Word2Vec 과 같은 word embedding 은 distributed representation 을 이용하여 의미가 비슷한 단어를 비슷한 벡터값으로 표현합니다. 그러나 Word2Vec 역시 모르는 단어 (out of vocabulary) 에 대해서는 word representation vector 를 얻을 수 없습니다. 더하여, Word2Vec 은 infrequent words 에 대하여 학습이 불안한 특징도 있습니다. FastText 는 이를 보완하기 위하여 개발된 word representation 입니다. FastText 는 typo 와 같은 노이즈에 강하며, 새로운 단어에 대해서는 형태적 유사성을 고려한 word representation 을 얻습니다.
Introduction
Word2Vec 과 같은 word embedding 은 distributed representation 을 이용하여 의미가 비슷한 단어를 비슷한 벡터값으로 표현합니다. 그러나 Word2Vec 역시 모르는 단어 (out of vocabulary) 에 대해서는 word representation vector 를 얻을 수 없습니다. 더하여, Word2Vec 은 infrequent words 에 대하여 학습이 불안한 특징도 있습니다. FastText 는 이를 보완하기 위하여 Word2Vec 을 제안한 Mikolov 가 2 년 뒤 추가로 제안한 word representation 입니다. Word2Vec 은 한 단어의 벡터값을 직접 학습하지만, FastText 는 단어를 구성하는 subwords (substrings) 의 벡터의 합으로 단어 벡터를 표현합니다. 이 방법은 typo 가 있는 단어라 할지라도 비슷한 word representation 을 얻을 수 있으며, 새로운 단어에 대해서도 단어의 형태적 유사성을 고려한 적당한 word representation 을 얻도록 도와줍니다.
FaceBook Research 의 FastText repository 에 들어가면 세 종류의 논문이 참조되어 있습니다. 이 중 Word2Vec 과 같은 unsupervised word representation 은 첫번째 논문이며, 2 와 3 번째 논문은 supervised word representation 과 효율적인 document classifiers 에 대한 내용입니다. 이번 포스트에서는 첫번째 논문에 대하여 이야기합니다.
- P. Bojanowski, E. Grave, A. Joulin, T. Mikolov, Enriching Word Vectors with Subword Information
- A. Joulin, E. Grave, P. Bojanowski, T. Mikolov, Bag of Tricks for Efficient Text Classification
- A. Joulin, E. Grave, P. Bojanowski, M. Douze, H. Jégou, T. Mikolov, FastText.zip: Compressing text classification models
Out of vocabulary, infrequent words (Word2Vec)
자연어처리 문제에서 언제나 등장하는 어려움은 아마도 (1) 미등록 단어 (out of vocablary) 와 (2) 모호성 일 것입니다. Word2Vec 역시 미등록 단어 문제를 겪습니다. Softmax regression 을 이용하는 Word2Vec 은 앞/뒤에 등장하는 단어로 가운데에 위치한 단어를 예측하는 과정을 통하여 문맥이 비슷한 단어를 비슷한 벡터로 표현합니다. 그렇기 때문에 한 번도 보지 못한 단어에 대해서는 단어 벡터를 학습할 기회가 없습니다.
그리고 단어가 작성되는 과정에서 typo 는 자연스럽게 발생합니다. 문제는 이러한 typo 들의 빈도수는 대체로 작고, 이들은 Word2Vec 을 학습하는 과정에서 min count filtering 에 의하여 제가된다는 점입니다.
사실 infrequent words 는 제거가 되지 않더라도 Word2Vec 에서 학습이 잘 되지 않습니다. 아래는 네이버 영화와 IMDB review 에서 학습한 Word2Vec 모델을 이용하여 유사 단어를 검색한 예시입니다. 괄호 안은 단어의 빈도수 이며, 첫 row 는 queries 입니다. 영화의 유사 단어는 애니, 애니메이션, 작품 과 같은 단어입니다. 형태와 관계없이 의미가 비슷한 단어들이 잘 학습되며, 영화의 typo 인 엉화, 양화 역시 유사어로 검색이 됩니다. 그리고 typo 를 제외하면 대체로 빈도수가 큽니다.
| 영화 (1412516) | 관람객 (585858) | 재미 (344634) | 연기 (255673) | 관상 (988) | 클로버필드 (136) |
|---|---|---|---|---|---|
| 애니 (6075) | 굿굿 (14681) | 제미 (630) | 케미 (2257) | 광해 (4143) | 투모로우 (598) |
| 애니메이션 (7456) | 그치만 (1616) | 재이 (197) | 가창 (104) | 베를린 (2441) | 다이하드 (277) |
| 작품 (39544) | 이지만 (8276) | 잼이 (730) | 영상미 (11800) | 도둑들 (2954) | 쿵푸팬더 (94) |
| 명화 (708) | 유쾌하고 (2810) | 잼 (13098) | 목소리 (3489) | 역린 (1256) | 매트릭스 (928) |
| 드라마 (16306) | but (809) | 짜임새 (3739) | 캐미 (562) | 놈놈놈 (529) | 실미도 (337) |
| 에니메이션 (577) | 그러나 (9951) | 기다린보람이 (98) | 아역 (4463) | 부당거래 (676) | 헝거게임 (121) |
| 엉화 (126) | 듯하면서도 (72) | 잼미 (120) | 카리스마 (3034) | 과속스캔들 (850) | 레지던트이블 (199) |
| 수작 (5048) | 아주 (24571) | ㅈㅐ미 (27) | 노래 (24689) | 감시자들 (654) | 메트릭스 (121) |
| 양화 (164) | 다만 (9957) | 특색 (164) | 열연 (3326) | 전우치 (1863) | 분노의질주 (194) |
| 블록버스터 (5015) | 였지만 (5319) | 잼도 (39) | 배우 (139416) | 숨바꼭질 (470) | 새벽의저주 (215) |
그러나 infrequent words 의 유사어는 infrequent 합니다. 영화 제목 ‘클로버필드’의 typo 인 ‘클러버필드’는 7 번 등장하였고, 그 단어의 유사어들은 대부분 빈도수가 작습니다.
| 켄시로 (5) | 나우유씨 (5) | 클러버필드 (7) | 와일더 (5) |
|---|---|---|---|
| 클러버필드 (7) | 씨미 (47) | characters (5) | 짱예 (11) |
| 디오디오디오디오디오 (8) | 로보 (408) | 미라클잼 (5) | 생스터 (23) |
| 역스 (5) | 트레 (42) | 유월에 (5) | 룰라 (13) |
| qf (5) | 뱅 (13) | 디오디오디오디오디오 (8) | 존섹 (20) |
| 숨도못쉴만큼 (5) | 죤 (19) | 잡잡잡잡 (5) | 윌터너 (39) |
| 좋갯다 (5) | 썩시딩 (9) | 내꼬야 (5) | 이뻐이뻐 (16) |
| 구웃구웃 (9) | 니이이 (6) | qf (5) | 이뿌구 (13) |
| 굳ㅋ굳ㅋ굳ㅋ굳ㅋ굳ㅋ (5) | 피아 (469) | 굳굿굳굿굳 (5) | 77ㅑ (10) |
| 마니마니마니 (7) | 빠이 (50) | 애앰 (6) | 긔요미 (19) |
| 유월에 (5) | 합류하 (14) | romantic (5) | 세젤예 (5) |
이러한 현상은 토크나이징이 대체로 쉬운 영어 데이터인 IMDB 에서도 벌어집니다. game 의 유사어로 games 와 같은 복수형을 포함한 tournament 와 같은 유사어가 잘 검색이 되고, 그들의 빈도수는 큽니다.
| offer (70274) | source (70065) | point (69646) | game (69570) | clear (69270) | lost (68763) |
|---|---|---|---|---|---|
| offering (35315) | sources (66331) | moment (19169) | games (34483) | sure (31732) | gained (28668) |
| bid (56866) | official (118857) | points (94945) | match (30192) | obvious (4959) | regained (2074) |
| purchase (20995) | person (36569) | juncture (650) | movie (27569) | unclear (15638) | dropped (36074) |
| proposal (37150) | aide (10990) | stage (31008) | tournament (18732) | surprising (5217) | slumped (5126) |
| buy (73425) | diplomat (12020) | point; (35) | format (3497) | true (13114) | plummeted (2188) |
| receive (22050) | banker (7946) | time (270178) | season (62459) | helpful (2757) | plunged (7605) |
| offers (16412) | staffer (834) | level (65495) | franchise (7941) | correct (5363) | tumbled (7720) |
| deal (208557) | matter (46652) | outset (1212) | lineup (3504) | clearly (16796) | surged (10280) |
| appeal (23098) | participant (1081) | least (99186) | comedy (9174) | wrong (15615) | soared (6401) |
| unsolicited (1427) | spokesperson (3471) | bhatt (11) | matchup (512) | question (34575) | climbed (12394) |
하지만 infrequent words 의 유사어가 infrequent 한 현상은 동일합니다.
| Shellback (5) | Reflektor (5) | Lazaretto (5) | Suchman (5) | Kissin (5) | Maccabees (5) |
|---|---|---|---|---|---|
| keyboardist (82) | naveen (5) | MINISERIES/TELEVISION (6) | Doctorow (29) | GAPEN (8) | ici (9) |
| Frideric (7) | Kaczorowski; (5) | Groupings (5) | Bub (7) | anup (6) | (Outside (7) |
| Chick (48) | com/gen92k (8) | Kinosis (5) | deWitt (6) | roy (6) | ET/GMT (17) |
| co-writer (146) | alonso (7) | Davis/Greg (5) | Ross: (11) | ASHWORTH (6) | CGC-12-520719 (27) |
| singer) (17) | Davis/Greg (5) | 2017-2027 (9) | Helfer (6) | samajpati (10) | GRIZZLIES (6) |
| Sings (15) | guttsman (5) | 09-md-02036 (11) | Swank: (14) | DETROIT/PARIS (10) | Government-Related (7) |
| Ralph: (5) | yoon (8) | Acquino (8) | Screenwriters: (27) | Maso (5) | Place/Paolo (5) |
| saxophonist (56) | LUZERNE (6) | SAUGUS (7) | Pittendrigh (6) | neetha (5) | emploi (7) |
| Menken; (5) | SKOLKOVO (6) | 13-900 (17) | producer/director (9) | 6386 (7) | Only) (10) |
| Amis (53) | 13-09173 (6) | 2017-2041 (6) | Manganiello (11) | 9202 (5) | (Brooklyn) (19) |
이는 Word2Vec 의 구조적 특성상 frequent words 에 집중하여 학습이 이뤄지기 때문입니다. 사실상 infrequent words 는 포기한다고 생각해도 됩니다. 그러나 Zipf’s law 를 따르는 단어의 특성상 언제나 infrequent words 의 종류가 많습니다. 많은 단어들이 제대로 학습이 이뤄지지 않습니다.
FastText 는 이러한 현상도 함께 해결하고 싶었습니다. ‘클로버필드’가 잘 학습되었기 때문에 형태적으로 유사한 ‘클러버필드’ 역시 비슷한 학습 벡터를 가지길 원합니다.
Subword representation
Out of vocabulary 문제를 tokenization 단계에서 해결하기 위하여 Word Piece Model (WPM) 이 제안되기도 했습니다. WPM 은 ‘appear’ 라는 단어가 잘 알려지지 않았다면, 이를 잘 알려진 subword units 인 ‘app + ear’ 으로 나눕니다. appear 의 의미가 제대로 인식되는 것은 Recurrent Neural Network (RNN) 에게 맏기더라도 out of vocabulary 는 만들지 않겠다는 의미입니다. 그러나 appear 의 의미가 app 과 ear 로부터 composition 이 일어나기는 어렵습니다.
FastText 는 단어를 bag of character n-grams 로 표현합니다. 이를 위하여 먼저 단어의 시작과 끝부분에 <, > 를 추가합니다. 예를 들어 character 3 grams 를 이용한다면 ‘where’ 이라는 단어는 5 개의 3 글자짜리 subwords 로 표현됩니다.
where -> <wh, whe, her, ere, re>
그리고 실제 단어를 나타낼 때에는 3 ~ 6 grams 를 모두 이용합니다.
where -> <wh, whe, her, ere, re>
<whe, wheh, here, ere>
...
마지막으로, 길이와 상관없이 단어에 <, > 를 더한 subword 는 special unit 으로 추가합니다.
where -> <wh, whe, her, ere, re>
<whe, wheh, here, ere>
...
<where>
단어 ‘where’ 의 벡터는 subword vectors의 합으로 표현합니다.
v(where) = v(<wh> + v(whe) + ... v(<where) + v(where>) + v(<where>)
이처럼 단어를 subwords 로 표현하면 typo 에 대하여 비슷한 단어 벡터를 얻을 수 있습니다. Character 3 gram 기준으로 where 와 wherre 는 두 개의 subwords 만 다르고 대부분의 subwords 가 공통으로 존재하기 때문입니다.
where -> <wh, whe, her, *ere*, re>
wherre -> <wh, whe, her, *err*, *rre*, re>
그리고 단어 벡터가 아닌 subwords 의 벡터들을 학습합니다. 그 외에는 Word2Vec 과 동일합니다. Word2Vec 에서 word look-up 을 하는 과정 대신, subwords look-up 을 수행합니다.
아래 식에서의 \(N_{t,c}\) 는 context \(c\) 와 word \(t\) 에 대한 engative samples 입니다.
Word2Vec loss: \(log \left( 1 + exp(-w_t \cdot w_{t-w:t+w}) \right) + \sum_{n \in N_{t,c}} log \left( 1 + exp(w_t \cdot w_n) \right)\)
FastText loss: \(log \left( 1 + exp(-w_g \cdot w_{t-w:t+w}) \right) + \sum_{n \in N_{t,c}} log \left( 1 + exp(w_g \cdot w_n) \right)\)
where \(w_g = \sum_{g \in W}\), g is subwords
그 결과 (word, context) pairs 에 포함된 subwords 끼리 가까워집니다. 문맥적인 의미가 비슷한 young 과 adole, adoles, doles 는 높은 similarity 를 지닙니다 (빨간색일수록 두 subword vectors 간의 Cosine similarity 가 큽니다).
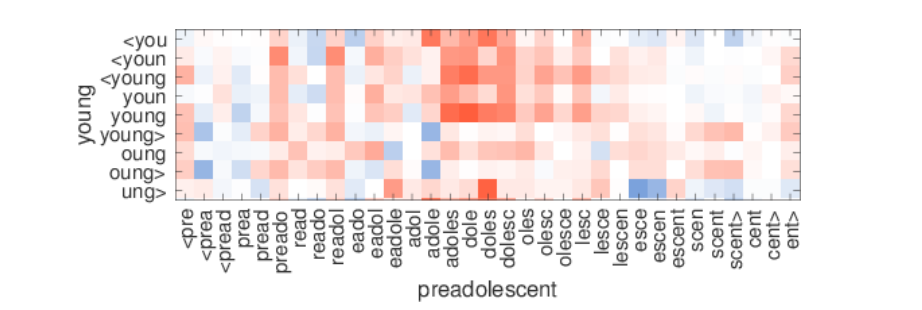
이 과정을 통하여 학습 때 포함되지 않은 단어들에 대해서도 형태적 유사성을 고려한 단어의 벡터를 표현할 수 있으며, infrequent words 에 대해서는 상대적으로 자주 등장했던 subwords 들의 정보를 이용하여 word vector 를 enriching 할 수 있습니다.
한국어를 위한 FastText: 초/중/종성 분리
FastText 는 하나의 단어에 대하여 벡터를 직접 학습하지 않습니다. 대신에 subwords 의 벡터들을 바탕으로 word 의 벡터를 추정합니다. 마치 Doc2Vec 에서 word vector 를 이용하여 document vector를 추정하는 것과 같습니다.
좀 더 자세히 말하자면 v(어디야)는 직접 학습되지 않습니다. 하지만 v(어디야)는 [v(어디), v(디야)]를 이용하여 추정됩니다. 즉 ‘어디야’라는 단어는 ‘어디’, ‘디야’라는 subwords 를 이용하여 추정되는 것입니다.
그런데, 이 경우에는 오탈자에 민감하게 됩니다. ‘어딛야’ 같은 경우에는 [v(어딛), v(딛야)]를 이용하기 때문에 [v(어디), v(디야)]와 겹치는 subwords 가 없어서 비슷한 단어로 인식되기가 어렵습니다.
이는 Edit distance 에서 언급한 것과 같습니다. 한국어의 오탈자는 초/중/종성에서 한군데 정도가 틀리기 때문에 자음/모음을 풀어서 FastText 를 학습하는게 좋습니다. 즉 어디야는 ‘ㅇㅓ-ㄷㅣ-ㅇㅑ-‘로 표현됩니다. 종성이 비어있을 경우에는 -으로 표시하였습니다. FastText 가 word 를 학습할 때 띄어쓰기를 기준으로 나누기 때문입니다.
아래는 초/중/종성이 완전한 한글을 제외한 다른 글자를 제거하며 음절을 초/중/종성으로 분리하는 코드입니다. 이를 이용하여 단어를 초/중/종성으로 나눠놓은 jamo_corpus 를 만들어서 skipgram_jamo_model 을 학습 해야 합니다.
from soynlp.hangle import decompose
doublespace_pattern = re.compile('\s+')
def jamo_sentence(sent):
def transform(char):
if char == ' ':
return char
cjj = decompose(char)
if len(cjj) == 1:
return cjj
cjj_ = ''.join(c if c != ' ' else '-' for c in cjj)
return cjj_
sent_ = ''.join(transform(char) for char in sent)
sent_ = doublespace_pattern.sub(' ', sent_)
return sent_
jamo_sentence('어이고ㅋaaf 켁켁 아이고오aaaaa')
# 'ㅇㅓ-ㅇㅣ-ㄱㅗ- ㅋㅔㄱㅋㅔㄱ ㅇㅏ-ㅇㅣ-ㄱㅗ-ㅇㅗ-'학습에 이용하는 jamo_corpus 는 아래와 같습니다. 첫줄은 ‘크리스토퍼 놀란 에게 우리는 놀란다’ 입니다.
ㅋㅡ-ㄹㅣ-ㅅㅡ-ㅌㅗ-ㅍㅓ- ㄴㅗㄹㄹㅏㄴ ㅇㅔ-ㄱㅔ- ㅇㅜ-ㄹㅣ-ㄴㅡㄴ ㄴㅗㄹㄹㅏㄴㄷㅏ-
ㅇㅣㄴㅅㅔㅂㅅㅕㄴ ㅈㅓㅇㅁㅏㄹ ㅎㅡㅇㅁㅣ-ㅈㅣㄴㅈㅣㄴㅎㅏ-ㄱㅔ- ㅂㅘㅆㅇㅓㅆㄱㅗ-
ㄴㅗㄹㄹㅏㄴㅇㅣ-ㅁㅕㄴ ㅁㅜ-ㅈㅗ-ㄱㅓㄴ ㅂㅘ-ㅇㅑ- ㄷㅚㄴㄷㅏ- ㅇㅙ-ㄴㅑ-ㅎㅏ-
Package
FastText 는 Facebook Research 에서 공식으로 release 한 package 와 Gensim 에서 이를 다른 word embedding 방법들과 interface 를 통일한 package, 두 가지 버전이 자주 이용됩니다. 이번 포스트에서는 Facebook Research 의 official package 를 이용합니다. 설치는 pip install 로 가능합니다.
pip install fasttext
이는 C 코드의 실행 스크립스트를 python 에서 실행시키는 것입니다. input 과 output 으로 위에서 만든 텍스트 파일의 path 와 학습된 모델의 path 를 입력해야 합니다. 그 외의 default parameters 은 아래와 같습니다.
raw_corpus_fname = '' # Fill your corpus file
model_fname = '' # Fill your model file
skipgram_model = fasttext.cbow(
raw_corpus_fname,
model_fname,
loss = 'hs', # hinge loss
ws=1, # window size
lr = 0.01, # learning rate
dim = 150, # embedding dimension
epoch = 5, # num of epochs
min_count = 10, # minimum count of subwords
encoding = 'utf-8', # input file encoding
thread = 6 # num of threads
)이처럼 모델을 학습하고 난 뒤에는 단어 간 유사도를 검색할 때에도 초/중/종성을 분리해야 합니다. 이 과정을 포함한 cosine_similarity 함수를 따로 만듭니다.
def cosine_similarity(word1, word2):
cjj1 = jamo_sentence(word1)
cjj2 = jamo_sentence(word2)
cos_sim = skipgram_model.cosine_similarity(cjj1, cjj2)
return cos_sim아래는 ‘어디야 라는 단어에 대하여 (Word2Vec, FastText) 모델을 이용한 단어 간 similarity 입니다. 어디야? 에서는 ? 가 제거되었기 때문에 similarity = 1.000 이 나타난 것이며, 대체로 형태가 비슷한 단어의 similarity 가 높아졌습니다. 예를 들어 ‘어디야’의 축약형인 ‘어댜’는 0.658 -> 0.886 으로 증가하였습니다. 이 경우에 similarity 에 영향을 크게 주는 subwords 가 ‘ㅇㅓ-ㄷ’ 라는 것도 알 수 있습니다.
| 어댜 (0.825, 0.886) | 어디야? (0.744, 1.000) | 어디여? (0.661, 0.909) |
| 어디여 (0.821, 0.909) | 어디야?? (0.719, 1.000) | 어댜? (0.658, 0.886) |
| 어디얌 (0.816, 0.934) | 어디에요 (0.705, 0.768) | 오디야? (0.655, 0.893) |
| 어디고 (0.778, 0.695) | 어딘뎅 (0.701, 0.865) | 어디고? (0.637, 0.695) |
| 어디양 (0.774, 0.921) | 어딘데? (0.696, 0.882) | 어디얌? (0.635, 0.934) |
| 어디니 (0.758, 0.873) | 어뎌 (0.693, 0.770) | 오디양 (0.634, 0.737) |
| 어디임 (0.753, 0.886) | 어딘데?? (0.673, 0.882) | 어딘뎅? (0.632, 0.865) |
| 어딘데 (0.751, 0.882) | 어디쯤이야 (0.672, 0.832) | 어디에여 (0.630, 0.792) |
| 어디냐 (0.748, 0.850) | 어디예요 (0.668, 0.777) | 오디얌 (0.628, 0.757) |
| 오디야 (0.745, 0.893) | 어디니? (0.662, 0.873) | 어디쯤이야? (0.627, 0.832) |
다른 예시로 Word2Vec 을 이용하여 단어 벡터를 학습한 뒤 ‘짜파게티’의 유사 단어를 검색하면 다음의 결과를 얻을 수 있습니다.
word2vec_model.most_similar('짜파게티')
[('비빔면', 0.9303897023200989),
('불닭볶음면', 0.9284998178482056),
('토스트', 0.9267774820327759),
('베이글', 0.9165289402008057),
('비빔국수', 0.9150125980377197),
('라볶이', 0.914039134979248),
('갈비찜', 0.9139703512191772),
('삼각김밥', 0.9129242897033691),
('부침개', 0.9123827219009399),
('라묜', 0.9121387004852295)]
하지만 typo 에 대해서는 유사어 검색이 되지 않습니다.
word2vec_model.most_similar('짭파게티')
# message ...
1231 all_words.add(self.vocab[word].index)
1232 else:
-> 1233 raise KeyError("word '%s' not in vocabulary" % word)
1234 if not mean:
1235 raise ValueError("cannot compute similarity with no input")
KeyError: "word '짭파게티' not in vocabulary"
그러나 FastText 는 ‘짭파게티’의 유사어도 검색이 가능합니다. ‘짭파게티’에 대한 단어 벡터를 얻을 수 있기 때문입니다. 그리고 ‘짜파게티’의 유사어들과 ‘짭파게티’의 similarity 도 매우 높습니다. 즉 FastText 는 단어의 형태적 유사성과 문맥을 모두 고려하는 word embedding 방법입니다.
word2vec_similars = word2vec_model.most_similar('짜파게티', topn=10)
for word, w2v_sim in word2vec_similars:
ft_sim = cosine_similarity('짭파게티', word)
print('fasttext = {0} ({1}), word2vec = {0} ({2})'.format(word, ft_sim, w2v_sim))| FastText sim (짭파게티, word) | Word2Vec sim (짜파게티, word) |
|---|---|
| 비빔면 (0.840) | 비빔면 (0.930) |
| 불닭볶음면 (0.860) | 불닭볶음면 (0.928) |
| 토스트 (0.788) | 토스트 (0.927) |
| 베이글 (0.688) | 베이글 (0.917) |
| 비빔국수 (0.847) | 비빔국수 (0.915) |
| 라볶이 (0.816) | 라볶이 (0.914) |
| 갈비찜 (0.740) | 갈비찜 (0.914) |
| 삼각김밥 (0.803) | 삼각김밥 (0.913) |
| 부침개 (0.759) | 부침개 (0.912) |
| 라묜 (0.713) | 라묜 (0.912) |
Reference
- Bojanowski, P., Grave, E., Joulin, A., & Mikolov, T. (2016). Enriching word vectors with subword information. arXiv preprint arXiv:1607.04606.