Classifiers 는 input vector \(x\) 가 주어지면 이에 해당하는 클래스를 분류합니다. 그런데 입력값이 벡터가 아니라 \(x = [x_1, x_2 ,\ldots, x_n]\) 같은 시퀀스일 수 있습니다. 이때 가장 적절한 클래스를 시퀀스 \(y = [y_1, y_2, \ldots, y_n]\) 들을 분류하는 문제를 sequential labeling 이라 합니다. 이를 위해 Hidden Markov Model (HMM) 도 이용되었습니다만, HMM 은 많은 문제점을 지니고 있습니다. 이후 Conditional Random Field (CRF) 와 같은 maximum entropy classifiers 들이 제안되었고, Word2Vec 이후 단어 임베딩 기술이 성숙하면서 Recurrent Neural Network (RNN) 계열도 이용되고 있습니다. 최근에는 Transformer 를 이용하는 BERT 까지도 sequential labeling 에 이용됩니다. 이번 포스트에서는 이 문제를 위하여 sparse representation 을 이용하는 알고리즘들에 대해서 살펴봅니다.
Sequential labeling
일반적인 머신 러닝의 분류기는, 하나의 입력 벡터 \(x\) 에 대하여 하나의 label 값 \(y\) 를 return 합니다. 그런데 입력되는 \(x\) 가 벡터가 아닌 sequence 일 경우가 있습니다. \(x\) 를 길이가 \(n\) 인 sequence, \(x = [x_1, x_2, \ldots, x_n]\) 라 할 때, 같은 길이의 \(y = [y_1, y_2, \ldots, y_n]\) 을 출력해야 합니다. 각 \(y_i\) 에 대하여 출력 가능한 label 중에서 적절한 것을 선택하는 것이기 때문에 classification 에 해당하며, 데이터의 형식이 벡터가 아닌 sequence 이기 때문에 sequential data 에 대한 classification 이라는 의미로 sequential labeling 이라 부릅니다.
띄어쓰기 문제나 품사 판별이 대표적인 sequential labeling 입니다. 품사 판별은 주어진 단어열 \(x\) 에 대하여 품사열 \(y\) 를 출력합니다.
- \(x\) = [이것, 은, 예문, 이다]
- \(y\) = [명사, 조사, 명사, 조사]
띄어쓰기는 길이가 \(n\) 인 글자열에 대하여 [띈다, 안띈다] 중 하나로 이뤄진 Boolean sequence \(y\) 를 출력합니다.
- \(x\) = 이것은예문이다
- \(y\) = \([0, 0, 1, 0, 1, 0, 1]\)
이 과정을 확률모형으로 표현하면 주어진 \(x\) 에 대하여 \(P(y \vert x)\) 가 가장 큰 \(y\) 를 찾는 것 입니다. 이를 아래처럼 기술하기도 합니다. \(x_{1:n}\) 은 길이가 \(n\) 인 sequence 라는 의미이며, sequential labeling 알고리즘들은 아래의 식을 어떻게 정의할 것이냐에 따라 다양한 방법으로 발전하였습니다.
\[argmax_y P(y_{1:n} \vert x_{1:n})\]가장 간단한 방법은 각 \(x_i\) 별로 별도의 분류기를 이용하는 것입니다. 이 분류기는 Softmax regression, Support Vector Machine 혹은 그 어떤 것이던지 이용할 수 있습니다. \(f\)(은) = 조사 와 같은 함수를 학습할 수 있지만, 이는 모든 ‘은’이라는 단어가 반드시 ‘조사’라는 가정이 있어야 합니다. 하지만 한 단어는 다양한 품사를 가질 수 있습니다. 띄어쓰기 교정에서도 \(f\)(은) = \(1\) 이라는 모델이 학습되는 것인데, 모든 ‘은’ 다음에 띄어쓰는 것이 아니기 때문에 이러한 접근 방법은 옳지 않습니다. 더 좋은 방법은 ‘은’ 이라는 단어나 글자가 등장한 맥락을 입력값으로 함께 이용하는 것입니다.
v.s. sequence segmentation
Sequence 를 다루는 문제 중 하나로, sequence segmentation 이 있습니다. 이는 길이가 \(n\) 인 input sequence \(x_{1:n}\) 에 대하여 길이가 \(m \le n\) 인 output sequence \(y_{1:m}\) 을 출력하는 문제입니다. 대표적인 문제는 문장을 단어로 분리하는 토크나이저 입니다. 중국어권 연구에서는 주로 word segmentation 이라 부릅니다. 아래 예시처럼 \(7\) 개의 글자열이 입력되면 \(4\) 개의 단어열을 출력하는 것입니다. 띄어쓰기도 어절 단위에서의 sequence segmentation 이기도 합니다.
- \(x\) = ‘이것은예문이다’
- \(y\) = [이것, 은, 예문, 이다]
Sequence segmentation 은 sequential labeling 문제로 생각할 수도 있습니다. Output sequence 가 각 단어의 경계이면 됩니다. 아래의 예시처럼 각 단어의 시작 부분을 B 로, 그 외의 부분을 I 로 표현할 수도 있습니다.
- \(y\) = [B, I, B, B, I, B, I]
혹은 품사태그까지 한 번에 부여가 가능합니다. 아래처럼 각 단어의 시작 위치 태그 (B, I) 뿐 아니라 각 단어의 품사를 함께 부여할 수도 있습니다. 카카오 형태소 분석기 역시 음절 단위의 품사 태깅을 수행한다고 카카오의 블로그에서는 설명하고 있습니다 (블로그 참고)
- \(y\) = [B-Noun, I-Noun, B-Josa, B-Noun, I-Noun, B-Adjective, I-Adjective]
단 segmentation 을 위하여 글자 단위의 sequence labeling 을 할 때에는 각 글자가 독립적이지 않게 태깅하는 것이 중요합니다. 예문의 예 와 문은 한 단어로부터 등장하는 단어이기 때문입니다. 즉 예가 B-Noun 로 태깅되는 순간 문 역시 I-Noun 이 되어야 합니다.
Segmentation 으로의 sequence labeling 은 다른 포스트에서 다뤄보고, 이 포스트에서는 sequential labeling 에 이용된 전통적인 방법들의 발전 과정과 각 알고리즘의 차이점에 대하여 정리합니다.
Hidden Markov Model (HMM)
HMM (Krogh, 1994)^[1] 을 이용한 품사 판별기에 대해서는 이전의 포스트에서 다룬 적이 있습니다. 이 포스트에서는 HMM 의 원리를 간단히 정리하고, 품사 판별과 같은 sequential labeling 관점에서의 HMM 의 문제점에 대하여 정리합니다. HMM 은 \(P(y_{1:n} \vert x_{1:n})\) 을 아래처럼 정의합니다. 여기서 \(x\) 는 단어열, \(y\) 는 품사열 입니다.
\[P(y_{1:n} \vert x_{1:n}) := P(x_{1:n}, y_{1:n}) = \prod_i P(x_i \vert y_i) \times P(y_i \vert y_{i-1})\]HMM 은 Naive Bayes rules 을 이용하는데, 주어진 \(x\) 에 대한 \(y\) 의 확률이 아닌, 데이터에 \((x, y)\) 가 존재할 확률을 계산합니다. 그래서 HMM 을 generative model 이라 말합니다. 우리는 \(x\) 를 주어주고, 가장 적절한 \(y\) 를 판별해 달라고 말하지만, HMM 은 이를 간접적으로 계산합니다.
HMM 은 각 단어의 품사를 물어보는 질문에, 학습 데이터의 각 품사에서 해당 단어가 등장했던 확률값으로 단어의 품사를 추정합니다. \(P(이 \vert Josa) \ge P(이 \vert Noun)\) 이면 이 라는 글자를 Josa 로 판단합니다. 물론 모든 단어를 독립적으로 판단하지는 않습니다. Josa 다음에는 Josa가 등장하기 어려우니, 이런 경우는 \(P(y_i \vert y_{i-1})\) 에 의하여 배제될 가능성이 높습니다.
HMM 을 이용하는 대표적인 품사 판별기는 TnT 입니다. NLTK 의 엔진으로도 공개되어 있으며, 품사 판별을 위한 확률 식은 아래와 같습니다. 단어 단위에서는 unigram 의 정보 \(P(w_i \vert t_i)\) 만을 이용하지만, 품사 단위에서는 trigram 까지 이용하는 모델입니다.
\[P(t_{1:n} \vert w_{1:n}) = \prod_i P(w_i \vert t_i) \times P(t_i \vert t_{i-1}, t_{i-2})\]TnT 는 영어 단어의 품사를 추정하기 위한 모델입니다. 이 모델은 모르는 단어 (미등록단어 문제) 의 품사를 추정하기 위하여 단어의 끝 부분의 2, 3 글자 (suffix) 정보를 이용했습니다. 단어의 끝 부분이 -ed 라면 동사나 형용사의 과거형일 가능성이 높을 것입니다. 이러한 정보를 규칙 기반으로 이용하였는데, 이는 각 단어의 경계가 띄어쓰기로 나뉘어지는 영어의 특징을 이용한 것입니다.
그러나 HMM 은 품사 판별기로써의 약점이 여러 가지가 있습니다. 이 문제들에 대하여 간단히 정리해봅니다. 그리고 이 문제들은 HMM 뿐 아니라 많은 sequential labeling 알고리즘들의 문제이기도 하며, 이후의 모델들은 이를 해결하면서 발전하였습니다.
Out of vocabulary
첫번째 문제는 한 번도 보지 못한 단어는 제대로 인식할 방법이 없다는 것입니다. 이전의 포스트에서 다룬 것처럼 HMM 은 학습 데이터에 등장한 (단어, 품사) 정보를 확률 모델로 암기합니다. 그렇기 때문에 학습 데이터에 등장한 단어를 제대로 인식할 방법이 없습니다. 즉 모르는 단어 \(x_i\) 에 대해서는 \(P(x_i \vert y_i) = 0\) 입니다. 이는 단어를 있는 그대로 외웠기 때문입니다. 다른 모델들은 그 단어가 등장하는 문맥 정보를 학습하기 때문에 모르는 단어라도 비슷한 문맥이 입력되면 해당 단어의 품사를 어느 정도는 추정할 수 있습니다.
그러나 이 문제는 사용자 사전에 단어를 추가함으로써 간단하게 해결할 수 있습니다. 사용자에 의하여 단어와 품사 쌍 \((w, t)\) 를 특정 확률로 추가하고, \(\sum_w P(w \vert t) = 1\) 이 되도록 re-scaling 하면 됩니다.
Unguaranteed Independency Problem
두번째 문제는 매우 치명적입니다. 우리는 "오늘, 의, A, 는, ... "이라는 문장에서 A 라는 단어의 품사를 추정하기 위하여 앞, 뒤의 단어들의 정보를 이용합니다. 문맥 정보는 주로 앞, 뒤에 등장하는 단어들입니다. 하지만 HMM 은 \(P(y_i \vert y_{i-1})\) 에 대한 정보는 학습하여도 \((x_{i-1}, x_i)\) 의 정보는 학습하지 않습니다. 앞선 예시처럼 이 라는 단어는 명사, 조사, 형용사 등 다양한 품사를 가질 수 있기 때문에 \(x_i =\)이 의 품사 추정을 위해서는 앞, 뒤 단어를 살펴봐야 합니다. 하지만 HMM 은 그 앞에 등장한 단어의 품사 \(y_{i-1}\) 정보만 이용할 뿐입니다.
이러한 문제를 unguaranteed indeiendency problem 이라 합니다. 각 단어 \(x_i\) 가 서로 독립이라는 잘못된 가정을 한다는 의미입니다. 주로 sequential modeling 에서는 한 시점 주변의 스냅샷 정보를 이용하는 경우가 많은데, HMM 은 이러한 능력이 없습니다.
Number of words (Label bias)
세번째 문제도 치명적입니다. 앞의 예시처럼 실제로 학습데이터의 단어 이 의 확률은 \(P(이 \vert Josa)\) 이 \(P(이 \vert Noun)\) 보다 큽니다. 명사의 종류가 조사의 종류보다 압도적으로 많기 때문에 명사의 각 단어의 확률 \(P(w \vert Noun)\) 은 대체로 매우 작은 값입니다. 반대로 \(P(w \vert Josa)\) 는 매우 큰 값을 지닙니다. 아래는 세종 말뭉치 데이터의 일부에서의 각 품사 별 고유 단어의 개수 예시입니다.
| Tag | Number of unique words |
|---|---|
| Noun | 63968 |
| Verb | 3598 |
| Adverb | 3190 |
| Eomi | 1460 |
| Adjective | 849 |
| Exclamation | 464 |
| Josa | 158 |
| Determiner | 123 |
품사, 혹은 output value 에 따라 편향성 (bias) 이 생깁니다. 이때문에 확률적으로 특정 품사를 선호하는 현상이 발생합니다.
Local normalization (Label bias)
네번째 문제 역시 치명적입니다. 이 역시 output values 의 빈도수 때문에 발생하는 문제입니다. 만약 \(t_1\) 은 자주 이용되는 품사이기 때문에 그 다음에 등장하는 품사들은 그 종류가 30 가지 정도 된다고 가정합니다. 다른 품사 \(t_2\) 는 특정한 문맥에서만, 상대적으로 적게 이용되는 품사이기 때문에 그 다음에 등장하는 품사들의 종류 역시 3 가지 정도 작다고 가정합니다. 그러면 위의 문제처럼 일반적으로 \(P(t \vert t_1) \le P(t \vert t_2)\) 이게 됩니다. 하지만 \(t_2\) 는 가정한 것처럼 거의 등장하지 않았습니다.
즉, 실제 데이터의 분포를 보면 \((y_{i-1} = t_2, y_i = t)\) 의 경우가 매우 작음에도 불구하고 확률값은 더 크게 계산됩니다. 이는 매 시점 \(i\) 마다 \(P(y_{1:i} \vert x_{1:n})\) 까지의 확률을 정의하기 때문인데, 이를 local normalization 이라 합니다. Sequence 전체를 보기 전에 sub-sequence 에 대한 확률을 정의한다는 의미입니다.
Length bias
다섯번째 문제는 sequence segmentation 을 함께 푸는 경우에 발생하는 문제입니다. 아래처럼 \(x_{1:n}\) 에 대하여 \(y_{1:n}\) 이 출력되는 문제라면 output sequence 의 길이가 같기 때문에 \(P(y_0 \vert x)\) 나 \(P(y_1 \vert x)\) 의 스케일에 큰 차이가 없습니다.
- \(x\) = ‘이것은예문이다’
- \(y_0\) = [B-Noun, I-Noun, B-Josa, B-Noun, I-Noun, B-Adjective, I-Adjective]
- \(y_1\) = [B-Noun, I-Noun, I-Noun, B-Noun, I-Noun, B-Adjective, I-Adjective]
하지만 아래처럼 \(y_0\) 은 4 개의 단어열로, \(y_1\) 은 3 개의 단어열로 문장을 분해한다면 \(y_1\) 이 잘못된 문장임에도 불구하고 더 큰 확률을 가질 수 있습니다. HMM 은 \(2n\) 개의 확률의 곱으로 \(P(y_{1:n} \vert x_{1:n})\) 의 확률을 정의합니다. 그리고 각 확률은 1 이하의 값으로 정의됩니다. 1 보다 작은 숫자는 여러 번 곱할수록 그 값이 작아지기 때문에 확률적으로는 짧은 output sequence 에 더 큰 확률이 주어질 가능성이 높습니다. 그래서 HMM 은 길이가 긴 단어로 구성된 문장, 즉 최대한 적은 수의 단어들로 문장을 분해하려는 편향성이 생깁니다.
- \(y_0\) = [이것/Noun, 은/Josa, 예문/Noun, 이다/Adjective]
- \(y_1\) = [이것은/Noun, 예문/Noun, 이다/Adjective]
단, 이는 일단 문장이 제대로 된 단어열로 분해되었다는 가정을 할 때 입니다. 한국어는 표의 문자인 한자어를 일부 차용하는 언어이기 때문에 각 음절이 단어인 경우가 많습니다. 게다가 미등록단어 문제까지 발생합니다. 그렇기 때문에 HMM 을 이용하는 한국어 형태소 분석기에서 미등록단어 문제가 발생하면 학습데이터에 등장하는 단어가 포함된 가장 긴 단어를 선호할 가능성이 높습니다.
1, 2 번은 HMM 의 구조적 한계점이며, 3 - 5 번은 특정한 경우에 편향성이 생기는 문제입니다. 좋은 sequential labeling 은 주어진 \(x\) 에 대하여 편향성 없이 \(y\) 를 찾을 수 있어야 합니다. TnT 는 2000 년에 제안되었지만 HMM 기반 모델들은 주로 90 년대까지 이용되었습니다. 뒤이어 설명할 MEMM 같은 maximum entropy classifiers 들은 1, 2 번의 한계점을 극복하기 때문에 HMM 의 대안으로 이용되었고, HMM 기반 품사 판별 작업은 그 이후로 거의 이뤄지지 않았습니다.
Maximum Entropy Markov Model (MEMM)
2000 년에 ICML 에 Maximum Entropy Markov Model 이 제안됩니다 (McCallum et al., 2000) ^[4]. 이는 maximum entropy classifiers 에 속하는 모델로, softmax regression 형식의 classifier 를 의미합니다. 물론 MEMM 이 이런 종류의 첫번째 모델은 아니지만, MEMM 은 이러한 모델 시리즈의 중요한 랜드마크 역할을 하는 알고리즘입니다.
MEMM 과 CRF 에 대해서도 이전의 포스트에서 다뤘습니다. 그중, 중요한 내용들을 다시 알아봅니다.
Potential function
MEMM 에 대하여 이야기하려면 단어열 같은 category sequence 를 벡터로 표현하는 방법부터 알아야 합니다. HMM 은 (단어, 품사) 의 확률만을 계산하였기 때문에 단어열을 벡터 형식으로 변환할 필요는 없었습니다. 하지만 softmax regression 을 이용하는 MEMM 은 단어열을 벡터로 표현해야 했습니다. 이를 위하여 potential function 이 이용됬습니다. 이는 categorical 뿐 아니라 numerical sequence 도 벡터로 표현할 수 있는 방법입니다.
예를 들어 \(x = [3.2, 2.1, -0.5]\) 라는 길이가 3 인 sequence 에 대하여 아래의 필터 \(F_1\) 를 적용할 수 있습니다.
- \(x = [3.2, 2.1, -0.5]\) .
- \(F_1 = 1\) if \(x_i > 0\) else \(0\)
- \(x_{vec} = [1, 1, 0]\) .
필터를 여러 개 이용할 수도 있습니다. 각 시점 \(i\) 에 대한 벡터의 크기는 필터의 개수와 같습니다.
- \(x = [3.2, 2.1, -0.5]\) .
- \(F_1 = 1\) if \(x_i > 0\) else \(0\)
- \(F_2 = 1\) if \(x_i > 3\) else \(0\)
- \(x_{vec} = [(1, 1), (1, 0), (0, 0)]\) .
이 필터가 potential function 입니다. Potential function 은 categorical variable 에 대해서도 적용이 가능합니다.
- \(x = [이것, 은, 예문, 이다]\) .
- \(F_1 = 1\) if \(x_{i-1} =\) ‘이것’ & \(x_i =\) ‘은’ else \(0\)
- \(F_2 = 1\) if \(x_{i-1} =\) ‘이것’ & \(x_i =\) ‘예문’ else \(0\)
- \(F_3 = 1\) if \(x_{i-1} =\) ‘은’ & \(x_i =\) ‘예문’ else \(0\)
- \(x_{vec} = [(0, 0, 0), (1, 0, 0), (0, 0, 1), (0, 0, 0)]\) .
앞서 달아둔 label \(y_{i-1}\) 를 함께 이용하기 위한 potential function 도 만들 수 있습니다.
- \(x = [이것, 은, 예문, 이다]\) .
- \(F_1 = 1\) if \(x_{i-1} =\) ‘이것’ & \(x_i =\) ‘은’ else \(0\)
- \(F_2 = 1\) if \(x_{i-1} =\) ‘이것’ & \(x_i =\) ‘예문’ else \(0\)
- \(F_3 = 1\) if \(x_{i-1} =\) ‘은’ & \(x_i =\) ‘예문’ else \(0\)
- \(F_4 = 1\) if \(x_{i-1} =\) ‘이것’ & \(x_i =\) ‘은’ & \(y_{i-1} =\) ‘명사’ else \(0\)
- \(F_5 = 1\) if \(x_{i-1} =\) ‘이것’ & \(x_i =\) ‘예문’ & \(y_{i-1} =\) ‘명사’ else \(0\)
- \(F_6 = 1\) if \(x_{i-1} =\) ‘은’ & \(x_i =\) ‘예문’ & \(y_{i-1} =\) ‘조사’ else \(0\)
Potential function 은 데이터를 암기하여 Boolean vector 로 표현하는 방법입니다. 단어열의 예시처럼 필터의 종류가 다양할 수 있기 때문에 주로 templates 으로 표현합니다. 예를 들어 \((x_{-2}, x_{-1}, x_{0})\) 은 앞의 두 단어와 현재의 단어를 모두 합하여 하나의 \(F_i\) 로 이용한다는 의미입니다. 그렇기 때문에 품사 판별과 같은 NLP tasks 에서는 potential function 에 의하여 매우 큰 차원의 벡터 공간이 만들어집니다. \((x_{-2}, x_{-1}, x_{0})\) 은 trigram space 입니다.
이 정보에 의하여 MEMM 은 단어열의 문맥을 features 로 이용할 수 있게 되었습니다. 이는 미등록단어에 대해서도 대처할 수 있도록 도와주는데, \(x_{0}\) 을 모르더라도 \((x_{-2}, x_{-1}, x_{1})\) 을 이용하면 \(x_0\) 을 짐작할 수 있습니다. 예를 들어 (오늘, 의, A, 은) 에서 A 는 명사일 것이라는 힌트를 앞, 뒤에 등장하는 단어만으로 짐작할 수 있게 된 것입니다. 단, 이때도 문장이 단어열로 제대로 분해되었다는 가정이 필요합니다.
하지만 이 방법은 bag-of-words model 처럼 각 차원이 어떤 의미인지 해석할 수 있다는 장점이 있습니다. 단점은 (오늘, 의, 메뉴) 나 (오늘, 의, 식단) 처럼 두 features 가 비슷한 의미를 지니고 있다는 정보를 학습할 수가 없습니다.
MEMM as Logistic regression
MEMM 은 potential function 을 이용하여 입력된 단어열 \(x_{1:n}\) 을 Boolean vector sequence \(h_{1:n}\) 으로 변환합니다. 그 뒤, 각 \(h_i\) 에 대하여 \(y_i\) 의 확률을 계산합니다.
\[P(y_{1:n} \vert x_{1:n}) = \prod_i^n P(y_i \vert h_i)\]\(P(y_i \vert h_i)\) 을 아래처럼 표현할 수 있습니다. \(P(y_i \vert h_i)\) 를 통하여 \(h_i\) 가 품사 혹은 클래스 \(k\) 일 확률을 계산합니다. 그리고 각 \(i\) 에 대하여 독립적인 \(n\) 번의 softmax regression 을 수행하여 전체의 확룰 \(P(y \vert h)\) 를 계산합니다. 이 때 \(\lambda\) 는 매 시점 \(i\) 마다 공통으로 이용됩니다.
\[P(y_{1:n} \vert x_{1:n}) = \prod_i^n \frac{exp(\lambda_{k}^T h_i)}{\sum_l exp(\lambda_{l}^T h_i)}\]이를 아래처럼 더 자세하게 기술할 수도 있습니다. \(f_j(x, i, y_i, y_{i-1})\) 은 “현재 시점 \(i\) 의 앞의 품사가 \(y_{i-1}\) 이고 지금 시점의 품사가 \(y_i\) 라면” 이라는 potential function 의 Boolean 값 입니다. 그리고 \(\lambda_j\) 는 그럴 경우의 점수, 즉 logistic regression 의 coefficient 입니다.
\[P(y \vert x) = \prod_{i=1}^{n} \frac{exp(\sum_{j=1}^{m} \lambda_j f_j (x, i, y_i, y_{i-1}))}{ \sum_{y^{`}} exp(\sum_{j^{`}=1}^{m} \lambda_j f_j (x, i, y_i^{`}, y_{i-1}^{`})) }\]마지막 수식은 복잡하긴 하지만, 결국 potential function 을 이용하여 \(x\) 를 sparse vector \(h\) 로 만든 뒤, softmax regression 을 수행한다는 의미입니다. 그렇기 때문에 MEMM 이라는 이름을 가졌습니다.
MEMM 은 discriminative model 인 softmax regression 형식입니다. Generative model 이 아니기 때문에 \(\lambda_j\) 는 \(f_j\) 빈도수의 영향을 덜받습니다. \(f_j\) 가 학습데이터에 몇 번 등장하지 않은 변수라 하더라도 그 정보가 명확하다면 매우 큰 값의 \(\lambda_j\) 가 학습될 것입니다. 하지만 이는 이론일 뿐, 현실은 softmax regression 을 근사학습하는 최적화 방법들에 의하여 약간의 frequency bias 가 있습니다.
MEMM as Markov Model
또한 MEMM 은 Markov Model 의 성질을 가지고 있습니다. 이는 \((y_{i-1}, y_i)\) 의 정보가 학습된다는 의미입니다. 위의 마지막 식의 \(f_j\) 는 아래처럼 두 종류의 성분으로 구분할 수 있습니다. \(f_p\) 는 \((x_i, y_i)\) 의 성분에 대한 features 이며, \(g_q\) 는 \((y_{i-1}, y_i)\) 성분에 대한 features 입니다. 두 종류의 features 는 구분될 수 있으며, MEMM 은 HMM 이 학습하는 정보를 모두 (이론적으로는) 학습할 수 있다는 의미입니다.
\[exp(\lambda^T h_j) = exp(\sum_p \mu_p f_p(x, i, y_i) + \sum_q \theta_q g_q(x, i, y_i, y_{i-1}))\]이처럼 현재 값 \(y_i\) 가 이전 값 \(y_{i-1}\) 에만 영향을 받는 모델을 Markov model 이라 합니다. 그렇기 때문에 MEMM 이라는 이름을 가지게 되었습니다.
그리고 \(P(y_{i-1}, y_i)\) 은 HMM 에서 transition probability 라 부릅니다. 이후 transion based model 을 설명할텐데, 이 모델들은 output sequence 의 bigram (혹은 그 이상)의 정보를 이용한다는 의미입니다.
Conditional Random Field (CRF)
MEMM 의 저자들은 바로 1년 뒤인 2001 년에 동일한 학회인 ICML 에서 개선된 버전의 모델, CRF 를 제안합니다 (Lafferty et al., 2001) ^[5]. MEMM 도 HMM 의 특징을 일부 가지고 있습니다. 그 결과 local normalization 문제에서 자유로울 수 없습니다. 이는 결국 문장 전체를 보지 않고 단편적인 정보만 여러번 보기 때문에 편향성이 생긴다는 의미인데, 이를 해결하기 위하여 CRF 는 길이가 \(n\) 인 \(y_{1:n}\) 을 찾기 위하여 단 한번의 softmax regression 을 수행합니다. 이를 global normalization 이라 합니다.
\[P(y \vert x) = \frac{exp(\sum_{j=1}^{m} \sum_{i=1}^{n} \lambda_j f_j (x, i, y_i, y_{i-1}))}{ \sum_{y^{`}} exp(\sum_{j^{`}=1}^{m} \sum_{i=1}^{n} \lambda_j f_j (x, i, y_i^{`}, y_{i-1}^{`})) }\]식은 \(\prod\) 가 \(\sum\) 으로 바뀐 것 뿐입니다. 그리고 \(x_{1:n}\) 로부터 만들 수 있는 \(y_{1:n}\) 의 종류는 매우 많기 때문에 가능성이 높은 후보 몇 개만을 효율적으로 찾아야 합니다. 이를 위하여 MEMM 과 CRF 모두 최적의 \(y_{1:n}\) 을 찾기 위해 beam search 를 이용합니다.
MeCab-ko 는 CRF 를 이용하는 대표적인 한국어 형태소 분석기 입니다. MeCab 은 일본어 분석을 위하여 제안된 형태소 분석기 입니다 (Kudo et al., 2004) ^[6]. 그리고 학습 데이터를 한국어로 변형한 버전이 MeCab-ko 입니다. 일본어 역시 word segmentation & labeling 을 동시에 해결해야 했기 때문에 local normalization 의 문제가 해결된 방법이 필요했습니다. 그렇기 때문에 CRF 모델이 이용되었습니다.
CRF as log-linear model
위 CRF 식을 변형할 수 있습니다. \(P(y \vert x)\) 에 log 를 씌우면 exponental 이 사라져 다음처럼 기술할 수 있습니다.
\[log P(y \vert x) = \sum_{j=1}^{m} \sum_{i=1}^{n} \lambda_j f_j (x, i, y_i, y_{i-1})) - log \sum_{y^{`}} exp(\sum_{j^{`}=1}^{m} \sum_{i=1}^{n} \lambda_j f_j (x, i, y_i^{`}, y_{i-1}^{`}))\]좀 더 간단히 기술하기 위하여 \(\sum_i \sum_j f_j(x, i, y)\) 를 \(F(x, y)\) 로, \(\lambda_j\) 를 \(\lambda\) 로 표현합니다. 물론 \(log \sum\) 에 의한 scaling 의 차이는 있습니다만, 이는 잠시 무시합니다.
\[log P(y \vert x) = <\lambda, (F(x,y)> - \sum_{y^{'}} <\lambda, F(x,y^{'})>\]\(F(x,y)\) 는 \(n \times m\) 크기의 sparse input vector 이며, \(\lambda^T F(x,y)\) 혹은 \(<\lambda, F(x,y)>\) 는 linear score function 입니다. Softmax regression 에서의 coefficient \(\lambda\) 와 input vector \(x\) 의 내적과 같은 형식입니다. \(F(x,y^{'})\) 은 input sequence \(x\) 로부터 만들 수 있는 output sequence \(y^{'}\) 의 feature vector representation 입니다.
CRF 는 학습데이터의 \((x, y)\) 를 이용하여 \(P(y \vert x)\) 가 최대화 되도록 학습합니다. 이는 true output sequence 인 \(y\) 의 \(F(x,y)\) 의 1 에 해당하는 \(\lambda\) 의 크기는 크게, 모든 output sequence \(y^{'}\) 의 \(F(x,y^{'})\) 의 1 에 해당하는 \(\lambda\) 의 크기는 작게 학습하는 것입니다.
Transition based sequence labeling
그런데 학습 목적식을 다르게 정의할 수도 있습니다. \(y^{'}\) 은 현재의 모델로 만들 수 있는 best output sequence 입니다. 이제부터는 \(\lambda\) 를 \(w\) 로 기술하겠습니다. 주로 maximum entropy model 에서 coefficient 를 \(\lambda\) 로 쓰며, transition based model 논문에서는 weight 라는 의미로 \(w\) 를 이용합니다.
Transition based models 는 아래의 식을 최대화 하는 방향으로 \(w\) 를 학습합니다.
\[w \cdot (F(x,y) - F(x,y^{'}))\]\(F\) 가 \((y_{i-1}, y_i)\) 의 정보를 이용한다면 아래처럼 기술할 수도 있습니다. 이러한 방식으로 기술된 모델을 주로 traisiton based model 이라 합니다.
\[w \cdot (\sum_i F(x,y_{i-1}, y_i) - F(x,y_{i-1}^{'}, y_{i}^{'}))\]Output sequence 의 bigram 이기 때문에 beam search 를 이용하기 매우 좋은 구조입니다. 학습이 완료된 뒤, 새로운 \(x\) 가 주어지면 다음의 점수가 가장 높은 \(\hat{y}\) 를 beam search 를 이용하여 탐색합니다.
\[\hat{y} = argmax_{y \in G(x)} w \cdot \sum_{i}^{n} F(x, y_{i-1}, y_i)\]만약 \(y = y^{'}\) 이라면 현재 모델이 \(x\) 에 대하여 정답값인 \(y\) 를 출력하기 때문에, 패러매터의 변화는 없습니다. \(y\) 가 \(y^{'}\) 이 아니라면, 이는 \(<\lambda, F(x, y^{'}>\) 가 \(<\lambda, F(x, y)>\) 보다 크다는 의미이니, \(F(x,y)\) 의 features 에 해당하는 \(\lambda\) 를 크게, \(F(x,y^{'})\) 에 해당하는 \(\lambda\) 를 작게 조절합니다.
Structured Support Vector Machine (StructuredSVM)
위 transition based model 의 식은 \(\hat{y}\) 가 \(y\) 가 되도록 만드는데만 노력합니다. 여기에 한 가지 조건을 더 더하여 \(\hat{y}\) 와 \(y\) 가 다를 경우, 그 점수의 차이가 어느 정도 이상이 되도록 유도할 수도 있습니다.
\(\rVert w \rVert^2 = 1\) 로 만든 뒤, 다음의 식을 학습합니다. \(\Delta(x,y,\hat{y})\) 는 \(y\) 와 \(\hat{y}\) 가 얼마나 틀렸는지를 나타내는 loss function 입니다. 만약 best output sequence 가 true output sequence 라면 0 을, 그렇지 않다면 0 보다 큰 값을 return 합니다. \(\rVert w \rVert^2 = 1\) 로 고정되어있기 때문에 \(\gamma\) 를 최대화 하라는 의미는 틀린 \(\hat{y}\) 는 큰 loss 를 가지도록 \(w\) 를 학습하라는 의미입니다. Structured SVM 은 \(\gamma\) 를 최대화 하도록 \(w\) 를 학습합니다.
\[w^T(F(x,y) - F(x,\hat{y})) \ge \gamma \Delta(x,y,\hat{y})\]이는 Support Vcetor Machine 같은 max margin classifiers 의 개념입니다. \(y\) 를 잘 맞추는 것도 좋지만, 잘못된 \(\hat{y}\) 와 정답 \(y\) 의 점수가 충분히 차이나도록 모델을 학습합니다. 이처럼 sequential labeling 에 max margin 개념을 도입한 모델을 structured SVM 이라 합니다 ^[7,8]. 단순한 \(y\) 값이 아닌 sequence 와 같은 구조체를 분별하는 classifiers 라는 의미입니다. 구문 구조를 판단하는 dependency parser 도 structured classifiers 의 하나입니다.
다시 돌아와서, transition based parser 의 식이 더 정교하게 정의되고 있습니다. 이 식을 hinge loss 형식으로 기술할 수도 있습니다. 이번에는 \((x_i, y_i)\) 는 학습 데이터, \(y\) 는 \(x_i\) 의 best output sequence 입니다.
\[\min_w \frac{1}{2} \rVert w \rVert^2 + \frac{C}{n} \sum_{i}^{n} \max_{y \in \mathcal{Y}} \left(0, \Delta(y_i, y) - \left( w \cdot F(x_i, y_i) - w \cdot F(x_i, y) \right) \right)\]위 식은 네 종류의 성분으로 구성되어 있습니다. \(\rVert w \rVert^2\) 은 L2 regularization 의 역할을 합니다. Weight vector \(w\) 의 크기가 지나치게 커져 over fitting 이 일어나는 것을 방지합니다. \(\Delta(y_i, y)\) 는 margin, threshold 의 역할을 합니다. \(<w, F(x_i, y_i)>\) 는 true sequence 의 점수이고, \(<w, F(x_i, y)>\) 는 best sequence 의 점수입니다. Best sequence 가 true sequence 가 아니면 최소한 \(\Delta(y_i, y)\) 이상 점수 차이가 나도록 \(w\) 를 유도합니다. 즉 structured SVM 은 margin 과 regularization 이 추가된 형태입니다.
Average perceptron
위의 (쉬운 버전의) transition based model 의 식은 \(w\) 에 대하여 1차 식이기 때문에 미분 가능합니다. 그러므로 gradient descent 계열의 방법을 이용하여 학습할 수 있습니다. 하지만 \(F(x,y)\) 에 의하여 만들어지는 feature space 는 매우 큰 공간의 sparse vector 입니다. 벡터의 대부분의 값이 0 일 경우에는 gradient descent 보다 효율적인 학습 방법들이 많습니다. 그 중 하나로 (Collins, 2002) 에 제안된 average perceptron 이 있습니다 ^[9].
이 방법은 perceptron 의 학습 방법과 매우 유사하지만, over fitting 의 방지를 위해서 average 개념을 도입합니다. 그 결과 sequential labeling 에서 CRF 나 structured SVM 과 비슷한 성능을 보이기도 했습니다. 그리고 논문 (Collins, 2002) 에서는 이 방법이 gradient descent 을 이용하지 않음에도 불구하고 제한된 반복만으로 \(w\) 가 수렴함을 증명했습니다.
Average perceptron 이 풀고 싶은 문제와 이를 위해 제안된 알고리즘입니다. \(w_k\) 는 처음 zero vector 로 초기화합니다. 매 번 \(F(x,y)\) 를 더하고 \(F(x, \hat{y})\) 를 빼서 \(w_{k+1}\) 로 업데이트 합니다. 그리고 매 순간의 \(w_k\) 를 \(v\) 에 누적합니다. 만약 \(\hat{y}\) 가 \(y\) 라면 \(w\) 는 변하지 않습니다. 만약 변한다면 그 변화량은 \(w\) 와 \(v\) 에 모두 저장됩니다. 그리고 학습이 끝나면 문장의 개수와 반복 횟수의 개수의 곱으로 \(v\) 를 나눠 최종 \(w\) 를 얻습니다.

이는 반복 횟수를 증가하면서 learning rate 를 낮춰가는 것으로 해석할 수 있습니다. 학습의 후반부로 갈수록 \(w\) 는 안정화 될 것이기 때문에 상대적으로 \(w_k\) 가 바뀌는 경우가 줄어들기 때문입니다.
Pegasos: Primal Estimation sub-GrAdient SOlver for SVM
Structured SVM 역시 sparse vector 에서 효율적으로 작동하는 학습 방법이 제안되었습니다. Pegasos 라는 이름의 이 알고리즘이 풀고 싶은 문제와 이를 위해 제안된 방법은 아래와 같습니다. 식은 복잡하지만, 자세히 살펴보면 average perceptron 에서 learning rate 가 정교화된 것과 비슷합니다.
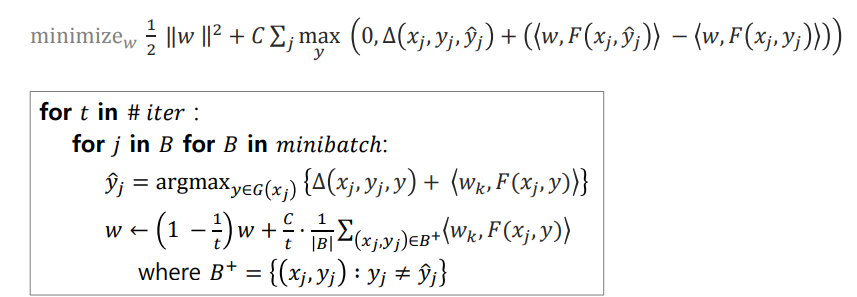
그리고 위의 식은 mini batch version 입니다. SVM 의 학습에 \(n \times n\) 크기의 kernel matrix 가 계산되어야 하지만, 데이터가 클 경우에는 학습 불가능한 경우가 많습니다. 이를 해결하기 위하여 여러가지 근사 알고리즘들이 제안되었는데 Pegasos 도 그들 중 하나 입니다. Mini-batch style 이기 때문에 메모리에는 \(w\) 만 보관하면 됩니다.
이 방법은 강원대학교의 이창기 교수님의 연구들에서 자주 등장하는 방법입니다. Structured SVM 을 자주 이용하셨는데, 그 때의 학습 방법으로 pegasos 를 사용하셨다고 여러 논문에 기술하셨습니다.
Recurrent Neural Network
위의 방법들은 단어열 \(x\) 를 potential function \(F\) 를 이용하여 sparse vector \(h\) 로 변환한 뒤 sequential labeling 을 수행하는 방법들입니다. 이들은 단어의 문맥 정보를 표현하기 위하여 bigram, trigram 들을 feature 로 이용합니다. 하지만 앞서 언급한 것처럼 단어나 n-grams 간의 의미적 유사성을 표현할 방법이 적습니다.
Word2Vec 과 같은 word embedding 은 이러한 정보를 distributed representation 으로 표현하는 장점이 있습니다. 그렇기 때문에 word sequence \(x\) 를 word embedding vector sequence 로 바꿀 수도 있습니다. 하지만 potential function 은 continuous vector space 에서 정의하기가 어렵기 때문에 위의 방법들을 이용하기 어렵습니다.
대신 neural network 계열을 이용할 수 있습니다. 특히 sequence modeling 에 뛰어난 GRU ^[10] 나 LSTM ^[11] 같은 Recurrent Neural Network (RNN) 계열 모델들을 이용할 수 있습니다. 이때는 문맥 정보가 hidden vector 에 저장되기를 바라는 것입니다. LSTM, GRU 와 같은 RNN 계열 모델들은 어느 정도 떨어진 단어의 정보를 hidden vector 에 저장할 수 있다고 알려져 있습니다. Bidirectional 모델을 이용하면 뒤에 등장한 단어의 정보도 함께 이용할 수 있습니다.
이때에도 \((x, y)\) 에 대한 score 를 정의할 수 있습니다.
\[score(x, y) = \sum_i f_{\theta} (x_i, y_i)\]GRU 나 LSTM 은 hidden vector \(h_i\) 에서 output value 를 선택하기 위하여 softmax 를 이용합니다. 이때의 확률값을 \(f_{\theta}(x_i, y_i)\) 로 이용할 수도 있습니다. 그렇다면 maximum likelihood 가 score function 이 됩니다.
그러나 위의 식에서는 \(y_{i-1}\) 과 \(y_i\) 의 상관성이 직접적으로 학습되지 않는데, 여기에 transition 개념을 더하면 아래와 같은 식이 됩니다. 이 식이 LSTM-CRF 입니다 ^[12].
\[score(x, y) = \sum_i A(y_{i-1}, y_i) + f_{\theta} (x_i, y_i)\]그리고 반드시 RNN 계열 모델을 이용하여 \(f_{\theta}\) 를 정의해야 하는 것도 아닙니다. Natural language processing from (almost) scratch 논문에서는 이를 위하여 feed forward network 를 그대로 이용하기도 합니다.
Word embedding vector 를 이용하는 모델들은 그 과정을 확인하기가 어렵습니다. 이는 사용자가 정보를 조작하기 어렵다는 것을 의미하기도 합니다. 하지만 전통적인 모델들보다 단어의 의미적인 정보를 잘 표현할 수 있습니다.
학습 데이터에 등장하지 않았던 단어에 대해서도 word embedding vector 를 제대로 정의할 수만 있다면 품사 추정도 원활히 이뤄집니다. 단 input sequence 의 단어의 벡터가 정의가 되어야 합니다. 즉 neural network 기반 모델이라 하여 미등록단어 문제가 완전히 해결되는 것도 아닙니다. Embedding vector 수준에서는 여전히 미등록단어 문제가 발생합니다. 이러한 내용들에 대해서는 다른 포스트에서 정리할 예정입니다.
References
- [1] Krogh, A. (1994). Hidden markov models for labeled sequences. In Proceedings of the 12th IAPR International Conference on Pattern Recognition, Vol. 3-Conference C: Signal Processing (Cat. No. 94CH3440-5), volume 2, pages 140–144. IEEE
- [2] 카카오 형태소 분석기 github, blog
- [3] Brants, T. (2000, April). TnT: a statistical part-of-speech tagger. In Proceedings of the sixth conference on Applied natural language processing (pp. 224-231). Association for Computational Linguistics.
- [4] McCallum, A., Freitag, D., and Pereira, F. C. (2000). Maximum entropy markov models for information extraction and segmentation. In Icml, volume 17, pages 591–598.
- [5] Lafferty, J., McCallum, A., and Pereira, F. C. (2001). Conditional random fields: Probabilistic models for segmenting and labeling sequence data.
- [6] Kudo, T., Yamamoto, K., & Matsumoto, Y. (2004). Applying conditional random fields to Japanese morphological analysis. In Proceedings of the 2004 EMNLP
- [7] Taskar, B., Klein, D., Collins, M., Koller, D., & Manning, C. (2004). Max-margin parsing. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing.
- [8] Tsochantaridis, I., Joachims, T., Hofmann, T., and Altun, Y. (2005). Large margin methods for structured and interdependent output variables. Journal of machine learning research
- [9] Collins, M. (2002, July). Discriminative training methods for hidden markov models: Theory and experiments with perceptron algorithms. In Proceedings of the ACL-02 EMNLP 2002
- [10] Cho, K., Van Merri ̈enboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., and Bengio, Y.(2014). Learning phrase representations using rnn encoder-decoder for statistical machine translation.arXiv preprint arXiv:1406.1078.
- [11] Hochreiter, S. and Schmidhuber, J. (1997). Long short-term memory. Neural computation, 9(8):1735–1780.
- [12] Lample, G., Ballesteros, M., Subramanian, S., Kawakami, K., and Dyer, C. (2016). Neural architectures for named entity recognition. arXiv preprint arXiv:1603.01360
- [13] Collobert, R., Weston, J., Bottou, L., Karlen, M., Kavukcuoglu, K., & Kuksa, P. (2011). Natural language processing (almost) from scratch. Journal of machine learning research, 12(Aug), 2493-2537.