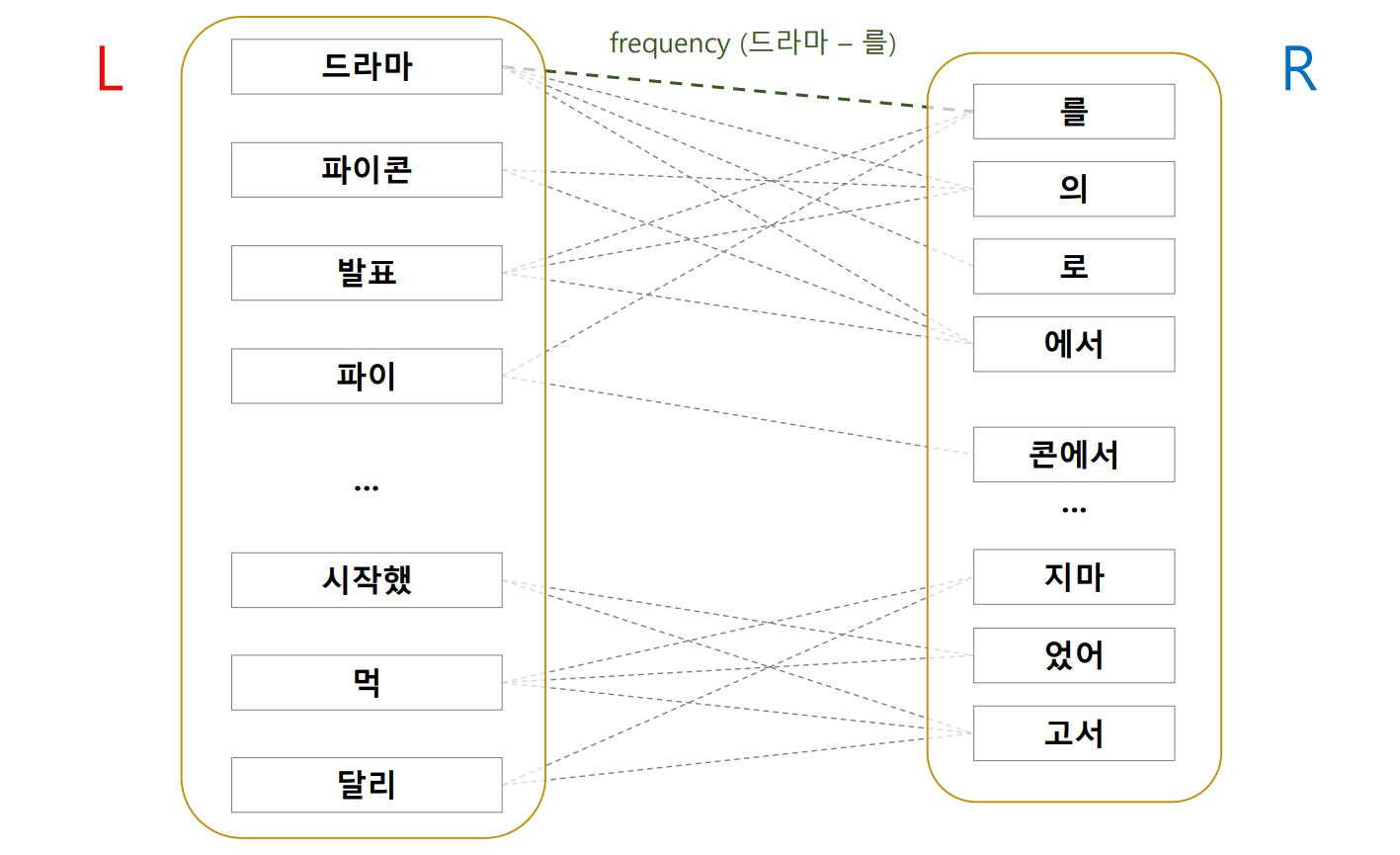
이를 확인하기 위하여 우리는 2016-10-20 의 30,091 건의 뉴스에 대하여 어절의 L-R graph 를 만들어봅니다. 뉴스는 띄어쓰기가 거의 완벽하게 지켜진 데이터입니다. 가설이 옳은지 확인하기에 매우 적합한 데이터입니다. 어절의 L-R graph 는 어절을 2 개의 parts 로 나눈 뒤, 이 둘을 연결한 substring graph 입니다. R 은 존재하지 않을 수도 있으니, empty string 을 허용합니다. dict dict 를 이용하여 손쉽게 만들 수 있습니다.
from collections import defaultdict
lrgraph = defaultdict(lambda: defaultdict(lambda: 0))
for doc in docs:
for w in doc.split():
n = len(w)
for e in range(1, n+1):
lrgraph[w[:e]][w[e:]] += 1위 코드를 이용하면 아래와 같은 L-R graph 를 만들 수 있습니다.
L part 오른쪽에 등장하는 R parts 를 확인하는 함수를 만듭니다.
def get_r(L):
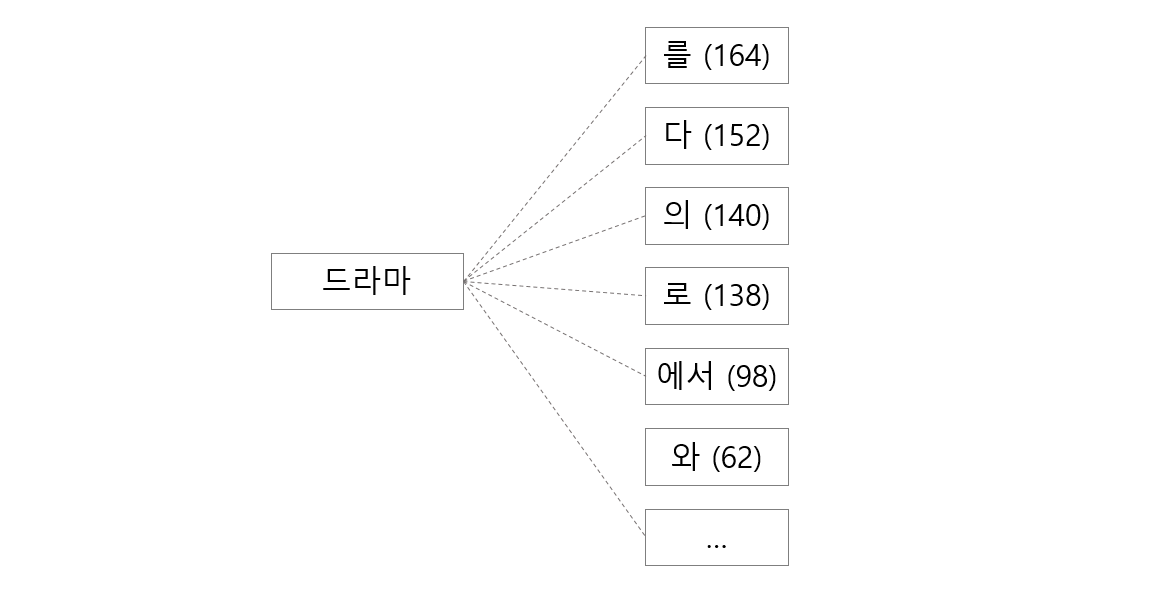
return sorted( lrgraph[L].items(), key=lambda x:-x[1])이를 이용하여 세 개의 substring 에 대한 R parts 의 분포를 살펴봅니다. ‘드라마’는 단일 명사가 어절로 이용된 경우가 1,268 번 있었습니다. ‘드라마 + 를’ 은 164 번 등장하였습니다. 조사가 자주 등장합니다. ‘시작하다/동사’의 어근 부분인 ‘시작했’의 오른쪽에는 ‘-다고’, ‘-습니다’ 등이 등장합니다. ‘-습니다’는 명사 뒤에 등장하지 않습니다. 또한 ‘드라’ 처럼 잘못된 substring 의 오른쪽에는 조사인지, 어미인지 모를 단어들이 등장합니다.
| get_r(‘드라마’) | get_r(‘시작했’) | get_r(‘드라’) |
|---|---|---|
| [(‘’, 1268), | [(‘다’, 567), | [(‘마’, 1268), |
| (‘를’, 164), | (‘고’, 73), | (‘마를’, 164), |
| (‘다’, 152), | (‘다고’, 61), | (‘마다’, 152), |
| (‘의’, 140), | (‘습니다’, 42), | (‘마의’, 140), |
| (‘로’, 138), | (‘는데’, 26), | (‘마로’, 138), |
| (‘에서’, 98), | (‘으며’, 16), | (‘마에서’, 98), |
| (‘와’, 62), | (‘지만’, 15), | (‘기’, 65), |
| (‘는’, 55), | (‘던’, 12), | (‘마와’, 62), |
| (‘에’, 55), | (‘어요’, 10), | (‘마는’, 55), |
| (‘가’, 48), | (‘다는’, 7), | (‘마에’, 55), |
| (‘이다’, 24), | (‘으나’, 5), | (‘마가’, 48), |
| (‘인’, 14), | (‘죠’, 4), | (‘이브’, 28), |
| … ] | … ] | … ] |
L + [R] 구조를 이용한 명사 추출
앞의 관찰만으로도 우리는 명사를 추출할 수 있는 논리를 만들 수 있습니다. ‘-를, -다, -의, -로’와 같은 단어의 앞에 등장한 L parts 는 명사일 점수를 높게 부여하고, ‘-다, -고, -다고, -습니다’ 앞에 등장한 L parts 는 명사가 아닐 점수를 높게 부여합니다. ‘-다’는 명사와 어근 뒤에 모두 등장하지만, L part 가 명사라면 ‘-다’ 외에도 다양한 조사들이 등장할 것입니다.
어떤 방식으로던저 R parts 앞의 L 에 대한 명사 점수 r_scores 를 만들 수 있다면 우리는 아래와 같은 간단한 명사 판별기 함수를 만들 수 있습니다.
r_scores = {'은': 0.5, ‘었다': -0.9, … }
def noun_score(L):
(norm, score, _total) = (0, 0, 0)
for R, frequency in get_r(L):
_total += frequency
if not R in r_scores:
continue
norm += frequency
score += frequency * r_scores[R]
score = score / norm if norm else 0
prop = norm / _total if _total else 0
return score, prop위 함수는 R parts 의 빈도수를 weights 로 이용하는 weighted average 역할을 합니다.
이는 데이터셋의 global information 을 이용하는 역할을 합니다. 많은 종류의 형태소 분석이나 품사 판별기들은 각 문장에 대하여 독립적인 분석을 수행합니다. ‘너’라는 단어가 ‘명사’인지 판단하기 위하여 앞이나 뒤에 등장하는 단어와 품사 정보만을 이용합니다. 한 문장에 대한 분석을 마친 다음 다른 문장을 분석할 때에는 이전에 분석했던 경험은 모두 잊혀집니다. 처음 보는 (미등록) 단어에 대하여 명사인지를 판단할 수 있는 근거는 앞, 뒤의 글자 뿐입니다.
하지만 위의 noun_score 함수는 데이터셋에 등장한 다양한 분포를 동시에 고려합니다. 사전에 ‘아이오아이’가 없더라도 하루의 뉴스를 모두 읽었다면 ‘아이오아이 + [조사]’라는 패턴을 학습할 수 있습니다. 한 문장이 아닌 모든 문장에서의 통계로부터 global information 을 추출한 뒤 이를 이용하면 더 정확한 분석을 할 수 있습니다.
이런 맥락에서 Hai Zhao 의 ‘Incorporating global information into supervised learning ..’ 이라는 표현을 정말 좋아합니다. 특히나 자연어처리 알고리즘들은 학습데이터에 overfitting 이 되는 경우가 많습니다. 말이 너무나도 다양하기 때문입니다. 학습데이터의 패턴에만 치우쳐지지 않기 위하여 분석할 데이터에서의 global information 을 이용하는 쪽으로 알고리즘들이 만들어져야 한다고 생각합니다.
세종 말뭉치 L, R table
이제 R parts 가 명사 뒤에 등장할 가능성에 대한 점수표를 만들어봅니다.
이를 위해서는 학습데이터가 필요합니다. 명사 추출기에 필요한 학습데이터는 어절에서 어떤 부분이 명사인지 label 이 달린 데이터여야 합니다. 말뭉치 (corpus)는 이처럼 한 문장에 대하여 각 문장의 요소인 단어나 형태소 수준에서 태그가 달려있는 자연어처리용 데이터입니다. 세종말뭉치는 국립국어원에서 공개한 한국어에 대한 말뭉치입니다. 국립국어원에 신청하면 연구용 목적으로 데이터를 받으실 수 있습니다.
세종말뭉치의 각 어절에 대하여 다음의 형태로 데이터를 정제합니다. 명사, 동사와 형용사의 어근이 포함된 어절에 대하여 어절을 L-R parts 로 분해합니다. 이 과정에 조금의 수작업이 필요합니다. ‘시작했다고 = 시작/명사 + 하/동사형전성어미 + 았/선어말어미 + 다고/어말어미’ 로 나뉘어진 어절에 대하여 ‘시작/L + 했다고/R’ 처럼 정제하는 복합형태소 처리 작업을 해야 합니다. 몇 몇 데이터에서 format 이 다르거나 파일의 인코딩이 다른 파일들과 다른 경우들이 있으니 이를 조심해야 합니다.
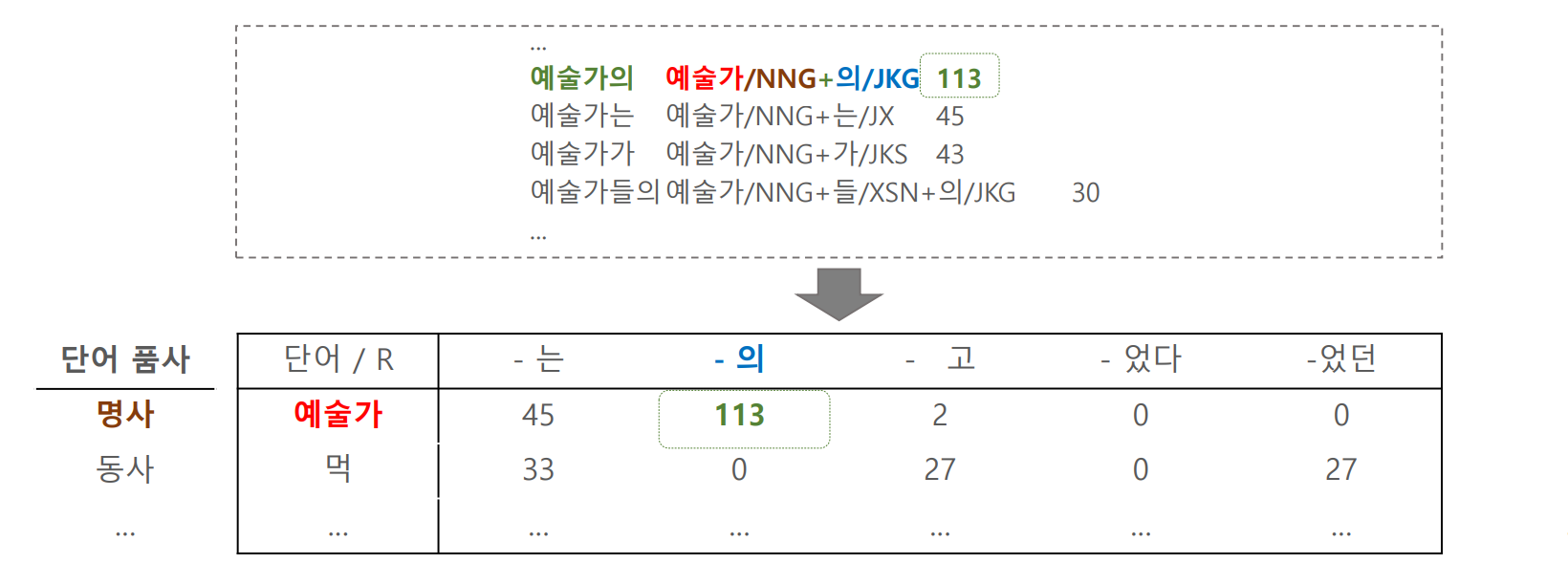
일단 L-R table 을 만들면 classifiers 를 이용할 수 있습니다. L parts 에 대하여 명사인지 아닌지를 판단하는 logistic regression 을 이용할 수 있습니다. 이 때 R parts 는 features 가 됩니다. 마치 하나의 L part 가 하나의 문서이며, R parts 가 단어인 document classification 과 비슷합니다.
다양한 classifiers 를 이용하여 L-R table 을 이용한 명사 판별 능력을 측정하였습니다. 데이터셋의 ‘L >= 30, R >= 15’ 는 L parts 의 빈도수가 30 이상이고 R parts 의 빈도수가 15 이상인 L-R table 을 의미합니다. Overfitting 을 방지하기 위하여 min count filtering 을 하였습니다. Radial Basis Function 을 이용하는 SVM 외에는 모두 99 % 의 정확도를 보입니다. RBF kernel SVM 만 Euclidean distance 에 기반합니다. Naive Bayes 는 확률모델이니 제외하면, 다른 알고리즘들은 벡터의 내적에 기반한 classification 을 합니다. Sparse vector 에서의 내적이 0 이상이려면 공통된 단어 (R parts)가 포함된 경우여야 합니다. 즉, 특정 R parts 가 등장하느냐가 명사인지 아닌지를 판단하는 매우 중요한 근거라는 의미입니다.
| Algorithm \ Dataset | L >= 30, R >= 15 | L >= 10, R >= 10 | L >= 5, R >= 5 |
|---|---|---|---|
| L2-Logistic regression \(\lambda\)=1e-5 |
0.9951 | 0.9947 | 0.9946 |
| L2-Logistic regression \(\lambda\)=1e-3 |
0.9963 | 0.9956 | 0.9957 |
| L2-Logistic regression \(\lambda\)=0.01 |
0.9964 | 0.9954 | 0.9955 |
| L2-Logistic regression \(\lambda\)=0.25 |
0.9963 | 0.9949 | 0.9951 |
| L2-Logistic regression \(\lambda\)=1 |
0.9958 | 0.9942 | 0.9945 |
| L2-Logistic regression \(\lambda\)=4 |
0.9948 | 0.9935 | 0.9939 |
| L1-Logistic regression \(\lambda\)=0.25 |
0.9959 | 0.9956 | 0.9938 |
| L1-Logistic regression \(\lambda\)=1 |
0.9951 | 0.9948 | 0.9936 |
| L1-Logistic regression \(\lambda\)=4 |
0.9942 | 0.994 | 0.9926 |
| SVM-L lambda=0.1 | 0.9941 | 0.9946 | 0.9936 |
| SVM-L lambda=1 | 0.9938 | 0.9946 | 0.994 |
| SVM-L lambda=10 | 0.9928 | 0.9936 | 0.9928 |
| SVM-RBF lambda=0.1 | 0.9877 | 0.9947 | 0.9938 |
| SVM-RBF lambda=1 | 0.8341 | 0.9948 | 0.9942 |
| SVM-RBF lambda=10 | 0.8341 | 0.9939 | 0.9929 |
| Naive Bayes | 0.9939 | 0.99 | 0.986 |
| Feedforward neural network hidden=(5,) |
0.9968 | 0.9957 | 0.9951 |
| Feedforward neural network hidden=(20,) |
0.9968 | 0.996 | 0.9951 |
| Feedforward neural network hidden=(50,10) |
0.9964 | 0.9959 | 0.9949 |
Logistic regression 나 Naive Bayes 의 coefficients 를 r_scores 로 이용할 수도 있습니다.
Post-processing
위 방법만으로는 명사가 아닌 단어들이 명사로 추출되는 경우들이 발생합니다. ‘떡볶이’는 다른 조사들과 함께 자주 등장하여 명사로 추출됩니다. 하지만 명사는 단일 명사가 하나의 어절이 되기도 합니다. ‘-이’는 대표적인 조사이기 때문에 ‘떡볶’ 역시 높은 명사 점수를 받을 수 있습니다. 이 경우를 방지하기 위하여 ‘떡볶이’가 명사이고 끝 부분의 1음절이 조사인 경우는 추출된 명사에서 제외합니다.
‘대학생으로’ 역시 ‘대학생’이 명사이지만, ‘-로’ 가 대표적인 조사이기 때문에 ‘대학생으’도 명사로 추출됩니다. 이번에는 떡볶이와 반대의 경우로 더 긴 단어의 마지막 글자와 그 뒤에 자주 등장하는 R parts 를 합쳤을 때 (-으 + -로) 조사이면 이를 추출된 명사에서 제외합니다.
이외에도 도메인에 적합한 몇 가지 후처리 기능들을 추가하여 간단한 명사 추출기를 만들 수 있습니다.
Packages: soynlp
위 과정은 soynlp 에 명사 추출기로 구현되어 있습니다.
Sentence 단위로 iteration 을 돌 수 있는 corpus 를 만듭니다. list of str 처럼 len 의 기능을 지니며, 각 iteration 의 대상이 str 인 형태이면 모두 이용 가능합니다.
from soynlp import DoublespaceLineCorpus
corpus_path = "YOURS"
sentences = DoublespaceLineCorpus(corpus_path, iter_sent=True)soynlp <= 0.0.45 버전에서는 두 가지 명사 추출기가 구현되어 있습니다. train_extract 를 하면 dict 형식의 nouns 가 return 됩니다. 각 명사에 대한 정보들이 nouns[‘명사’]의 value 로 저장되어 있습니다.
from soynlp.noun import LRNounExtractor
noun_extractor = LRNounExtractor()
nouns = noun_extractor.train_extract(sentences) # list of str like
from soynlp.noun import NewsNounExtractor
noun_extractor = NewsNounExtractor()
nouns = noun_extractor.train_extract(sentences) # list of str likeDemo
아래는 2016-10-20 의 뉴스에 대하여 명사를 추출한 결과입니다. 뉴스의 댓글에서는 ‘tt’ 도 명사로 추출되었습니다. 당시 트와이스의 ‘tt’라는 노래가 한창 인기를 끌었습니다. ‘tt가 좋아’, ‘tt가 1위했어’ 와 같은 문장 덕분에 영어로 표기된 ‘tt’도 명사로 추출될 수 있습니다. 사실 R parts 의 분포를 살펴보는 것이기 때문에 L parts 가 어떤 언어로 표기가 되어있던지 관계없이 명사로 이용된 경우에는 추출이 될 수 있습니다.
‘1987년’도 비슷한 예시입니다. 1987년 10월 19일은 세계 주식시장의 블랙먼데이가 발생했던 날입니다. 이날의 뉴스에서는 이런 구절들이 등장합니다. ‘1987년’은 30년 전의 블랙먼데이를 지칭하는 명사입니다.
그 외의 명사도 추출이 잘 됨을 확인할 수 있습니다.
| 덴마크 | 웃돈 | 너무너무너무 | 가락동 | 매뉴얼 | 지도교수 |
| 전망치 | 강구 | 언니들 | 신산업 | 기뢰전 | 노스 |
| 할리우드 | 플라자 | 불법조업 | 월스트리트저널 | 2022년 | 불허 |
| 고씨 | 어플 | 1987년 | 불씨 | 적기 | 레스 |
| 스퀘어 | 충당금 | 건축물 | 뉴질랜드 | 사각 | 하나씩 |
| 근대 | 투자주체별 | 4위 | 태권 | 네트웍스 | 모바일게임 |
| 연동 | 런칭 | 만성 | 손질 | 제작법 | 현실화 |
| 오해영 | 심사위원들 | 단점 | 부장조리 | 차관급 | 게시물 |
| 인터폰 | 원화 | 단기간 | 편곡 | 무산 | 외국인들 |
| 세무조사 | 석유화학 | 워킹 | 원피스 | 서장 | 공범 |
대화데이터에서도 충분히 좋은 성능을 보여줍니다. ‘강만후’는 ‘내딸 금사월’의 극중명이며, ‘마스크걸’은 네이버 웹툰, ‘전리품상자’나 ‘리장타워’는 게임 오버워치의 용어입니다. ‘서가엔쿡’같은 고유명사도 데이터 기반으로 추출할 수 있습니다.
| 변심 | 인시디어스 | 코디님 | 강만후 | 병원예약 | 전공필수 |
| 이런의미 | 바깥양반 | 프레시아 | 전리품상자 | 난심일기 | 근육몬 |
| 동피랑 | 상태이상 | 흐흐르 | 수입과자 | 모래사장 | 알엔에이 |
| 오션윙 | 옥매미 | 산넘어산 | 클럽하우스 | 물한번 | 손에다 |
| 따른사람 | 모진말 | 노들섬 | 한신아파트 | 괜차니 | 핵고생 |
| 다음장 | 아이도루 | 본사사람 | 마스크걸 | 브런치카페 | 클렌징워터 |
| 배아플라 | 일일미션 | 버스정거장 | 리장 | 안산도착 | 다리하나 |
| 빠른사과 | 용계 | 아홉시꺼 | 걸신 | 컴푸타 | 필터빨 |
| 성큼성큼 | 서가엔쿡 | 경중 | 스카이워크 | 인형만 | 하루시작 |
| 퍈의점 | 신청하기 | 미모쨜 | 재밌는시간 | 운동하규 | 간사들 |
이처럼 분석을 해야 하는 데이터로부터 해당 데이터에 등장하는 단어들을 추출함으로써 미등록단어의 문제를 조금 더 해결할 수 있습니다.
References
- PyconKR2017 노가다 없는 텍스트 분석을 위한 한국어 NLP
- Zhao, H., & Kit, C. (2007). Incorporating global information into supervised learning for Chinese word segmentation. In Proceedings of the 10th Conference of the Pacific Association for Computational Linguistics (pp. 66-74).