AWS S3 는 bucket 의 파일들에 접속하는 접속 로그 (access logs) 를 저장할 수 있습니다. 텍스트 파일로 제공되는 로그들을 모아 파싱하고, Bokeh 를 이용하여 widget 을 만든 뒤, Flask 를 이용하여 로그 모니터링을 할 수 있는 앱을 만드는 과정을 정리합니다.
AWS S3 를 이용한 텍스트 분석 데이터셋 공유
이전의 AWS 를 이용한 데이터셋 공개 포스트에서 실습에 이용할 데이터셋을 github 과 AWS S3 를 이용하여 공유하였습니다. 포스트에서 공유한 데이터셋은 github 에 textmining-dataset, 실습 코드는 textmining-tutorial 에 공유하였습니다. 각각은 이름에 링크로 연결되어 있습니다.
S3 는 bucket 의 각 파일에 접근하는 requests 를 로깅하는 기능을 제공합니다. 이는 이전의 블로그에 정리해두었습니다. 그런데 로그 데이터가 텍스트 파일 형식입니다. 파일의 단위는 일정하지 않으며, 아마도 특정 사용자가 어느 짧은 시간 간격 안에 발생하는 requests 를 하나의 단위로 묶어서 파일로 저장하는 것으로 생각됩니다. 그리고 텍스트 파일이다보니 로그를 보기 어려웠습니다. 로그를 손쉽게 볼 수 있는 앱서버를 하나 만들면 좋겠다는 생각을 하였습니다.
S3 access log parser
S3 의 log 형식에 대한 documentation 은 여기에 적혀 있습니다. 로그는 아래와 같은 형식입니다. 개인정보는 * 로 가려뒀습니다.
1e28afdbd73**** bucket-name [05/Feb/2019:20:37:01 +0000] ***.***.***.*** 1e28afdbd73f*** F6425**** REST.HEAD.OBJECT directory/subdirectory/filename "HEAD /bucket-name/directory/subdirectory/filename HTTP/1.1" 200 - - 276913361 7 - "-" "aws-internal/3 aws-sdk-java/1.11.481 Linux/4.9.137-0.1.ac.218.74.329.metal1.x86_64 OpenJDK_64-Bit_Server_VM/25.192-b12 java/1.8.0_192" -
timestamp 는 [, ] 로 나뉘어져 있으며, 그 외에는 띄어쓰기를 기준으로 한 csv 형식입니다. timestamp 의 대괄호만 “ 로 치환하면 csv parser 를 이용할 수 있습니다. 파이썬의 csv 패키지는 csv reader 를 제공합니다. 단, reader 함수에 입력되는 단위는 줄 단위를 yield 하는 iterator 이기 때문에 한 줄의 log 를 list 로 감싸서 입력합니다. csv.reader 의 기본 delimiter 는 ‘,’ 이기 때문에 띄어쓰기로 바꿔서 입력합니다.
import csv
def parse(line)
line_ = line.replace('[', '"', 1).replace(']', '"', 1)
return next(csv.reader([line_], delimiter=' '))
위와 같이 parsing 하면 list of str 형식이 됩니다. 출력하기 어려우니 namedtuple 을 이용하여 return type 을 바꿔줍니다. 그리고 namedtuple 의 기본 __repr__ 함수는 key=value 을 한 줄로 붙여둔 형식이기 때문에 가독성이 떨어집니다. 아래와 같이 __repr__ 함수를 재구현하여 가독성을 높여줍닏.ㅏ
from collections import namedtuple
columns = ['owner','bucket','time','remote_ip',
'requester','request_id','operation','key',
'request_url','http_status','error_code','bytes_sent',
'object_size','total_time','turnaround_time','referrer',
'user_agent','version_id'
]
class Log(namedtuple('Log', columns)):
def __repr__(self):
cols = [' {} : {}'.format(key, value) for key, value in self._asdict().items()]
strf = 'Log(\n{}\n)'.format('\n'.join(cols))
return strf
def parse
line_ = line.replace('[', '"', 1).replace(']', '"', 1)
return Log(*next(csv.reader([line_], delimiter=' ')))
위에서 만든 함수를 이용하여 테스트를 합니다.
log_line = '1e28afdbd73**** bucket-name [05/Feb/2019:20:37:01 +0000] ***.***.***.*** 1e28afdbd73f*** F6425**** REST.HEAD.OBJECT directory/subdirectory/filename "HEAD /bucket-name/directory/subdirectory/filename HTTP/1.1" 200 - - 276913361 7 - "-" "aws-internal/3 aws-sdk-java/1.11.481 Linux/4.9.137-0.1.ac.218.74.329.metal1.x86_64 OpenJDK_64-Bit_Server_VM/25.192-b12 java/1.8.0_192" -'
parse(log_line)
아래처럼 구조화된 형태로 파싱이 되었음을 확인할 수 있습니다. time 은 datetime 으로, bytes_sent 나 total_time 과 같은 int type 은 int 로 casting 을 할 수도 있습니다.
Log(
owner : 1e28afdbd73****
bucket : bucket-name
time : 05/Feb/2019:20:37:01 +0000
remote_ip : ***.***.***.***
requester : 1e28afdbd73f***
request_id : F6425****
operation : REST.HEAD.OBJECT
key : directory/subdirectory/filename
request_url : HEAD /bucket-name/directory/subdirectory/filename HTTP/1.1
http_status : 200
error_code : -
bytes_sent : -
object_size : 276913361
total_time : 7
turnaround_time : -
referrer : -
user_agent : aws-internal/3 aws-sdk-java/1.11.481 Linux/4.9.137-0.1.ac.218.74.329.metal1.x86_64 OpenJDK_64-Bit_Server_VM/25.192-b12 java/1.8.0_192
version_id : -
)
Flask 를 이용한 모니터링 앱 만들기
Flask 는 파이썬을 이용하여 간단한 웹서버를 띄우는 패키지 입니다. 모니터링 앱을 위해 다음의 파일들을 만듭니다 parser.py 에는 위에서 만든 parse 함수를 구현합니다.
|-- app
|-- analyzer.py
|-- parser.py
|-- server.py
server.py 는 Flask app server 파일입니다. 아래처럼 파일을 구성합니다.
Flask 라는 app 을 하나 만듭니다. 그리고 server.py 파일이 실행될 때 app.run() 함수를 실행하면 웹 서버가 가동됩니다.
app = Flask('App name')
app.run(host=..., port=...)
@app.route(‘/’) 는 IP 를 입력하였을 때 기본으로 띄워지는 웹페이지입니다. 아래처럼 ‘Main page’ 라는 str 을 return 하도록 할 수도 있습니다. 그러면 위 한줄을 가진 HTML 파일이 return 됩니다.
@app.route('/')
def main():
return 'Main page'
아래처럼 @app.route(‘/test/’) 의 decorator 를 지닌 함수를 구현하면 http://IP/test/ 가 입력될 때 ‘Test’ 라는 str 이 return 됩니다.
@app.route('/test/')
def test():
return 'Test'
위 세가지 내용에 argument parser 까지 추가하여 server.py 파일을 만듭니다. argparse 를 이용하여 host 와 port 를 argument 로 입력받을 수 있도록 만듭니다. Flask 의 기본 host 는 localhost 이며, 이 앱이 돌아갈 컴퓨터는 고정 아이피를 가지고 있기 때문에 이를 이용할 것입니다. 그리고 main 함수는 log 를 정렬하는 listup 함수의 return 값을 return 합니다. 이제 이 listup 함수만 구현하면 됩니다.
# server.py
import argparse
from analyzer import listup
from config import directory
from flask import Flask
app = Flask('S3 access log monitor')
@app.route('/')
def main():
return listup()
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--host', type=str, default=None, help='IP address')
parser.add_argument('--port', type=str, default=None, help='Port')
args = parser.parse_args()
host = args.host
port = args.port
app.run(host=host, port=port)
Bokeh widget 을 이용한 DataTable HTML page 만들기 (Bokeh + Flask)
Bokeh 는 이전 포스트에서 다뤘던 것처럼 데이터 시각화를 도와주는 파이썬 패키지 입니다. 아직 대량의 log 가 쌓이지 않았으며 (그럴 일도 없거니와), 목적은 로그들을 텍스트가 아닌 테이블 형태로 보기 위함이니 Bokeh 의 DataTable 을 써도 좋을 것이라 생각했습니다. Bokeh 와 Flask 를 같이 쓸 수 있는 기회입니다.
일단 S3 에서 로그가 쌓이는 bucket 과 local 을 동기화 하여야 합니다. awscli 는 파이썬에서도 이용할 수 있지만, os.command 를 이용하여 로그 폴더를 동기화 하였습니다.
import os
def listup():
command = 'aws s3 sync s3://{}/ {}'.format(bucket, directory)
os.system(command)
...
하나의 로그 파일에는 한 개 이상의 로그가 쌓일 수 있습니다. 파일마다 file open 을 하는 작업이 번거로우니 LogStream 라는 클래스를 만듭니다. directory 내의 앞 글자가 prefix 인 로그 파일들을 paths 로 가지고 있으며, __iter__ 함수가 실행되면 이 파일들을 열며 한 줄씩 parse 함수에 입력하여 그 결과를 yield 합니다.
from glob import glob
class LogStream:
def __init__(self, directory, prefix):
self.prefix = prefix
paths = sorted(glob('{}/*'.format(directory)))
paths = [p for p in paths if p.split('/')[-1].find(prefix) == 0]
self.paths = paths
def __iter__(self):
for path in self.paths:
with open(path, encoding='utf-8') as f:
for doc in f:
yield parse(doc)
LogStream 의 yield 되는 형식은 Log 라는 namedtuple 입니다. 여기서 저는 datetime, access ip, request url, size 가 궁금하므로, 이들만 column 에 추가합니다. datetime 은 파이썬의 datetime 으로 바꿔줍니다. strptime 을 이용하면 str 을 datetime 으로 변환할 수 있습니다. 그리고 로그의 기록 시간은 한국 시간이 아니기 때문에 timezone 을 이동합니다. datetime.timedelta 를 이용하여 9 시간을 더해주면 됩니다.
최신의 로그를 맨 윗줄로 보내기 위하여 아래처럼 datetime 기준으로 역순 정렬을 합니다.
logs = sorted(logs, key=lambda x:x[0], reverse=True)
로그가 없다면 ‘Empty’ 라는 str 을 return 하고, 로그가 있다면 이를 Bokeh 의 widget 으로 만듭니다.
from datetime import datetime, timedelta
def datetime_parse(dt):
dt = datetime.strptime(dt, '%d/%b/%Y:%H:%M:%S')
dt += timedelta(hours=9)
return dt
def listup():
command = 'aws s3 sync s3://{}/ {}'.format(bucket, directory)
os.system(command)
log_stream = LogStream(directory, prefix)
logs = []
for log in log_stream:
if log.remote_ip in ignore_ips:
continue
cols = (datetime_parse(log.time.split()[0]),
log.remote_ip,
log.request_url.split('?')[0],
byte_format(log.bytes_sent)
)
logs.append(cols)
logs = sorted(logs, key=lambda x:x[0], reverse=True)
if not logs:
return 'Empty'
return log_to_bokeh_widget(logs)
Bokeh 의 plots 은 Java Script 를 이용하는 HTML 입니다. 그리고 이 그림을 HTML 형식의 str 로 변환하는 함수 (file_html) 도 제공합니다. 먼저 Data Table 에 넣을 columns 을 정의합니다. data = dict() 를 이용하여 field 와 값을 입력합니다. 이를 ColumnDataSource 에 입력합니다. SQL 과 같이 structured data table 이 만들어집니다.
DataTable 의 각 column 의 이름을 TableColumn 의 title 에, 이에 해당하는 데이터소스를 ColumnDataSource 에 입력한 key 값으로 입력합니다.
그리고 DataTable 에 source, columns, 그림의 크기를 입력합니다.
마지막으로 file_html 함수를 이용하여 data_table 을 HTML 형식으로 return 합니다.
from bokeh.embed import file_html
from bokeh.models import ColumnDataSource
from bokeh.models.widgets import DataTable, TableColumn
from bokeh.resources import CDN
def log_to_bokeh_widget(logs):
datetimes, ips, requests, bytes_ = zip(*logs)
data = dict(
datetimes = [str(c) for c in datetimes],
ips = ips,
requests = requests,
bytes = bytes_
)
source = ColumnDataSource(data)
columns = [
TableColumn(field="datetimes", title="Datetime"),
TableColumn(field="ips", title="Access IP"),
TableColumn(field="requests", title="Request URL"),
TableColumn(field="bytes", title="Bytes"),
]
data_table = DataTable(source=source, columns=columns, width=1200, height=800)
return file_html(data_table, CDN, "S3 Access Logs").strip()
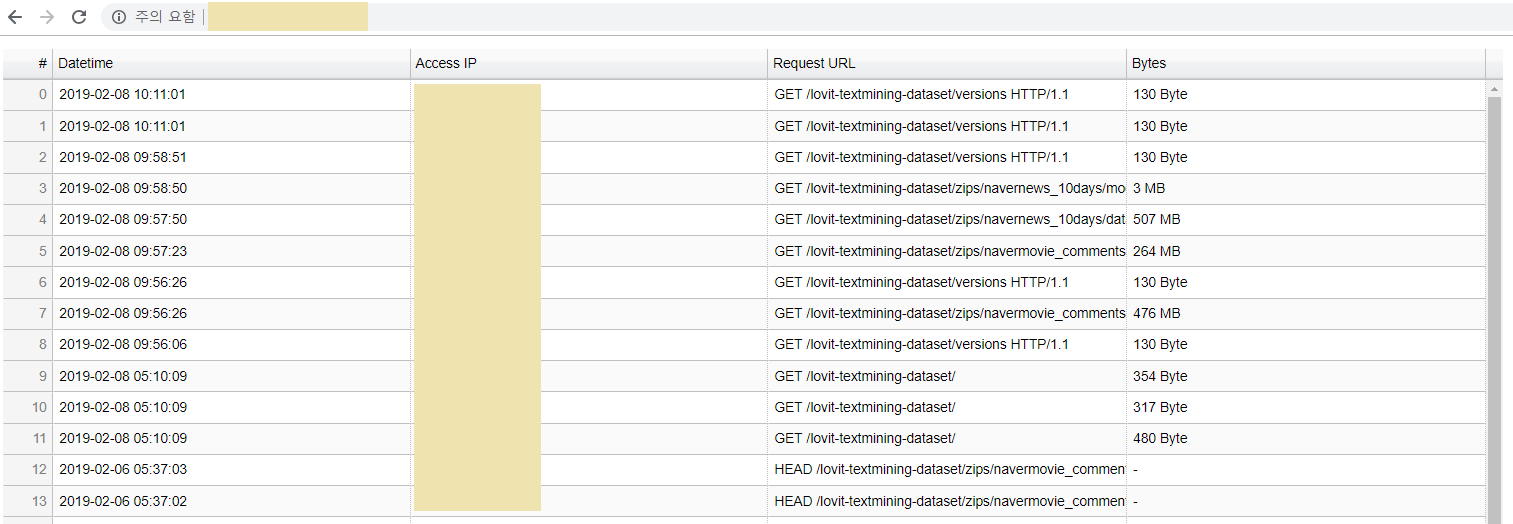
Demo
위 내용들을 github (링크)에 정리해 두었습니다.
필요한 항목들을 만들었으니 IP 와 port 를 입력하여 server.py 파일을 실행시킵니다.
python server.py --host IP --port PORT
http://IP/PORT 에 들어가면 아래와 같이 쌓인 로그들을 볼 수 있습니다. Bokeh widget 은 Column 이름을 누르면 정렬, 역순정렬도 해줍니다.