Conditional Random Field 는 logistic regression 을 이용하는 sequential labeling 용 알고리즘입니다. 한국어 띄어쓰기 교정 문제는 길이가 \(n\) 인 character sequence 에 대하여 ‘띈다 / 안띈다’의 label 을 부여하는 sequential labeling 문제입니다. 이번 포스트에서는 Python 의 pycrfsuite 를 이용하여 한국어 띄어쓰기 교정기를 구현하는 과정과, 그 과정을 거쳐 구현된 소프트웨어 (pycrfsuite_spacing)의 사용법을 이야기합니다.
Brief review of Conditional Random Field
Conditional Random Field (CRF) 는 sequential labeling 을 위하여 potential functions 을 이용하는 softmax regression 입니다. Deep learning 계열 모델인 Recurrent Neural Network (RNN) 이 sequential labeling 에 이용되기 전에, 다른 많은 모델보다 좋은 성능을 보인다고 알려진 모델입니다.
Sequential labeling 은 길이가 \(n\) 인 sequence 형태의 입력값 \(x = [x_1, x_2, \ldots, x_n]\) 에 대하여 길이가 \(n\) 인 적절한 label sequence \(y = [y_1, y_2, \ldots, y_n]\) 을 출력합니다. 이는 \(argmax_y P(y_{1:n} \vert x_{1:n})\) 로 ㅍ현할 수 있습니다.
Softmax regression 은 벡터 \(x\) 에 대하여 label \(y\) 를 출력하는 함수입니다. 하지만 입력되는 sequence data 가 단어열과 같이 벡터가 아닐 경우에는 이를 벡터로 변환해야 합니다. Potential function 은 categorical value 를 포함하여 sequence 로 입력된 다양한 형태의 값을 벡터로 변환합니다.
Potential function 은 Boolean 필터처럼 작동합니다. 아래는 두 어절로 이뤄진 문장, “예문 입니다” 입니다. 앞의 한글자와 그 글자의 띄어쓰기, 그리고 현재 글자를 이용하여 현재 시점 \(i\) 를 벡터로 표현할 수 있습니다.
- \(x = '예문 입니다'\) .
- \(F_1 = 1\) if \(x_{i-1:i} =\) ‘예문’ else \(0\)
- \(F_2 = 1\) if \(x_{i-1:i} =\) ‘예문’ & \(y[i-1] = 0\) else \(0\)
- \(F_3 = 1\) if \(x_{i-1:i} =\) ‘문입’ else \(0\)
- \[\cdots\]
앞글자부터 현재 글자, 그리고 앞글자의 띄어쓰기 정보를 이용한다는 것을 템플릿으로 표현할 수 있습니다. 현재 시점을 \(i\) 가 아닌 \(0\) 이라 표현하였습니다.
- templates
- \(x_{-1:0}\) .
- \(x_{-1:0}\) & \(y_{-1}\) .
그림은 위 예시 템플릿을 이용하여 ‘예문 입니다’에 potential functions 을 적용한 결과입니다. 마치 5 개의 문서에 대한 term frequency vector 처럼 보입니다.
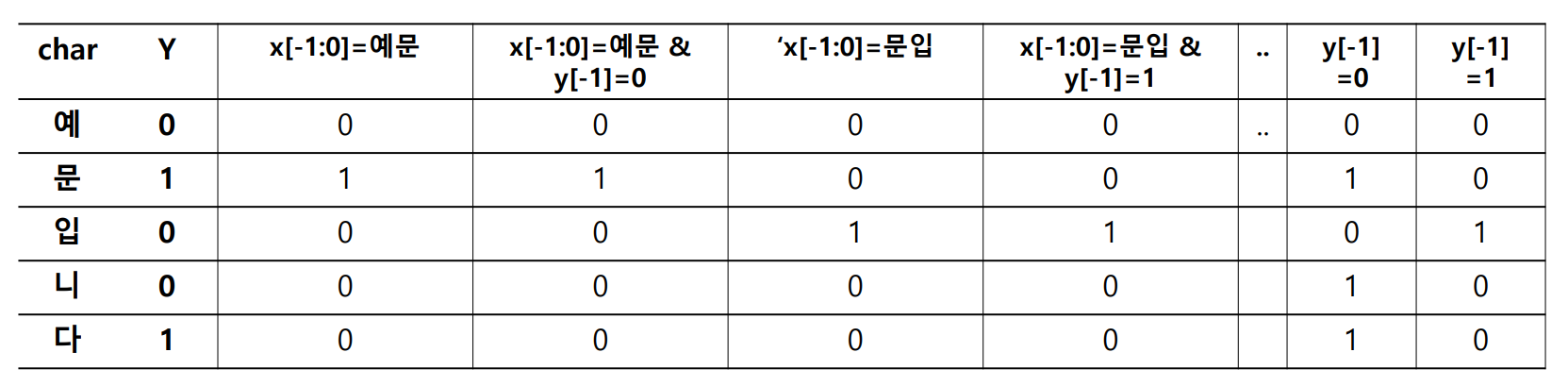
이처럼 potential functions 은 임의의 형태의 데이터라 하더라도 Boolean filter 를 거쳐 high dimensional sparse Boolean vector 로 표현합니다. Conditional Random Field 는 특정 상황일 때 특정 label 의 확률을 학습하는 모델입니다.
CRF 와 비슷한 모델 중 Maximum Entropy Markov Model (MEMM) 이 있습니다. MEMM 은 \(P(y_{1:n} \vert x_{1:n})\) 를 다음처럼 계산합니다.
\[P(y \vert x) = \prod_{i=1}^{n} \frac{exp(\sum_{j=1}^{m} \lambda_j f_j (x, i, y_i, y_{i-1}))}{ \sum_{y^{`}} exp(\sum_{j^{`}=1}^{m} \lambda_j f_j (x, i, y_i^{`}, y_{i-1}^{`})) }\]\(f_j\) 는 potential function 입니다. Potential functions 에 의하여 \(m\) 차원의 sparse vector 로 표현된 \(x_i\)와 coefficient vector \(\lambda\) 의 내적에 exponential 이 취해집니다. 다른 labels 후보 \(y^{`}\) 의 값들의 합으로 나뉘어집니다. \(n\) 번의 softmax regression classification 을 순차적으로 하는 형태입니다. 하지만 MEMM 은 label bias 문제가 발생합니다. 이를 해결하기 위하여 CRF 가 제안되었습니다.
CRF 의 \(P(y_{1:n} \vert x_{1:n})\) 은 다음처럼 기술됩니다.
\[P(y \vert x) = \frac{exp(\sum_{j=1}^{m} \sum_{i=1}^{n} \lambda_j f_j (x, i, y_i, y_{i-1}))}{ \sum_{y^{`}} exp(\sum_{j^{`}=1}^{m} \sum_{i=1}^{n} \lambda_j f_j (x, i, y_i^{`}, y_{i-1}^{`})) }\]\(n\) 번의 logistic classification 이 아닌, vector sequences, 즉 matrix 에 대한 한 번의 logistic classification 입니다.
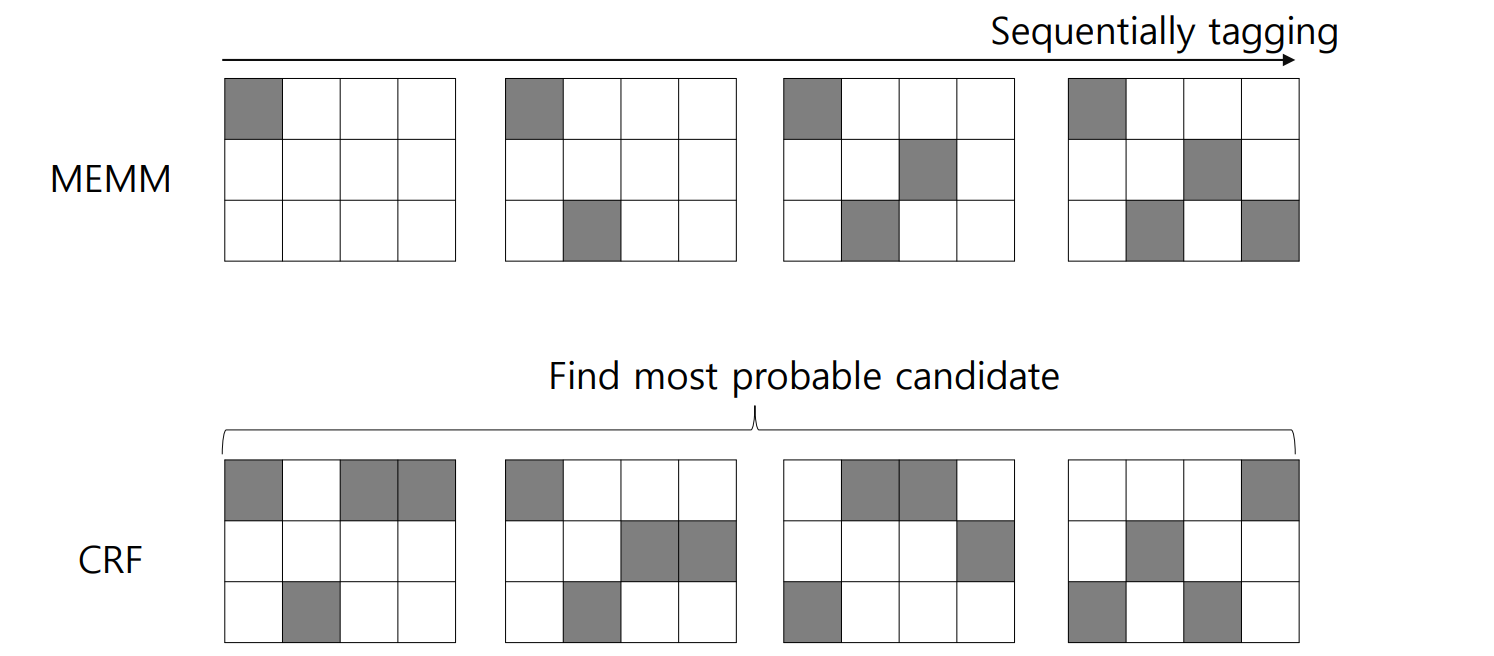
자세한 Conditional Random Field 의 설명은 이전 블로그 를 참고하세요.
띄어쓰기용 학습데이터 선택
Conditional Random Field 를 이용하여 영화 ‘라라랜드’ 리뷰용 띄어쓰기 교정기를 만듭니다. 이를 위하여 Python 의 pycrfsuite package 를 이용합니다. 우리가 연습으로 사용할 데이터는 여기에 올려두었습니다. 라라랜드 영화의 커멘트 일부입니다.
띄어쓰기 교정기는 띄어쓰기가 잘 지켜진 데이터의 패턴을 학습한 뒤, 띄어쓰기가 잘 되지 않은 문장을 교정합니다. 이를 위한 학습데이터를 준비할 때에는 두 가지를 신경써야 합니다.
첫째는 학습데이터의 vocabulary distribution 입니다. Conditional Random Field 는 supervised algorithm 입니다. 학습데이터로 가르쳐 준 일은 잘 수행하지만, 가르쳐주지 않은 일을 잘할거라고는 보장하기 어렵습니다. 띄어쓰기 교정기가 이용하는 features 는 앞/뒤에 등장한 글자입니다. 학습데이터에 등장한 어절 간의 간격 패턴을 학습하여 띄어쓰기 오류를 교정합니다. 하지만 처음 보는 단어들이 등장한다면 모델은 혼란스럽습니다. 그렇기 때문에 첫째가 vocabulary distribution 이 비슷한 학습데이터 입니다. 적어도 그럴 데이터를 우리는 가지고 있습니다. 바로 띄어쓰기를 교정할 데이터입니다.
하지만 교정할 데이터에는 띄어쓰기 오류가 포함되어 있습니다. 그러나 데이터의 모든 문장이 띄어쓰기 오류가 있을리는 없습니다. 그렇다면 그건 오류가 아니라 ‘언어 패턴’입니다. 한국어의 어절의 평균 길이는 약 4 음절입니다. 학습데이터의 문장들 중에서 띄어쓰기가 그나마 잘 지켜진, 평균 어절 길이기 짧은 문장들을 선택하여 학습데이터를 만듭니다. 이 과정에 일부 노이즈가 섞여도 괜찮습니다. 오류와 정답이 1:9 비율로 존재한다면 모델이 알아서 정답의 편을 들것입니다.
pycrfsuite 를 이용한 띄어쓰기 교정기 구현
pycrfsuite 는 C 로 구현된 crfsuite library 를 Python 에서 이용할 수 있도록 도와줍니다. 설치는 pip isntall 이 가능합니다. 패키지의 이름과 pypi 에 등록된 이름이 다릅니다.
pip install python-crfsuite
아래의 내용은 pycrfsuite 를 이용하여 띄어쓰기 교정기를 구현하는 과정입니다. 이를 정리하여 패키지로 만들어뒀습니다. 사용법만 보시려면 다음 chapter 를 보셔도 됩니다.
Templates 구현
Feature 의 templates을 만듭니다. 템플릿은 다양한 종류로 여러 번 만들 수 있기 때문에 함수로 만듭니다. 아래는 앞의 2 글자부터 뒤의 2 글자까지 고려하는 길이가 3 인 templates 입니다.
[(-2, 0), (-2, 1), (-1, 1), (-1, 2), (0, 2)]
아래는 길이가 3 이거나 4 이면서 앞의 2글자부터 뒤의 2글자까지를 고려하는 templates 입니다.
[(-2, 0), (-2, 1), (-2, 2), (-1, 1), (-1, 2), (0, 2)]
시작점과 끝점, 그리고 templates 의 최소와 최대 길이를 argument 로 받는 함수를 만듭니다.
def generate_templates(begin=-2, end=2, min_range_length=3, max_range_length=5):
templates = []
for b in range(begin, end):
for e in range(b, end+1):
length = (e - b + 1)
if length < min_range_length or length > max_range_length:
continue
if b * e > 0:
continue
templates.append((b, e))
return templates
templates = generate_templates()
print(templates)
# [(-2, 0), (-2, 1), (-2, 2), (-1, 1), (-1, 2), (0, 2)]위의 함수에서 아래의 부분에 의하여 현재 시점의 글자를 포함하지 않으면서 앞에만 존재하거나 뒤에만 존재하는 template 은 이용하지 않습니다. 자신도 보지 않은 체, 앞이나 뒤 둘 중 한군데만 바라보면 잘못된 판단을 하기 쉽습니다. 이는 띄어쓰기와 관련된 다른 포스트에서 이야기합니다. 여하튼 이번에는 현재 시점을 포함하는 templates 를 만듭니다.
if b * e > 0:
이 포스트는 튜토리얼 코드이기 때문에 짧은 templates 만을 이용합니다.
templates = generate_templates(begin=-2, end=2, min_range_length=3, max_range_length=3)
print(templates)
# [(-2, 0), (-1, 1), (0, 2)]Character feature transformer 구현
앞서 만든 templates 을 이용하여 character sequence 로부터 features 를 변환하는 함수를 만듭니다. Templates 를 입력받으므로 class 형태로 만듭니다. templates 를 이용하여 (begin, end) index 의 substring 을 list 의 형태로 출력합니다. 따로 변환 함수는 만들지 않고, 내장함수 call 을 오버라이딩합니다.
class CharacterFeatureTransformer:
def __init__(self, templates):
self.templates = templates
def __call__(self, chars, tags=None):
x =[]
for i in range(len(chars)):
xi = []
e_max = len(chars)
for t in self.templates:
b = i + t[0]
e = i + t[1] + 1
if b < 0 or e > e_max:
continue
xi.append(('X[%d,%d]' % (t[0], t[1]), chars[b:e]))
x.append(xi)
return x‘예문입니다’라는 5 음절 문장의 각 시점에 대한 features 는 아래와 같습니다.
[[('X[0,2]', '예문입')],
[('X[-1,1]', '예문입'), ('X[0,2]', '문입니')],
[('X[-2,0]', '예문입'), ('X[-1,1]', '문입니'), ('X[0,2]', '입니다')],
[('X[-2,0]', '문입니'), ('X[-1,1]', '입니다')],
[('X[-2,0]', '입니다')]]
형식은 list of list of tuple 입니다. 첫번째 list 는 각 시점을, 두번째 list 는 한 시점의 features 입니다. 한 시점의 하나의 feature 는 2 개의 str 로 구성된 tuple 입니다.
이는 아래처럼 구현할 수도 있습니다. 하지만 아래처럼 구현하면 ‘X[0,2] = 예문입’ 와 ‘X[-1,1] = 예문입’ 라는 모든 str 이 Python 의 메모리에 올라갑니다. Python 의 str 은 그 값이 한 번 만들어진 뒤, 동일한 값이 만들어질 때는 메모리주소를 이용함으로써 메모리 효율을 높입니다. 몇 개의 substring 이 반복적으로 사용된다면 이를 tuple of str 로 나눠 이용하면 메모리 효율이 좋습니다.
('X[%d,%d] = %s' % (t[0], t[1], chars[b:e]))
Sentence tagger: Sentence to (characters and tags)
문장을 (1) 글자열과 (2) 띄어쓰기 태그로 분리하는 함수를 만듭니다. character sequence 와 label sequence 를 만들기 위함입니다. ‘1’은 띄어쓴다, ‘0’은 붙여쓴다를 의미하며, 문장의 맨 끝은 반드시 띄어쓰는 태그를 부여합니다. ‘1’ 처럼 str 이 아닌 int 를 이용할 수도 있습니다. 그러나 int 는 pycrfsuite 에 입력할 수 없는 데이터타입이기 때문에 str 을 이용합니다.
def sent_to_chartags(sent, nonspace='0', space='1'):
chars = sent.replace(' ','')
if not chars:
return '', []
tags = [nonspace]*(len(chars) - 1) + [space]
idx = 0
for c in sent:
if c == ' ':
tags[idx-1] = space
else:
idx += 1
return chars, tags
sent_to_chartags('예문 입니다')
# ('예문입니다', ['0', '1', '0', '0', '1'])아래 부분을 통하여 empty sentence 가 입력되었을 경우의 exception 을 처리합니다.
if not chars:
return '', []
Empty sentence 를 입력한 결과는 아래와 같습니다.
sent_to_chartags('')
# ('', [])sent_to_xy는 한 문장이 들어왔을 때, (1) feature 로 바꿔주는 transformer 를 이용하여 문장의 글자열 chars 로부터 feature 를 만들고, (2) 각 글자에 해당하는 띄어쓰기 label 인 y 를 만들어 return 합니다.
sent_to_xy 를 이용하여 아래와 같이 학습가능한 형태의 x 와 y 를 만듭니다.
def sent_to_xy(sent, feature_transformer):
chars, tags = sent_to_chartags(sent)
x = [['%s=%s' % (xij[0], xij[1]) for xij in xi] for xi in feature_transformer(chars, tags)]
y = [t for t in tags]
return x, y
x,y = sent_to_xy('예문 입니다', transformer)우리가 만든 sent_to_xy 함수를 이용하여 만들어진 x 와 y 의 모습입니다.
print(x)
# [['X[0,2]=예문입'],
# ['X[-1,1]=예문입', 'X[0,2]=문입니'],
# ['X[-2,0]=예문입', 'X[-1,1]=문입니', 'X[0,2]=입니다'],
# ['X[-2,0]=문입니', 'X[-1,1]=입니다'],
# ['X[-2,0]=입니다']]
print(y)
# ['0', '1', '0', '0', '1']학습을 위하여 pycrfsuite.Trainer 를 만든 뒤, 한문장씩 feature x 와 label y 를 append 해야 합니다. 이 때에는 반드시 x와 y의 길이가 같아야 합니다.
import pycrfsuite
trainer = pycrfsuite.Trainer(verbose=False)
# possible only if len(x) == len(y)
trainer.append(x, y) pycrfsuite 를 이용할 때 자주 이용하는 parameters 입니다. 기본으로 설정된 iteration 횟수가 많이 큽니다. 이를 적당한 수준으로 조절합니다. c1, c2를 이용하여 L1, L2 regularization을 걸 수 있습니다. c1 = 0 이면, L2 regularization 만 이용합니다. 반대로 c2 = 0, c1 > 0 이면 L1 regularization 을 이용할 수 있습니다.
주의해야 할 parameter 중 하나는 feature.minfreq 입니다. 기본값은 0 으로 되어있기 때문에 한 번이라도 등장한 모든 feature 를 이용합니다. 이 경우에는 overfitting 이 일어날 수 있지만, 그 전에 데이터의 크기가 조금만 커져도 수천만차원의 벡터 공간을 만듭니다. 이전에 이를 설정하지 않았다가 3천만차원 logstic regression 을 학습한 적이 있습니다. 이런 상황을 방지하기 위하여 feature.minfreq 를 적절하게 설정해야 합니다. Term frequency matrix 의 minimum frequency 처럼 생각하면 됩니다.
그 외의 parameters 에 대해서는 crfsuite 의 manual 을 참고하세요.
pycrfsuite는 crfsuite 의 C++ 코드를 그대로 실행합니다. 이 코드는 반드시 학습된 모델을 bin 파일로 저장하도록 되어있는데, 이 때문에 trainer.train(model_fname) 으로 학습된 모델을 일단 저장해야 합니다.
params = {
'max_iterations':50, # default 1000
'c1': 0, # L1 regularization, default 1
'c2': 1, # L2 regularization, default 2
'feature.minfreq': 3 # minimum frequency of feature. default 0 (without pruning)
}
model_fname = 'crfsuite_spacing.model'
trainer = pycrfsuite.Trainer(verbose=False)
for doc in docs:
x, y = sent_to_xy(doc, transformer)
trainer.append(x, y)
trainer.set_params(params)
trainer.train(model_fname)저장된 모델은 pycrfsuite.Tagger()로 tagger를 만든 뒤, tagger.open()으로 읽어올 수 있습니다.
tagger = pycrfsuite.Tagger()
tagger.open(model_fname)교정할 문장 sent 와 transformer 를 입력받은 뒤, 글자열에 대하여 feature x 를 만듭니다. 이를 이용하여 tagging 을 수행하고, y_pred 의 값에 따라 띄어쓰기를 교정합니다.
def correct(sent, feature_transformer):
x, y = sent_to_xy(sent, feature_transformer)
y_pred = tagger.tag(x)
char = sent.replace(' ','')
corrected = ''.join([c if tag == '0' else c + ' ' for c, tag in zip(char, y_pred)]).strip()
return corrected
print(correct('이건정말로좋은영화였다', transformer))
# '이건 정말로 좋은 영화였다'Feature weight 살펴보기
Conditional Random Field 는 결국 Softmax regression 입니다. 각 y 에 관한 기여도, 즉 logistic regression 에서의 coefficients 를 확인할 수 있습니다. weights는 {(attribute, class):weight} 형식의 dict 입니다.
debugger = tagger.info()
weights = debugger.state_features10 개의 features 에 대한 weight samples 입니다.
print(list(weights.items())[:10])
# [(('X[0,2]=시사회', '0'), 0.145987),
# (('X[-1,1]=시사회', '0'), 0.353974),
# (('X[0,2]=사회에', '0'), 0.105447),
# (('X[-2,0]=시사회', '0'), -0.095421),
# (('X[-2,0]=시사회', '1'), 0.095421),
# (('X[-1,1]=사회에', '0'), 0.108413),
# (('X[0,2]=회에서', '0'), 0.108413),
# (('X[-2,0]=사회에', '0'), 0.079413),
# (('X[-1,1]=회에서', '0'), 0.079413),
# (('X[0,2]=에서보', '0'), 0.562773)]때로 ‘0’, ‘1’ 이 아닌 ‘명사’, ‘조사’와 같은 str 을 label 로 이용할 수도 있습니다. 하지만 그 값이 모두 ‘0’, ‘1’ 로 치환되는데, 이를 확인하기 위해서는 debugger.labels 를 확인합니다.
print(debugger.labels)
# {'0': '0', '1': '1'}pycrfsuite 를 이용한 한국어 띄어쓰기 교정기 구현체
위 과정들을 정리하고, 몇 가지 기능을 추가한 구현체를 올려두었습니다. 설치는 pip install 이 가능합니다.
pip install pycrfsuite_spacing
튜토리얼 당시의 버전은 1.0.2 입니다.
Templates 과 character feature transformer 를 만듭니다.
from pycrfsuite_spacing import TemplateGenerator
from pycrfsuite_spacing import CharacterFeatureTransformer
from pprint import pprint
templates = TemplateGenerator(
begin=-2,
end=2,
min_range_length=3,
max_range_length=3)
to_feature = CharacterFeatureTransformer(templates)Character feature transformer 와 sent_to_xy 함수를 이용하여 문장을 x 와 y 로 변환합니다.
from pycrfsuite_spacing import sent_to_xy
x, y = sent_to_xy('이것도 너프해 보시지', to_feature)
pprint(x)
# [['X[0,2]=이것도'],
# ['X[-1,1]=이것도', 'X[0,2]=것도너'],
# ['X[-2,0]=이것도', 'X[-1,1]=것도너', 'X[0,2]=도너프'],
# ['X[-2,0]=것도너', 'X[-1,1]=도너프', 'X[0,2]=너프해'],
# ['X[-2,0]=도너프', 'X[-1,1]=너프해', 'X[0,2]=프해보'],
# ['X[-2,0]=너프해', 'X[-1,1]=프해보', 'X[0,2]=해보시'],
# ['X[-2,0]=프해보', 'X[-1,1]=해보시', 'X[0,2]=보시지'],
# ['X[-2,0]=해보시', 'X[-1,1]=보시지'],
# ['X[-2,0]=보시지']]
print(y)
# ['0', '0', '1', '0', '0', '1', '0', '0', '1']모델을 학습하기 위해서 list of str (like) 형태의 docs 와 model_path 를 입력합니다. 목적에 알맞게 configuration parameters 도 조절합니다.
from pycrfsuite_spacing import PyCRFSuiteSpacing
correct = PyCRFSuiteSpacing(
to_feature,
feature_minfreq=5,
max_iterations=100,
l1_cost=1.0,
l2_cost=1.0)
model_path = 'package_test.crfsuite'
correct.train(docs, model_path)문장 교정은 함수 call 을 하던지 correct 함수를 실행합니다.
correct('이건진짜좋은영화라라랜드진짜좋은영화')
# '이건 진짜 좋은 영화 라라랜드 진짜 좋은 영화'
correct.correct('이건진짜좋은영화라라랜드진짜좋은영화')
# '이건 진짜 좋은 영화 라라랜드 진짜 좋은 영화'학습된 모델을 load 합니다.
model = PyCRFSuiteSpacing(to_feature)
model.load_tagger(model_path)
model('이건진짜좋은영화라라랜드진짜좋은영화')
# '이건 진짜 좋은 영화 라라랜드 진짜 좋은 영화'