GloVe 는 Word2Vec 과 더불어 자주 이용되는 word embedding 방법입니다. Word2Vec 과의 차이점에 대하여 알아보고, Python 의 구현체인 glove_python 의 특징에 대해서도 살펴봅니다. 그리고 glove_python 을 이용하여 좋은 학습 결과를 얻기 위한 방법에 대해서도 이야기합니다.
Brief reviews of Word2Vec
Word2Vec 은 Softmax regression 을 이용하여 단어의 의미적 유사성을 보존하는 embedding space 를 학습합니다. 문맥이 유사한 (의미가 비슷한) 단어는 비슷한 벡터로 표현됩니다. ‘cat’ 과 ‘dog’ 의 벡터는 매우 높은 cosine similarity 를 지니지만, 이들은 ‘topic modeling’ 의 벡터와는 매우 작은 cosine similarity 를 지닙니다.
Word2Vec 은 softmax regression 을 이용하여 문장의 한 스냅샷에서 기준 단어의 앞/뒤에 등장하는 다른 단어들 (context words) 이 기준 단어를 예측하도록 classifier 를 학습합니다. 그 과정에서 단어의 embedding vectors 가 학습됩니다. Context vector 는 앞/뒤 단어들의 평균 임베딩 벡터 입니다. [a, little, cat, sit, on, the, table] 문장에서 context words [a, little, sit, on] 를 이용하여 cat 을 예측합니다.
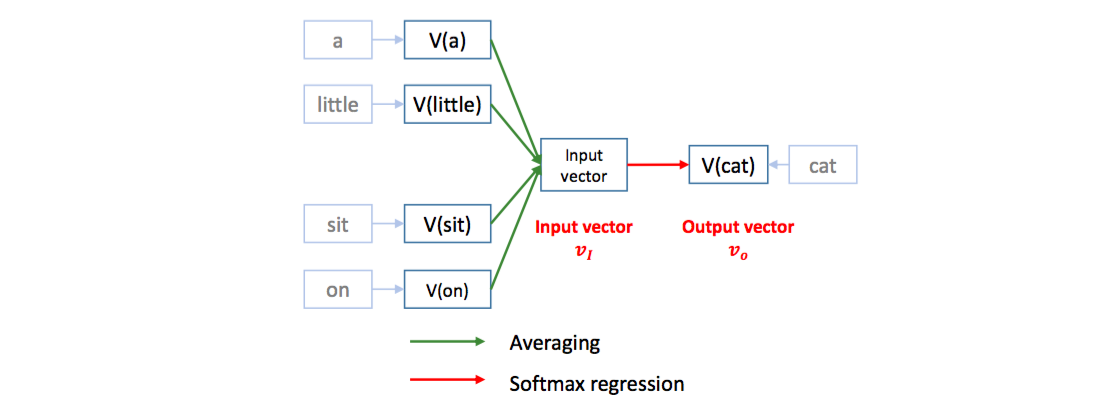
이는 cat 의 임베딩 벡터를 context words 의 평균 임베딩 벡터에 가깝도록 이동시키는 역할을 합니다. 비슷한 문맥을 지니는 dog 도 비슷한 context words 의 평균 임베딩 벡터에 가까워지기 때문에 cat 과 dog 의 벡터가 비슷해집니다.
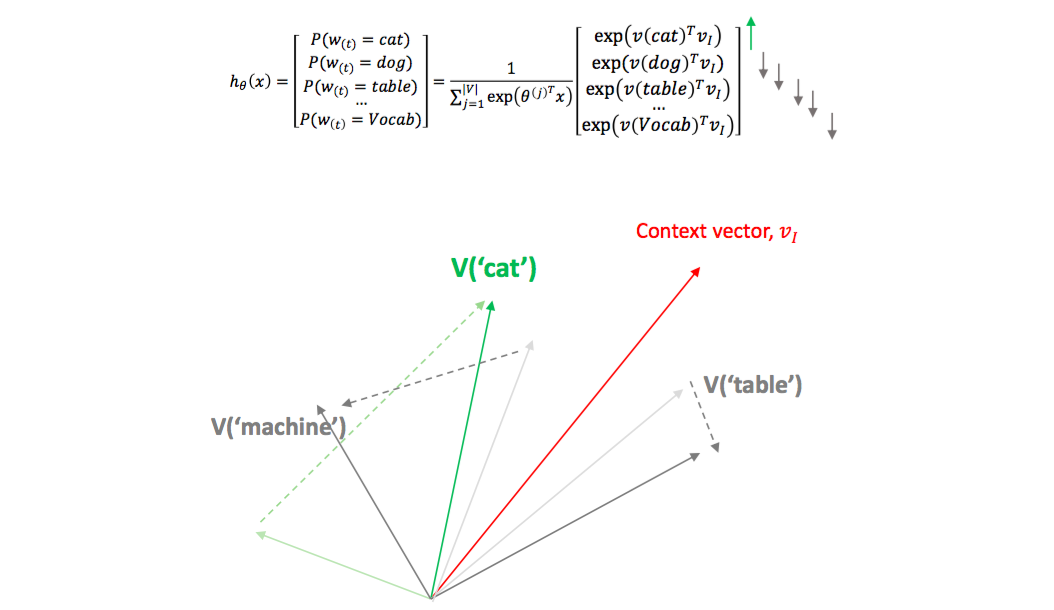
Word2Vec 은 context words distribution 이 비슷한 두 단어가 비슷한 임베딩 벡터를 지니도록 학습함과 동시에, co-occurrence 가 높은 단어들이 비슷한 임베딩 벡터를 지니도록 학습합니다. cat 이라는 기준 단어와 그 주위의 context words 간의 내적을 크게 만들어야 하기 때문입니다. 그러나 cat 과 dog 의 context words 가 cat, dog 과 가까워지기는 어렵습니다. sit 이라는 단어는 cat, dog 외에도 다양한 문맥에서 등장하기 때문입니다. 그리고 어느 문맥에나 등장하는 a, the, -은, -는, -이, -가 와 같은 단어들은 여기저기에서 끌어 당기다보니 (여러 단어의 문맥 단어로 등장하다보니) 그들은 특별한 문맥을 지니지 못합니다. (Levy & Goldberg, 2014) 에서 Word2Vec Positive PMI 로 해석되었습니다. 특별한 문맥이 없는 단어는 PMI vector 가 0 에 가깝습니다. 즉 어떤 단어에도 영향을 주기가 어렵습니다.
이외의 자세한 Word2Vec 의 설명은 이전 Word2Vec 포스트와 (Levy & Goldberg, 2014) 리뷰를 참고하세요.
GloVe
GloVe 는 Word2Vec 이 제안된 다음 해, Jeffrey Pennington, Richard Socher, Christopher D. Manning 에 의해 제안된 또 다른 word embedding 방법입니다. 무려 딥러닝의 그 Socher 와 Stanford NLP 의 Manning 이 저자입니다.
Loss function
Word2Vec 은 문장에서 \(words_{i-w,i+w}\) 의 스냅샷을 만들어 Softmax regression 을 이용하여 단어들의 임베딩 벡터를 학습합니다. Word2Vec 은 하나의 기준 단어의 단어 벡터로 문맥 단어의 벡터를 예측하는 모델입니다.
GloVe 의 단어 벡터 학습 방식은 이와 비슷하면서도 다릅니다. Co-occurrence 가 있는 두 단어의 단어 벡터를 이용하여 co-occurrence 값을 예측하는 regression 문제를 풉니다. 아래는 GloVe 의 목적식입니다. \(x_ij\) 는 두 단어 \(w_i, w_j\) 의 co-occurrence 입니다. Window 안에 함께 등장한 횟수입니다.
\[Loss = \sum f(x_{ij}) \times \left( w_i^t w_j + b_i + b_j - log(x_{ij}) \right)^2\]단어 \(w_i\) 와 \(w_j\) 의 벡터의 곲에 각 단어의 bias 인 \(b_i, b_j\) 를 더한 값이 co-occurrence 의 log 값과 비슷해지도록 \(w_i, w_j, b_i, b_j\) 를 학습합니다. 위 loss function 에서 \(b_i, b_j\) 가 0 이라면, 두 단어의 벡터의 곲이 co-occurrence 의 log 값이 되는 것입니다. Co-occurrence 가 높을수록 두 단어 벡터는 비슷해져야 합니다. Bias, \(b_i, b_j\) 는 빈번하게 등장하는 단어의 기본 빈도수 역할을 합니다.
\(w_i\) 가 cat 이나 dog 이고, \(w_j\) 이 sit, animal, pet 처럼 cat 과 dog 에 공통적으로 등장하는 context words 라면, \(w_j\) 에 의하여 cat 과 dog 은 비슷한 벡터를 학습하게 됩니다. 결국 Word2Vec 과 비슷한 학습 결과가 유도됩니다 (이후 Levy and Goldberg 는 GloVe 와 Word2Vec 이 이론적으로는 같음을 증명합니다).
Weighted error
그런데 단어의 빈도수는 지수 분포를 따릅니다. 몇 개의 단어들이 큰 빈도수를 지니며 대부분의 단어들은 작은 빈도수를 지닙니다. 그렇기 때문에 위 loss function 은 다수의 infrequent words 에 더 신경을 쓰는 형태가 됩니다.
어느 정도의 frequency 를 지니는 단어들 (\(x_{ij} > x_{max}\)) 에 대해서는 \(\left( w_i^t w_j + b_i + b_j - log(x_{ij}) \right)^2\) 만큼의 error 를 그대로 학습에 이용하지만, infrequent words 에 대해서는 error 의 중요도를 낮춰서 학습에 이용합니다. GloVe 에서 제안된 방법은 \(x_{max}\) 보다 작은 co-occurrence 에 대해서는 \(\frac{x}{x_{max}}^{\frac{3}{4}}\) 만큼 weight 를 곱하여 error 를 학습에 이용합니다.
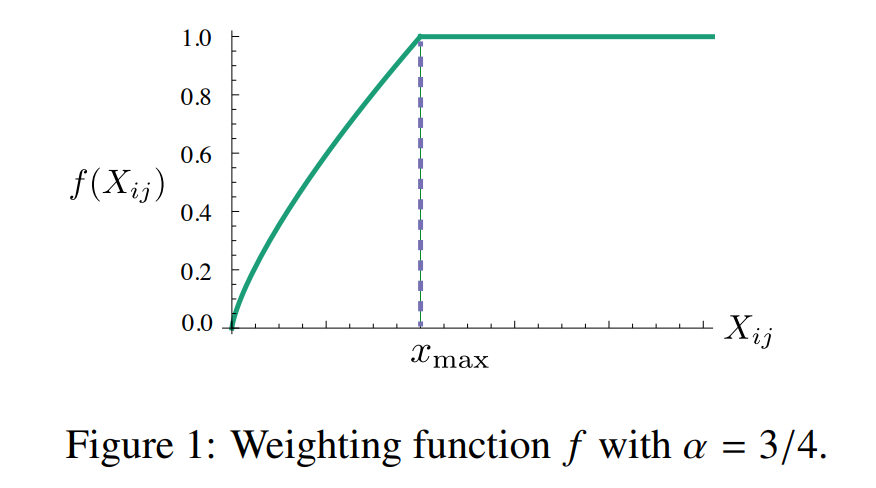
Weighted co-occurrence
\(w_{[i-w:i+w]}\) 에서 \(w_i\) 와 가까울수록 연관이 높은 단어일 것입니다. \(w_i\) 와 얼만큼 떨어져서 함께 등장했는지에 따라 차등적인 co-occurrence 를 부여합니다. 간단한 방법으로, \(\frac{w-j+1}{w}\) 의 weight 를 부여하여 co-occurrence 를 계산할 수 있습니다. 1, 2, 3 칸 뒤에 등장하는 단어에 대하여 [3/3, 2/3, 1/3] 의 weight 로 co-occurrence 를 계산합니다.
Python package
Stanford NLP group 에서 GloVe 의 코드를 github 에 올려뒀습니다. 여기에서는 c 로 구현된 구현체만 제공합니다.
Python 환경에서 GloVe 를 이용하시고 싶으신 분은 다른 구현체를 이용하실 수 있습니다. 이 구현체는 pip install 이 가능합니다.
pip install glove_python
다음 장에서 이 Python 구현체를 이용하여 GloVe 를 학습해 봅니다.
Experiments
Use Python GloVe
이번에도 2016-10-20 의 하루치 뉴스 데이터를 이용하여 GloVe 를 학습합니다. 위 구현체는 co-occurrence matrix 를 fit 함수의 input 으로 이용합니다.
class Glove(object):
"""
Class for estimating GloVe word embeddings using the
corpus coocurrence matrix.
"""
def fit(self, matrix, epochs=5, no_threads=2, verbose=False):
"""
Estimate the word embeddings.
Parameters:
- scipy.sparse.coo_matrix matrix: coocurrence matrix
- int epochs: number of training epochs
- int no_threads: number of training threads
- bool verbose: print progress messages if True
"""
...
우리가 직접 co-occurrence matrix 를 만들어야 합니다.
soynlp 에 co-occurrence matrix 를 만드는 함수를 만들어 두었습니다. 이를 이용하여 co-occurrence matrix 를 만듭니다.
Tokenization 은 미리 해두었던 corpus 입니다. sent_to_word_contexts_matrix 에 list of str 형식의 sentences 를 입력하면 (1) co-occurrence matrix 인 x 와 (2) list of str 형식인 vocabulary list (idx2vocab) 가 return 됩니다. 앞, 뒤 3 칸을 windows 로 이용하였으며, 최소한 10 번 이상 등장한 단어에 대해서만 co-occurrence matrix 를 만듭니다. Dynamic weight 를 True 로 설정하면 [1, 2/3, 1/3] 의 weight 로 co-occurrence 를 계산합니다.
36,002 개의 단어에 대하여 co-occurrence matrix 가 만들어집니다.
from soynlp.utils import DoublespaceLineCorpus
from soynlp.vectorizer import sent_to_word_contexts_matrix
corpus_path = '2016-10-20_article_all_normed_ltokenize.txt'
corpus = DoublespaceLineCorpus(corpus_path, iter_sent=True)
x, idx2vocab = sent_to_word_contexts_matrix(
corpus,
windows=3,
min_tf=10,
tokenizer=lambda x:x.split(), # (default) lambda x:x.split(),
dynamic_weight=True,
verbose=True)
print(x.shape) # (36002, 36002)이 구현체는 반드시 scipy.sparse.coo_matrix 를 input 으로 입력해야 합니다. x 는 csr_matrix 이기 때문에 tocoo() 를 이용하여 coo matrix 로 변환해줍니다.
학습에 이용할 threads 의 개수는 4 로 설정하였습니다. Epochs 의 숫자는 5 정도면 충분합니다. 더 크게 설정하여도 큰 변화는 없습니다. \(x_{max}\) 는 30 으로 설정합니다.
from glove import Glove
glove = Glove(no_components=100, learning_rate=0.05, max_count=30)
glove.fit(x.tocoo(), epochs=5, no_threads=4, verbose=True)유사어 검색을 위해서는 sparse matrix 의 각 row, column index 에 해당하는 vocabulary 의 정보가 필요합니다. dict[str] = int 형식인 dictionary 를 add_dictionary 함수를 통하여 입력합니다.
dictionary = {vocab:idx for idx, vocab in enumerate(idx2vocab)}
glove.add_dictionary(dictionary)Gensim 의 Word2Vec 처럼 most_similar 함수를 이용할 수 있습니다. 구현체가 자신과 같은 단어는 제외하고 출력합니다. 비슷한 number 개의 단어를 찾아주라고 입력하면 number - 1 개의 단어를 return 합니다.
Word2Vec 예시에서도 살펴보았던 단어들에 대하여 아래처럼 유사한 단어 벡터들을 탐색합니다.
words = '아이오아이 아프리카 밴쯔 박근혜 뉴스 날씨 이화여대 아프리카발톱개구리'.split()
for word in words:
print('\n{}'.format(word))
pprint(glove.most_similar(word, number=10))‘아이오아이’나 ‘아프리카’의 경우 몇 개의 단어들은 이해가 되지만, 몇 개의 단어들은 문맥에 맞지 않습니다. 다른 단어들도 마찬가지입니다. 가수 ‘백아연’이 2016-10-20 에 ‘대통령’과 함께 등장할 일은 없습니다. 기사가 나오는 섹션도 다릅니다.
| 아이오아이 | 아프리카 | 밴쯔 | 박근혜 |
|---|---|---|---|
| 샤이니 (0.891588) | 신체 (0.877876) | 마이크로소프트 (0.942061) | 대통령 (0.860834) |
| 너무너무너무 (0.861926) | 터키 (0.864901) | 주택금융공사 (0.939728) | 역적패당 (0.841314) |
| 싼타페 (0.854505) | 아내 (0.860654) | 선례 (0.936310) | 석적읍 (0.830594) |
| 송정수 (0.849985) | 의회 (0.852169) | 왕비 (0.931265) | 최완현 (0.826716) |
| 빅브레인 (0.843333) | 정연 (0.843457) | 김승우 (0.931085) | 백아연 (0.818449) |
| 김규종 (0.837954) | 자율주행차 (0.837520) | 저커버그 (0.930375) | 김준배 (0.818283) |
| 나토 (0.835242) | 외부 (0.835920) | 양주신도시 (0.929878) | 박준형 (0.818104) |
| 신용재 (0.831438) | 각자 (0.835129) | 강우 (0.921500) | 백승렬 (0.816602) |
| 당국자 (0.831280) | 이탈리아 (0.830159) | 전북도 (0.921220) | 정권 (0.816588) |
| 뉴스 | 날씨 | 이화여대 | 아프리카발톱개구리 |
|---|---|---|---|
| 현입니다 (0.909248) | 섭외 (0.825857) | 최경희 (0.863146) | 유전체 (0.901772) |
| 가치 (0.888860) | 멜로디 (0.801183) | 현대상선 (0.849251) | 효주 (0.890873) |
| 브레이브바트 (0.888482) | 바위 (0.789684) | 분양시장 (0.827459) | 너무너무너무 (0.885115) |
| 돈이 (0.881404) | 담배 (0.781898) | 안산시 (0.800298) | 소유자 (0.879585) |
| 머니 (0.871076) | 오해 (0.760772) | 이대 (0.797361) | 민주주의 (0.867238) |
| 보이는 (0.862071) | 안전사고 (0.754978) | 인도네시아 (0.782897) | 뜻밖 (0.863073) |
| 정시내 (0.856998) | 중징계 (0.749272) | 의회 (0.780713) | 아내 (0.859593) |
| 미란다 (0.829753) | 쌀쌀 (0.748736) | 스크린도어 (0.770524) | 숫자 (0.858837) |
| 머니투데이 (0.828635) | 미미 (0.748644) | 멕시코 (0.768644) | 나비 (0.857669) |
같은 데이터에 대해서 Word2Vec 이나 co-occurrence + PMI 를 이용한 결과는 매우 납득이 되지만, GloVe 의 학습 결과는 대체적으로 불만족 스럽습니다. 구현체의 특징일 수도 있습니다.
epochs, max_count 를 조절하여도 그 경향은 비슷하였습니다.
Stanford github 의 구현체와 비교해봐야 GloVe 에 대해서 알 것 같습니다.
그럼에도 몇 가지 특징들에 대해서 살펴보도록 하겠습니다.
Levy & Goldberg 는 GloVe 의 bias \(b_i\) 가 단어 \(w_i\) 의 빈도수에 비슷하게 학습이 된다고 설명합니다 (이후 리뷰할 논문 중 하나입니다). 실제로 bias 와 frequency 간의 관계가 있는지 확인해 보았습니다.
빈도수가 큰 단어들에 대해서는 확실히 frequency 와의 상관관계가 있습니다. 그러나 빈도수가 작아질수록 상관성이 적어집니다.
| 빈도수 기준 구간 | correlation(bias, frequency) |
|---|---|
| 0 ~ 200 | 0.842055 |
| 200 ~ 400 | 0.000998 |
| 400 ~ 600 | 0.043573 |
| 600 ~ 800 | 0.101054 |
| 800 ~ 1000 | 0.015101 |
| 1000 ~ 1200 | -0.034661 |
| 1200 ~ 1400 | -0.125970 |
| 1400 ~ 1600 | 0.048151 |
| 1600 ~ 1800 | 0.080136 |
| 1800 ~ 2000 | -0.071327 |
| 2000 ~ 2200 | 0.074374 |
| 2200 ~ 2400 | 0.076970 |
| 2400 ~ 2600 | 0.009619 |
| 2600 ~ 2800 | 0.093729 |
| 2800 ~ 3000 | -0.065978 |
| 3000 ~ 3200 | 0.041012 |
| 3200 ~ 3400 | 0.073790 |
| 3400 ~ 3600 | 0.120550 |
| 3600 ~ 3800 | 0.000758 |
| 3800 ~ 4000 | -0.068946 |
Use only nouns
위의 학습 결과가 좋지 않았던 이유로, ‘-입니다, -은, -는’과 같은 문법어들에 의하여 상관이 없는 단어들이 한 곳에 뭉쳐질 수도 있겠다는 생각을 하였습니다. 문장에서 명사만을 추린 뒤, 다시 한 번 GloVe 를 학습하였습니다.
24,907 개의 명사 간의 co-occurrence matrix 가 만들어집니다.
corpus_path = '2016-10-20_article_all_normed_nountokenized.txt'
corpus = DoublespaceLineCorpus(corpus_path, iter_sent=True)
x, idx2vocab = sent_to_word_contexts_matrix(
corpus,
windows=3,
min_tf=10,
tokenizer=lambda x:x.split(), # (default) lambda x:x.split(),
dynamic_weight=True,
verbose=True)
print(x.shape) # (24907, 24907)
glove = Glove(no_components=100, learning_rate=0.05, max_count=30)
glove.fit(x.tocoo(), epochs=5, no_threads=4, verbose=True)
dictionary = {vocab:idx for idx, vocab in enumerate(idx2vocab)}
glove.add_dictionary(dictionary)명사만을 이용하여 학습하니 조금은 더 좋은 학습 결과가 나옵니다. LDA 처럼 좋은 학습 결과를 만들기 위해서는 불필요한 단어들을 제거하는 전처리 과정을 잘 거쳐야 하는 것 같습니다.
| 아이오아이 | 아프리카 | 밴쯔 | 박근혜 |
|---|---|---|---|
| 신용재 (0.788213) | 밴쯔 (0.764979) | 대도서관 (0.814754) | 역적패당 (0.873995) |
| 완전체 (0.783201) | 동남아시아 (0.627443) | 아프리카 (0.764979) | 대통령 (0.788461) |
| 너무너무너무 (0.746413) | 댈러스 (0.618848) | 주간아이돌 (0.716317) | 2002년 (0.731508) |
| 성진환 (0.661771) | 중동 (0.611323) | 관료 (0.699244) | 취임식 (0.728809) |
| 에이핑크 (0.653405) | 뉴욕증시 (0.582824) | 남미 (0.697823) | 비선 (0.717803) |
| 정채연 (0.651380) | 자원봉사단 (0.582330) | 바이어 (0.693456) | 방북 (0.712427) |
| 공포증 (0.614557) | 매체들 (0.574021) | 중남미 (0.689812) | 핵심사업 (0.703182) |
| 몬스타엑스 (0.600836) | 비상식량 (0.561443) | 이천시 (0.677001) | 노무현 (0.703076) |
| 김규 (0.600183) | 현장경영 (0.558286) | 캄보디아 (0.674063) | 전진 (0.686775) |
| 뉴스 | 날씨 | 이화여대 | 아프리카발톱개구리 |
|---|---|---|---|
| 미란다 (0.896527) | 쌀쌀 (0.841931) | 최경희 (0.839193) | 유전체 (0.880671) |
| 여러분 (0.883907) | 추운 (0.828799) | 이대 (0.833560) | 해독 (0.815927) |
| 마이데일리 (0.858831) | 강원영동 (0.633724) | 경북대 (0.784429) | 서양발톱개구리 (0.812986) |
| 제보 (0.835693) | 아침 (0.627951) | 교수들 (0.770273) | 개구리 (0.721810) |
| 리얼 (0.820783) | 대체 (0.618444) | 총장 (0.763659) | 1700 (0.706803) |
| 취재원과 (0.818968) | 선선 (0.617151) | 교수협의회 (0.749605) | 4배체 (0.680280) |
| 공감 (0.812822) | 새벽 (0.601603) | 입학 (0.746445) | 늑골 (0.647205) |
| 721 (0.811476) | 완연 (0.594135) | 특혜 (0.736045) | 체외수정 (0.639412) |
| 1105 (0.800457) | 가을 (0.585142) | 사퇴 (0.730386) | 경품행사 (0.635621) |
Use exp(PPMI)
문맥이 뚜렷한 단어만 이용하면 학습이 더 잘 된다면, co-occurrence 대신에 PPMI 값을 이용할 수도 있겠다는 생각이 들었습니다. 처음 실험에 이용하였던 36,002 개의 단어에 대하여 PPMI 를 적용합니다.
soynlp.word.pmi 는 sparse matrix 에 대하여 row, column 을 각각 변수 x, y 로 취급하여 PMI 행렬로 변환해줍니다. min_pmi = 0 으로 설정하면 Positive PMI 행렬이 됩니다.
from soynlp.utils import DoublespaceLineCorpus
from soynlp.vectorizer import sent_to_word_contexts_matrix
from soynlp.word import pmi
corpus_path = '2016-10-20_article_all_normed_ltokenize.txt'
corpus = DoublespaceLineCorpus(corpus_path, iter_sent=True)
x, idx2vocab = sent_to_word_contexts_matrix(
corpus,
windows=3,
min_tf=10,
tokenizer=lambda x:x.split(), # (default) lambda x:x.split(),
dynamic_weight=True,
verbose=True)
pmi_dok = pmi(
x,
min_pmi=0,
alpha=0.0001,
verbose=True)Glove.fit 함수에 입력되는 x 는 co-occurrence 입니다. 함수 내부에서 log 를 입력하기 때문에 PPMI 의 결과에 exponential 을 적용하였습니다.
pmi_coo = pmi_dok.tocoo()
pmi_coo.data = np.exp(pmi_coo.data)\(x_{max}\) 의 값도 PMI 기준에 맞도록 작게 설정하였습니다.
glove = Glove(no_components=100, learning_rate=0.05, max_count=3)
glove.fit(pmi_coo, epochs=10, no_threads=4, verbose=True)
dictionary = {vocab:idx for idx, vocab in enumerate(idx2vocab)}
glove.add_dictionary(dictionary)그렇지만 명사만 이용한 경우보다 결과가 좋지는 않습니다. GloVe 를 이용하는 다른 논문들로부터 유추해볼 때, 구현체의 문제라고 생각됩니다.
일단, Word2Vec 과 co-occurrence + PMI 라는 word embedding 수단이 있으니 그 방법을 이용할 것 같습니다.
| 아이오아이 | 아프리카 | 밴쯔 박근혜 | |
|---|---|---|---|
| 세븐 (0.821385) | 태평양지사 (0.697227) | 분양광고 (0.966198) | 역적패당 (0.589079) |
| 에이핑크 (0.818971) | 한번씩 (0.688202) | 프라다 (0.958264) | 주체위성들 (0.588547) |
| 몬스타엑스 (0.787898) | 넘기고 (0.686094) | 30만명 (0.952945) | 대통령 (0.580765) |
| 보이그룹 (0.764891) | 태평양 (0.685456) | 취득세 (0.949870) | 정권 (0.565015) |
| 조해진 (0.752306) | 부천 (0.683222) | 기억상실 (0.946373) | 내자 (0.516892) |
| 오블리스 (0.748496) | 22억원 (0.678707) | 심씨 (0.943394) | 취임식 (0.510350) |
| 에일리 (0.747067) | 사이언스 (0.678692) | 상표권 (0.939953) | 노무현 (0.506976) |
| 익산 (0.745284) | 바닷가 (0.667071) | 탐구 (0.936034) | 가소로운 (0.490007) |
| 이정아 (0.744192) | 찾았던 (0.665898) | 계열회사 (0.930536) | 채송무기자 (0.486237) |
| 뉴스 | 날씨 | 이화여대 | 아프리카발톱개구리 |
|---|---|---|---|
| 기다립니다 (0.755410) | 이어지겠습니다 (0.801522) | 입학 (0.657255) | 사드배치 (0.884393) |
| 머니투데이 (0.658422) | 불어오는 (0.668363) | 이대 (0.651385) | 백성 (0.858467) |
| 리얼타임 (0.644828) | 더운 (0.642125) | 모모영화관 (0.631653) | 토마토 (0.852164) |
| 가치 (0.625832) | 쌀쌀 (0.637030) | 정유라씨 (0.622455) | 꾸렸다 (0.849076) |
| 뉴미디어 (0.599867) | 맑고 (0.631879) | 아트하우스 (0.619704) | 톈궁 (0.838271) |
| 마이데일리 (0.563720) | 맑은 (0.606140) | 총장 (0.589111) | 로버트 (0.837727) |
| 보이는 (0.555548) | 선선 (0.580214) | 특혜 (0.585906) | 대박이 (0.833167) |
| 화제성 (0.550258) | 완연한 (0.577185) | 정유연 (0.559671) | 당겨 (0.829372) |
| 미란다 (0.533638) | 보이겠습니다 (0.565806) | 교수들 (0.555434) | 초상화 (0.825091) |
Reference
- Pennington, J., Socher, R., & Manning, C. (2014). Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP) (pp. 1532-1543).
- Levy, O., & Goldberg, Y. (2014). Neural word embedding as implicit matrix factorization. In Advances in neural information processing systems (pp. 2177-2185).