Word2Vec 을 제안한 Mikolov 는 “딥러닝을 이용한 자연어처리의 발전은 단어 임베딩 (word embedding) 때문이다”라는 말을 했습니다. 단어 간의 유사성을 표현할 수 있고, 단어를 연속적인 벡터 공간 (continuous vector space) 에서 표현하여 (embedding vector 만 잘 학습된다면) 작은 크기의 모델에 복잡한 지식들을 저장할 수 있게 되었습니다. Attention mechanism 도 단어 임베딩 만큼 중요한 발전이라 생각합니다. 2013 년에 sequence to sequence 의 문맥 벡터 (context vector) 를 개선하기 위하여 attention mechanism 이 제안되었습니다. 이는 모델이 필요한 정보를 선택하여 이용할 수 있는 능력을 주었고, 자연어처리 외에도 다양한 문제에서 성능을 향상하였습니다. 그리고 부산물로 모델의 작동방식을 시각적으로 확인할 수 있도록 도와주고 있습니다. 이번 포스트에서는 sequence to sequence 에서 제안된 attention 부터, self-attention 을 이용하는 언어 모델인 BERT 까지 살펴봅니다.
Why attention ?
Word2Vec 을 제안한 Mikolov 는 “딥러닝을 이용한 자연어처리의 발전은 단어 임베딩 (word embedding) 때문이다”라는 말을 했습니다 (Joulin et al., 2016).
One of the main successes of deep learning is due to the effectiveness of recurrent networks for language modeling and their application to speech recognition and machine translation.
자연어처리는 단어 임베딩을 이용하기 전과 후가 명확히 다릅니다. n-gram 을 이용하는 전통적인 통계 기반 언어 모델 (statistical language model) 은 단어의 종류가 조금만 늘어나도 여러 종류의 n-grams 을 기억해야 했기 때문에 모델의 크기도 컸으며, 단어의 의미정보를 쉽게 표현하기 어려웠기 때문에 워드넷 (WordNet) 과 같은 외부 지식을 쌓아야만 했습니다. Bengio et al., (2003) 는 뉴럴 네트워크를 이용한 언어모델을 제안하였고, 그 부산물로 단어 임베딩 벡터를 얻을 수 있었습니다. 그리고 Mikolov et al., (2013) 에 의하여 제안된 Word2Vec 은 Bengio 의 neural language model 의 성능은 유지하면서 학습 속도는 비약적으로 빠르게 만들었고, 모두가 손쉽게 단어 임베딩을 이용할 수 있도록 도와줬습니다. 물론 파이썬 패키지인 Gensim 도 큰 역할을 했다고 생각합니다. Gensim 덕분에 파이썬을 이용하는 분석가들이 손쉽게 LDA 와 Word2Vec 을 이용할 수 있게 되었으니까요.
사견이지만, attention 도 단어 임베딩 만큼이나 자연어처리에 중요한 역할을 한다고 생각합니다. 처음에는 sequence to sequence context vector 를 개선하기 위하여 제안되었지만, 이제는 다양한 딥러닝 모델링에 하나의 기술로 이용되고 있습니다. 물론 모델의 성능을 향상 시킨 점도 큽니다. 하지만 부산물로 얻을 수 있는 attention weight matrix 를 이용한 모델의 작동 방식에 대한 시각화는 모델의 안정성을 점검하고, 모델이 의도와 다르게 작동할 때 그 원인을 찾는데 이용될 수 있습니다. 이전보다 쉽게 복잡한 모델들을 해석할 수 있게 된 것입니다.
그리고 최근에는 self-attention 을 이용하는 Transformer 가 번역의 성능을 향상시켜주었고, 이를 이용하는 BERT 는 왠만한 자연어처리 과업들의 기록을 단 하나의 단일 모델로 갈아치웠습니다.
이번 포스트에서는 attention mechanism 의 시작인 sequence to sequence 부터 BERT 까지, attention mechanism 을 이용하는 모델들에 대하여 정리합니다. 이 포스트의 목적은 attention mechanism 의 원리와 활용 방법에 대해 알아보는 것입니다. 몇 개 모델들의 디테일한 내용은 다루지 않습니다. 이 포스트는 (1) sequence to sequence with attention, (2) CNN encoder - RNN decoder with attention for image captioning, (3) structured self-attentive sentence embedding, (4) hierarchical attention network (HAN), (5) Transformer (attention is all you need), (6) BERT 에 대하여 리뷰합니다.
Attention in sequence to sequence
Sequence to sequence 는 Sutskever et al., (2014) 에 의하여 번역과 같이 하나의 입력 단어열 (input sequence) 에 대한 출력 단어열 (output sequence) 를 만들기 위하여 제안되었습니다. 이는 품사 판별과 같은 sequential labeing 과 다른데, sequential labeling 은 입력 단어열 \([x_1, x_2, \dots, x_n]\) 의 각 \(x_i\) 에 해당하는 \([y_1, y_2, \dots, y_n]\) 을 출력합니다. 입력되는 단어열과 출력되는 품사열의 길이가 같습니다. 하지만 처음 sequence to sequence 가 풀고자 했던 문제는 번역입니다. 번역은 입력 단어열의 \(x_{1:n}\) 의 의미와 같은 의미를 지니는 출력 단어열 \(y_{1:m}\) 을 만드는 것이며, \(x_i\), \(y_i\) 간의 관계를 학습하는 것이 아닙니다. 그리고 각 sequence 의 길이도 서로 다를 수 있습니다.
아래 그림은 input sequence [A, B, C] 에 대하여 output sequence [W, X, Y, Z] 를 출력하는 sequence to sequence model 입니다. 서로 언어가 다르기 때문에 sequence to sequence 는 input (source) sentence 의 언어적 지식을 학습하는 encoder RNN 과 output (target) sentence 의 언어적 지식을 학습하는 decoder RNN 을 따로 두었습니다. 그리고 이 두 개의 RNN 으로 구성된 encoder - decoder 를 한 번에 학습합니다.
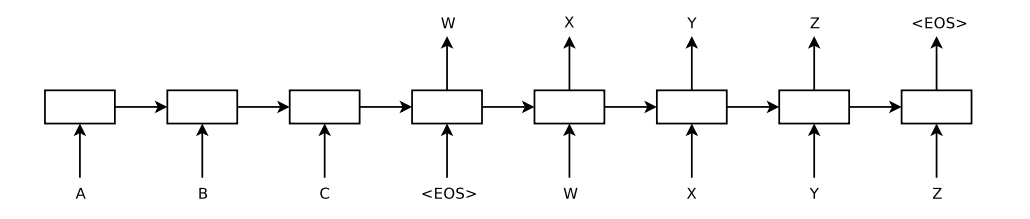
Sequence to sequence 가 학습하는 기준은 \(maximize \sum P_{\theta} \left( y_{1:m} \vert x_{1:n} \right)\) 입니다. \(x_{1:n}\) 과 \(y_{1:m}\) 의 상관성을 최대화 하는 것입니다. 이때 sequence to sequence 는 input sequence 의 정보를 하나의 context vector \(c\) 에 저장합니다. Encoder RNN 의 마지막 hidden state vector 를 \(c\) 로 이용하였습니다. Decoder RNN 은 고정된 context vector \(c\) 와 현재까지 생성된 단어열 \(y_{1:i-1}\) 을 이용하는 language model (sentence generator) 입니다.
\(P(y_{1:m} \vert x_{1:n}) = \prod_i P(y_i \vert y_{1:i-1}, c)\) 물론 이 구조만으로도 번역의 성능은 향상되었습니다. Mikolov 의 언급처럼 word embedding 정보를 이용하였기 때문입니다. Classic n-grams 을 이용하는 기존의 statistical machine translation 보다 작은 크기의 모델 안에 단어 간의 semantic 정보까지 잘 포함되어 번역의 품질이 좋아졌습니다.
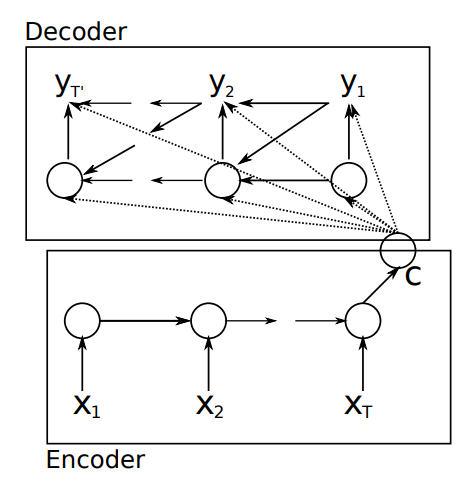
그런데, Bahdanau et al., (2014) 에서 하나의 문장에 대한 정보를 하나의 context vector \(c\) 로 표현하는 것이 충분하지 않다고 문제를 제기합니다. Decoder RNN 이 문장을 만들 때 각 단어가 필요한 정보가 다를텐데, sequence to sequence 는 매 시점에 동일한 context \(c\) 를 이용하기 때문입니다. 대신에 \(x_1, x_2, \dots, x_n\) 에 해당하는 encoder RNN 의 hidden state vectors \(h_1, h_2, \dots, h_n\) 의 조합으로 \(y_i\) 마다 다르게 조합하여 이용하는 방법을 제안합니다. 표현이 너무 좋아서 논문의 구절을 그대로 인용하였습니다.
A potential issue with this encoder–decoder approach is that a neural network needs to be able to compress all the necessary information of a source sentence into a fixed-length vector.
Instead, it encodes the input sentence into a sequence of vectors and chooses a subset of these vectors adaptively while decoding the translation. This frees a neural translation model from having to squash all the information of a source sentence, regardless of its length, into a fixed-length vector.
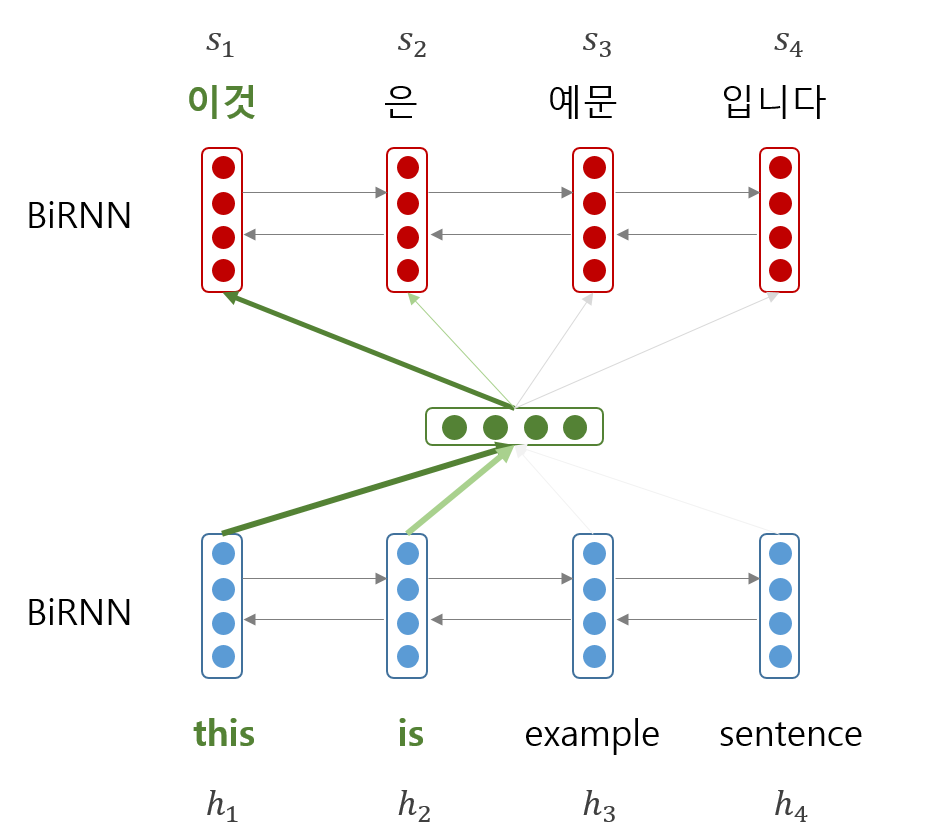
아래의 그림처럼 decoder RNN 이 \(y_i\) 를 선택할 때 encoder RNN 의 \(h_j\) 를 얼만큼 이용할지를 \(a_{ij}\) 로 정의합니다. \(y_i\) 의 context vector \(c_i\) 는 \(\sum_j a_{ij} \cdot h_j\) 로 정의되며, \(\sum_j a_{ij} = 1, a_{ij} \ge 0\) 입니다. \(a_{ij}\) 를 attention weight 라 하며, 이 역시 neural network 에 의하여 학습됩니다.
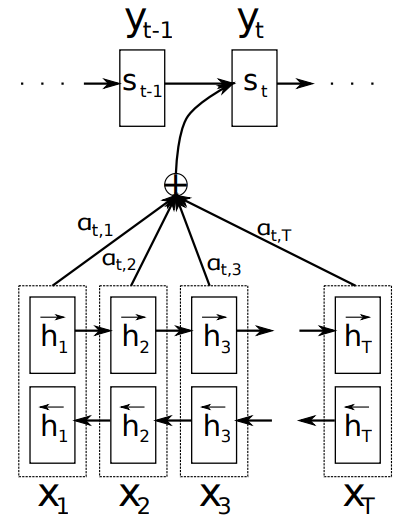
Weight 는 decoder 의 이전 hidden state \(s_{i-1}\) 와 encoder 의 hidden state \(h_j\) 가 input 으로 입력되는 feed-forward neural network 입니다. 출력값 \(e_{ij}\) 는 하나의 숫자이며, 이들을 softmax 로 변환하여 확률 형식으로 표현합니다. 그리고 이 확률을 이용하여 encoder hidden vectors 의 weighted average vector 를 만들어 context vector \(c_i\) 로 이용합니다.
\(a_{ij} = \frac{exp(e_{ij})}{\sum_j exp(e_{ij})}\), \(e_{ij} = f(s_{i-1}, h_j)\)
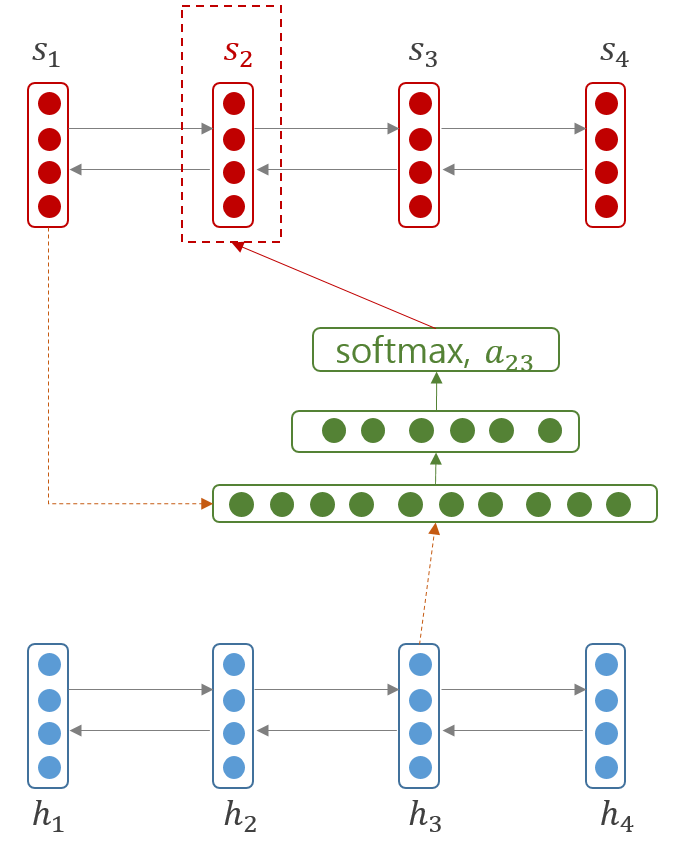
Attention 을 계산하는 feed-forward network 는 간단한 구조입니다. 이는 \([s_{i-1}; h_j]\) 라는 input vector 에 대한 1 layer feed forward neural network 입니다.
즉 이전에는 아래의 그림처럼 ‘this is example sentence’ 를 ‘이것은 예문이다’로 번역하기 위하여 매번 같은 context vector 를 이용했지만,
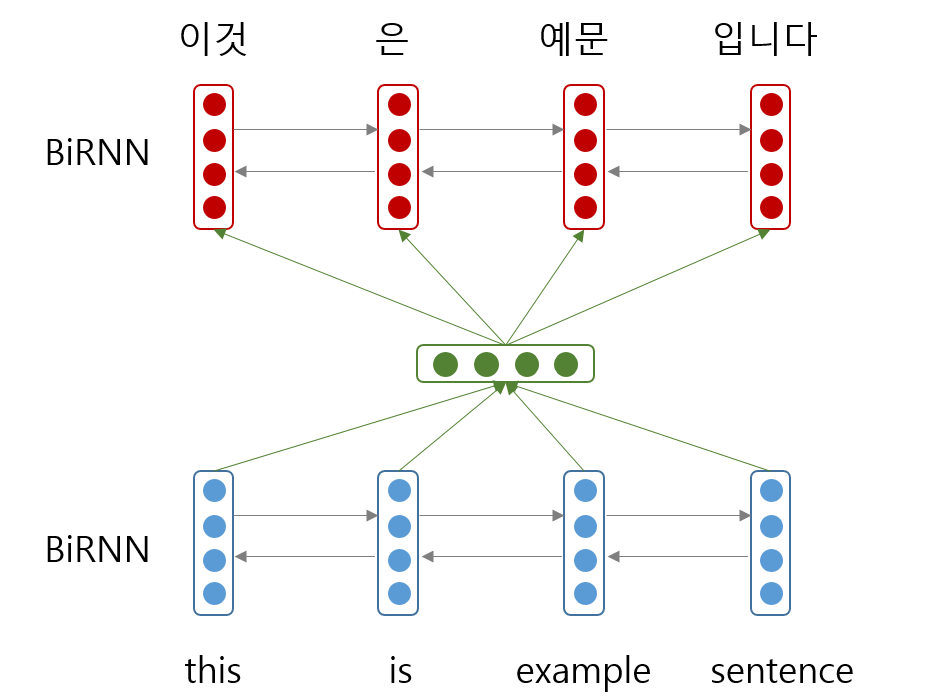
attention 이 이용되면서 ‘이것’ 이라는 단어를 선택하기 위하여 ‘this is’ 라는 부분에 주목할 수 있게 되었습니다.
그리고 그 결과물로 attention weight matrix 를 얻을 수 있습니다. 아래는 영어와 프랑스어 간에 번역을 위하여 각각 어떤 단어끼리 높은 attention weight 가 부여됬는지를 표현한 그림입니다. 검정색일수록 낮은 weight 를 의미합니다. 관사 끼리는 서로 연결이 되어 있으며, 의미가 비슷한 단어들이 실제로 높은 attention weight 를 얻습니다. 그리고 하나의 단어가 두 개 이상의 단어의 정보를 조합하여 이용하기도 합니다.

하지만 대체로 한 단어 \(y_i\) 를 만들기 위하여 이용되는 \(h_j\) 의 개수는 그리 많지 않습니다. 필요한 정보는 매우 sparse 하며, 이는 decoder 가 context 를 선택적으로 이용하고 있다는 의미입니다. 그럼에도 불구하고 기존의 sequence to sequence 에서는 하나의 벡터에 이 모든 정보를 표현하려 했으니, RNN 의 모델의 크기는 커야했고 성능도 낮을 수 밖에 없었습니다. Attention mechanism 은 같은 크기의 공간을 이용하는 RNN 이라면 더 좋은 성능을 보이도록 도와주었습니다. RNN 은 sequence encoding 을, attention 은 context vector 를 만드는 일을 서로 나눴습니다. 하나의 네트워크에 하나의 일만 맏기는 것은 네트워크에 부하를 줄여주는 것입니다.
Attention in Encoder - Decoder
얼마 지나지 않아서 attention mechanism 은 다른 encoder - decoder system 에도 이용되기 시작합니다. Xu et al., (2015) 에서는 이미지 파일을 읽어서 문장을 만드는 image captioning 에 attention mechanism 을 이용합니다. 일반적으로 image classification 을 할 때에는 CNN model 의 마지막 layer 의 concatenation 시킨 1 by k 크기의 flatten vector 를 이용하는데, 이 논문에서는 마지막 activation map 을 그대로 input 으로 이용합니다. activation map 역시 일종의 이미지입니다. Activation map 의 한 점은 이미지에서의 어떤 부분의 정보가 요약된 것입니다. 여전히 locality 가 보존되어 있는 tensor 입니다. 그리고 sequence to sequence 처럼 RNN 계열 모델을 이용한 language model 로 decoder 를 만듭니다. 이 때 attention weight 를 이용하여 마지막 activation map 의 어떤 부분을 봐야 하는지 결정합니다. 이는 실제 이미지의 특정 부분을 살펴보고서 단어를 선택한다는 의미입니다.
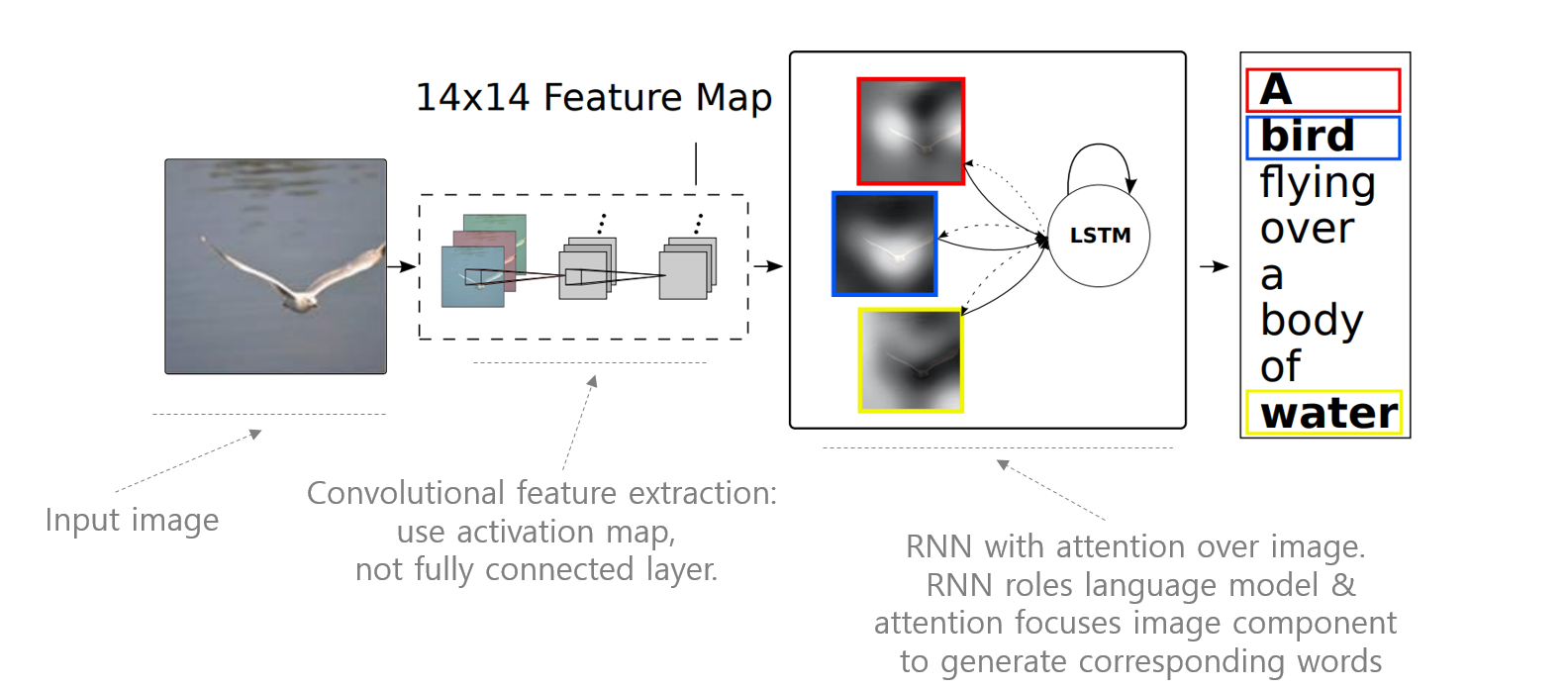
그 결과 생성된 문장의 단어들이 높은 weight 로 이용한 이미지의 부분들을 시각적으로 확인할 수 있게 되었습니다. 실제로 이미지의 일부 정보를 이용하여 문장을 만들었습니다.

또한 모델이 엉뚱한 문장을 출력하였을 때, 그 부분에 대한 디버깅도 가능하게 되었습니다. 그리고 아래의 예시들은 실제로 사람도 햇갈릴법한 형상들입니다. 모델이 잘못된 문장을 생성했던 이유가 납득 되기도 합니다.

이처럼 encoder - decoder system 에서 decoder 가 특정 정보를 선택적으로 이용해야 하는 문제에서 attention mechanism 이 이용될 수 있습니다.
Attention in Sentence classification
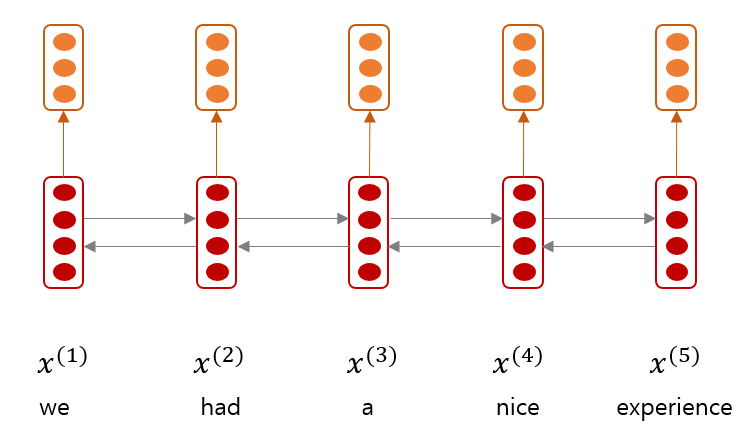
Recurrent Neural Network (RNN) 은 sentence representation 을 학습하는데도 이용될 수 있습니다. Input sequence 로 word embedding sequence 를 입력한 뒤, 마지막 hidden state vector 를 한 문장의 representation 으로 이용할 수도 있습니다. 혹은 모든 hidden state vectors 의 평균이나, element-wise pooling 결과를 이용할 수도 있습니다. 그리고 그 representation 을 sentiment classification 과 같은 tasks 를 위한 model 의 input 으로 입력하면 tasks 를 위한 sentence encoder 가 됩니다. 그런데 문장의 긍/부정을 판단하기 위하여 문장의 모든 단어가 동일하게 중요하지는 않습니다. 문장의 representation 을 표현하기 위하여 정보를 선택적으로 이용하는데 attention 이 도움이 될 수 있습니다.
또한 RNN 은 word embedding sequence 와 달리, 한 단어의 앞/뒤 단어들을 고려하여 문맥적인 정보를 hidden state vectors 에 저장합니다. 즉, RNN 을 이용하여 문맥적인 정보를 처리하고, attention network 와 classifier networks 가 tasks 에 관련된 정보를 처리하도록 만들 수 있습니다.
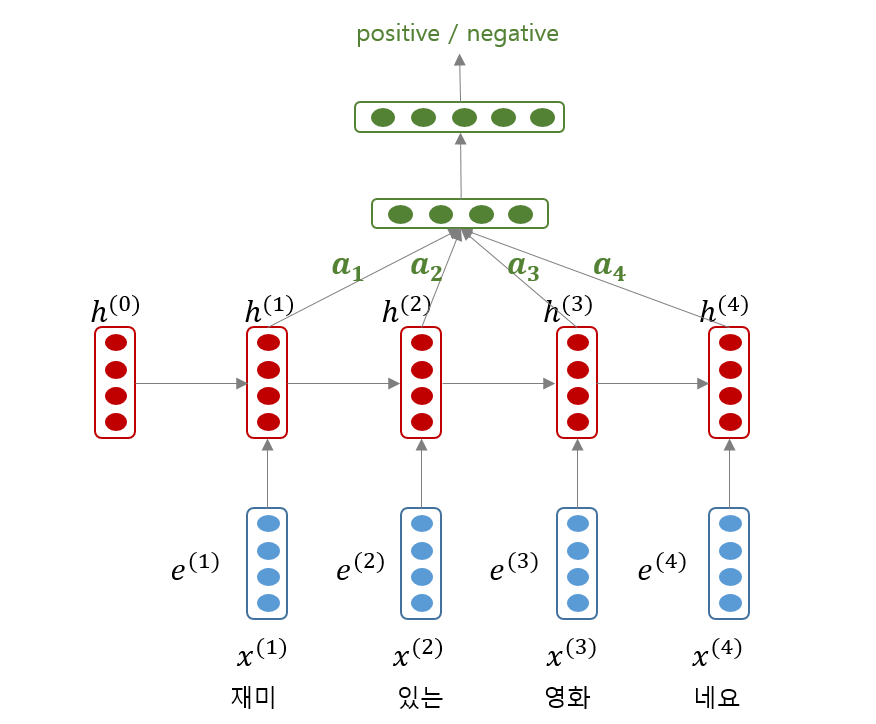
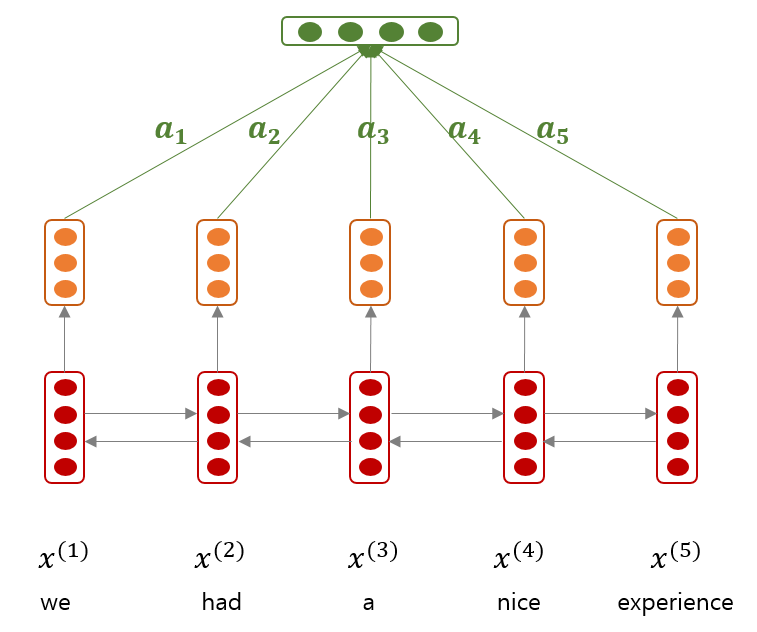
Lin et al., (2017) 은 2 layers feed-forward newral networks 를 이용하는 attention network 를 제안했습니다. Input sequence \(x_{1:n}\) 에 대하여 hidden state sequence \(h_{1:n}\) 이 학습되었을 때, 문장의 representation 은 weighted average of hidden state vectors 로 이뤄집니다.
그리고 attention weight \(a_i\) 는 다음의 식으로 계산됩니다. Hidden state vectors \(H\) 가 input 이며, 여기에 \(W_{s1}\) 을 곱한 뒤, hyper tangent 를 적용합니다. 그 뒤, \(w_{s2}\) 벡터를 곱하여 attention weight 를 얻습니다. 우리는 이 식의 의미를 해석해 봅니다.
\(H\) 의 크기가 \((n, h)\) 라 할 때, \(W_{s1}\) 의 크기는 \((d_a, h)\) 입니다. \(W_{s1}H^T\) 는 \((d_a, n)\) 입니다. Linear transform 은 공간을 회전변환하는 역할을 합니다. \(h_i\) 는 문맥을 표현하는 \(h\) 차원의 context space 에서의 벡터입니다. 그리고 \(W_{s1}\) 에 의하여 \(d_a\) 차원의 벡터로 변환됩니다. 논문에서는 \(h=600, d_a=350\) 으로 차원의 크기가 줄어들었습니다. 이 350 차원 공간은 각 벡터의 중요도를 표현하는 공간입니다. 여기에서는 더 이상 문맥적인 정보는 필요없습니다. 단지 문장 분류에 도움이 되는 문맥들만을 선택하는 역할을 합니다. 그리고 … in the … 와 같은 구문들은 문장 분류에 도움이 되지 않습니다. \(W_{s1}\) 은 이처럼 불필요한 문맥들을 한 곳에 모으는 역할을 하는 것과도 같습니다.
그리고 여기에 hyper tangent 가 적용됩니다. 이는 벡터의 각 차원의 값을 [-1, 1] 로 scaling 합니다. 그렇기 때문에 \(tanh(W_{s1}h_i)\) 는 반지름이 1 인 구 (sphere) 안에 골고루 분포한 벡터들이 됩니다.
여기에 \(d_a=350\) 차원의 \(w_{s2}\) 가 내적되어 attention weight 가 계산됩니다. 이는 마치 softmax regression 에서의 coefficient vectors (대표벡터) 의 역할을 합니다. \(w_{s2}\) 와 비슷한 방향에 있을수록 문장 분류에 중요한 문맥이라는 의미입니다.
즉 \(W_{s1}\) 에 의하여 문맥 공간을 중요도 공간으로 변환하였고, \(w_{s2}\) 에 의하여 실제로 중요한 문맥들을 선택합니다. 그리고 softmax 를 취하기 때문에 확률의 형태로 attention weight 가 표현됩니다.
그런데 어떤 문맥들이 중요한지는 관점에 따라 다를 수 있습니다. \(w_{s2}\) 는 한 관점에서의 문맥들의 중요도를 표현합니다. 관점이 여러개일 수도 있습니다. 이를 위하여 \((1, d_a)\) 차원의 column vector \(w_{s2}\) 가 아닌, \((r, d_a)\) 차원의 \(W_{s2}\) 를 이용합니다. 논문에서는 \(r=30\) 로 실험하였습니다. 30 개의 관점으로 hidden state vectors 를 조합합니다. Attention 을 계산할 때의 softmax 역시 각 row 별로 이뤄집니다. 그리고 여기서 만들어진 \((r, h)\) 크기의 sentence representation matrix 를 \((1, r \times h)\) 의 flatten vector 로 만들어 classifier 에 입력합니다.
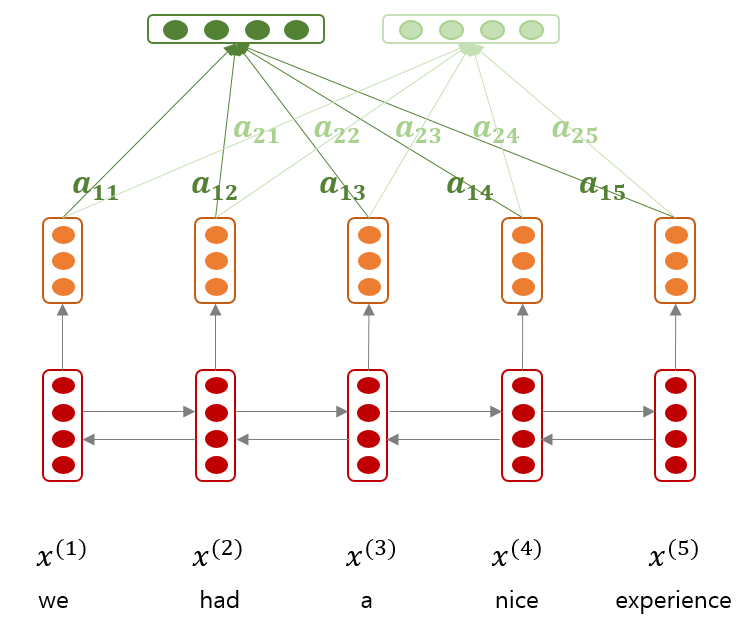
그런데 한 가지 문제가 더 남았습니다. Attention matrix \(A\) 의 각 관점들이 서로 비슷한 벡터를 가질 수도 있습니다. 관점이 모두 달라야한다는 보장을 하지 않았기 때문입니다. \(W_{s2}\) 에 다양한 관점이 잘 학습되도록 유도하기 위하여 다음과 같은 regularization term 을 추가합니다. 이는 attention matrix 의 각 row 들, 즉 \(r\) 개의 관점들이 서로 독립에 가까워지도록 유도하는 것입니다.
Attention 을 이용한 결과 문장 분류에 이용한 중요한 맥락들이 어디인지 표시도 할 수 있습니다. 아래는 Yelp review 에서 긍정적인 평점으로 분류하는데 이용된 맥락들입니다. 빨간색일수록 높은 attention weight 를 받은 부분들입니다. 그리고 이때에는 문서의 모든 문장들을 하나의 문장으로 합쳐서 분류에 이용하였습니다.

Attention in Document classification
Yang et al., (2016) 은 Lin et al., (2017) 보다 먼저 문서 분류를 위한 attention mechanism 을 제안합니다. 이름은 Hierarchical Attention Network (HAN) 입니다. Yang 은 기존의 문서 분류를 위한 모델들이 문서의 구조적 성질을 제대로 이용하지 못한다는 점을 지적합니다. 문장은 단어로 이뤄져 있습니다. 그리고 문장 분류에 모든 단어가 똑같이 중요하지는 않습니다. 문서는 문장으로 이뤄져 있습니다. 문서 분류에도 역시 모든 문장이 동일하게 중요하지는 않습니다. 이처럼 문서는 ‘문서 > 문장 > 단어’와 같은 계층적 구조를 가지고 있음에도 불구하고, 모델들이 이를 잘 이용하지 못한다고 지적합니다.
또 한 가지, logistic regression 을 이용한 문서 분류에서는 모든 단어가 문맥과 상관없이 동일한 영향력을 지닙니다. 만약 negation 처리가 되지 않는다면 부정적인 맥락인 ‘not good’ 에도 ‘good’ 이 포함되어 있기 때문에 긍정으로 분류될 가능성이 높습니다. 이런 점들을 방지하기 위하여 bigram 등이 이용되지만, 제일 좋은 방법은 애초에 ‘not good’ 이란 맥락에서는 ‘good’ 을 분류에 이용하지 않는 것입니다. 논문에는 이러한 내용이 잘 표현되어 있습니다.
First, since documents have a hierarchical structure, we likewise construct a document representation by building representation of sentences and then aggregating these into a document representation.
Second, different words and sentences in a documents are differentially informative.
Third, the importance of words and sentences are highly context dependent, i.e. the same word or sentence may be differentially important in different context.
그래서 논문은 다섯 개의 sub network (word encoder, word attention, sentence encoder, sentence attention, classifier) 로 구성된 구조를 제안합니다. 한 문장 \(s_i\) 의 representation 을 학습하기 위하여 word-level BiGRU 가 이용되었습니다. 그리고 이로부터 학습된 hidden state vectors \(h_{it}\) 를 이용하는 word attention network 는 아래와 같이 구성됩니다. Hyper tangent actvation 을 이용하는 1 layer feed forward neural network 입니다.
그 결과 한 문장에 대한 sentence vector \(s_i\) 를 얻을 수 있습니다. 그리고 한 문서의 문장들도 흐름이 있습니다. 이러한 흐름을 학습하기 위하여 sentence-level BiGRU 를 학습합니다. 여기에서 document representation \(v\) 의 벡터는 sentences 에 대한 weighted average vectors 로 계산됩니다.
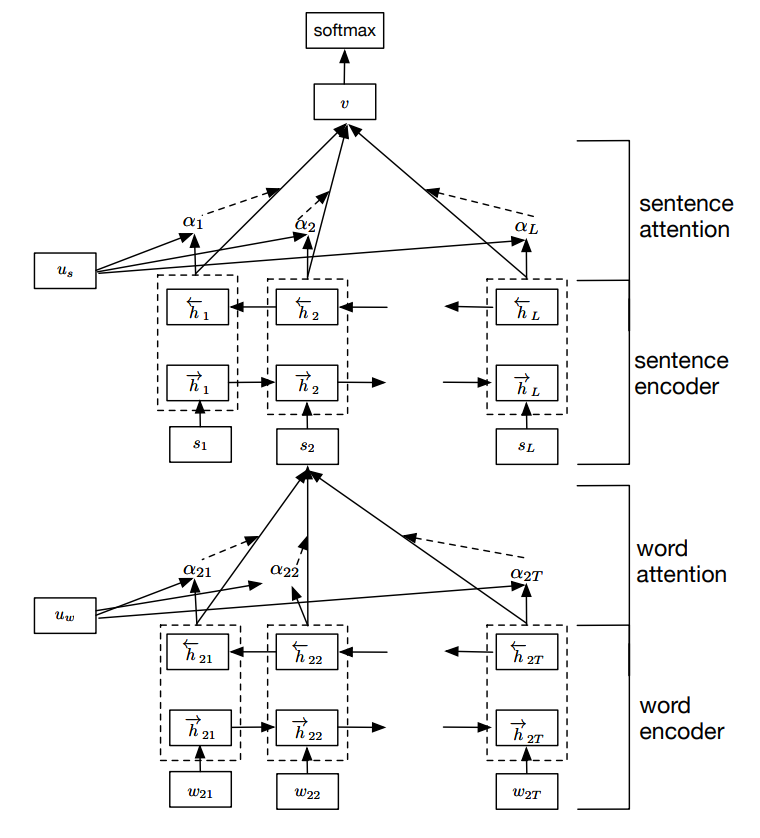
HAN 의 학습 결과 문서 분류에 중요한 문장과 각 문장의 단어들을 시각적으로 확인할 수 있습니다. Figure 5 는 Yelp data 에 대한 시각화 입니다. 빨간색일수록 중요한 문장이며, 파랑색일수록 중요한 단어입니다. 긍정을 판단하는데 delicious, amazing 과 같은 단어가, 부정을 판단하는데 terrible, not 과 같은 단어들이 큰 영향을 주었음을 확인할 수 있습니다.
또한 topic / category classification 에도 유용합니다. 특히나 category classification 에서는 특정 클래스의 문서들에서만 등장하는 단어들이 있습니다. 예를 들어 ‘zebra, wild life, camoflage’ 라는 단어만 들어도 짐작되는 주제들이 몇 개가 있습니다. 이처럼 topical information 만 주목해도 문서의 category classification 은 쉽게 풀립니다. 아래 그림은 실제로 HAN 역시 그 과정으로 문서를 분류했음을 보여줍니다.

또 한 가지 놀라운 점은 ‘good’ 과 ‘bad’ 가 각 점수대 별로 다르게 활용되었다는 점입니다. 아래의 그림에서 각각 (a) 는 문서 전체에서 ‘good’ 과 ‘bad’ 의 attention weight 의 평균입니다. 그리고 (b) - (f) 는 각각 1 - 5 점 사이에서 ‘good’ 과 ‘bad’ 에 적용된 attention weight 의 평균입니다. ‘good’ 은 긍정적인 4, 5 점에서는 자주 이용되지만 1, 2 점에서는 거의 이용되지 않았습니다. 아마도 이는 ‘not good’ 과 같은 negation 의 과정에서 등장한 ‘good’ 일 것입니다. ‘bad’ 역시 1, 2 점에서는 어느 정도 높은 attention weight 를 받지만, 3, 4, 5 점 에서는 거의 이용되지 않습니다.
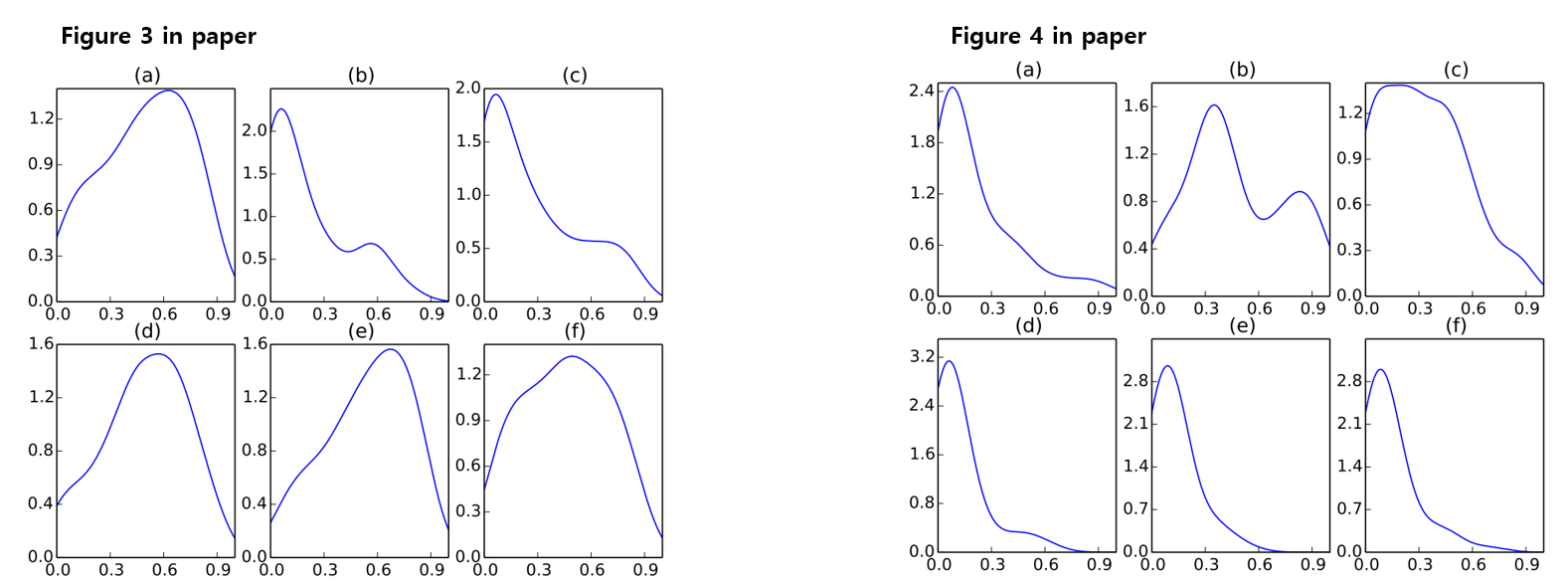
단어를 문맥에 맞게 선택하여 features 로 이용한다는 점은 사람의 문서 분류 과정과도 매우 흡사합니다. 그리고 그 결과 1 점에서의 ‘good’ 과 같이 문맥에 필요한 정보만을 선택하여 노이즈를 줄일 수 있습니다. 그 결과 문서 분류의 성능이 기존 모델들과 비교하여 확실히 상승했습니다.
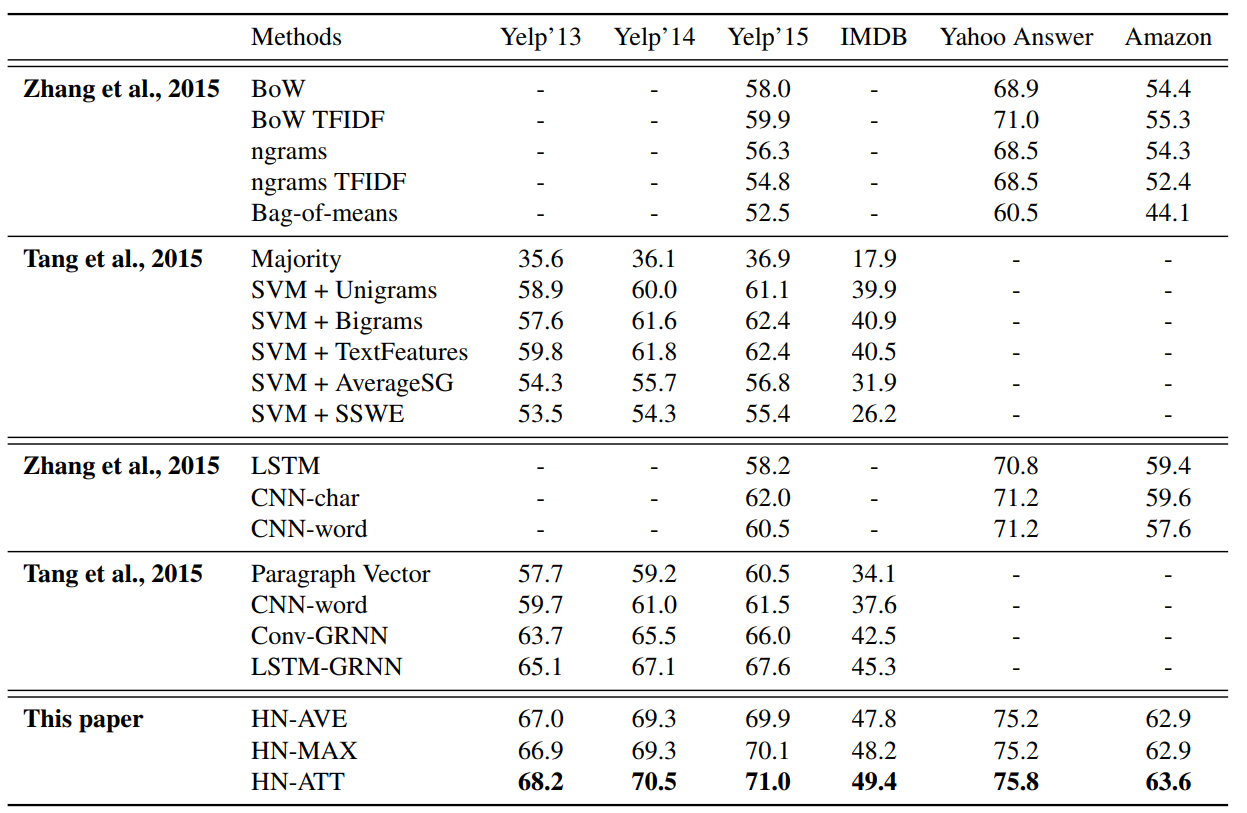
이전에 Mikolov 는 document classification 에서는 어자피 특정 단어가 등장하였는지에 대한 정보가 중요하기 때문에 사실상 word embedding 의 정보가 잘 이용되지 않는다고 말하였습니다. 그리고 그 결과 복잡한 구조의 deep neural network document classifier 를 만든다고하여, 기존의 bigram + naive bayes classifier 등보다 아주 높은 성능의 향상이 이뤄지지는 않는다고 주장하였습니다. 실제로 그의 실험에서도 bigram bag-of-words model 들이 매우 좋은 성능을 보여줬습니다.
그런데 이번에는 정말로 BoW 와 비교하여 성능의 향상이 되었습니다. 생각해보면 BoW 는 1 점에서의 ‘good’ 을 걸러내는 능력이 없습니다. 하지만 HAN 은 바로 그 능력이 모델의 구조에 담겨있습니다. 그렇기 때문에 잘못된 정보에 의한 오판의 가능성이 줄어듭니다. 이 점때문에 드디어 document classification 에서의 성능이 향상되었습니다. 그리고 이는 저자들도 언급하는 부분입니다. 필요한 문장만을 선택하여, 그 안에서 중요한 단어의 정보만을 이용하였기 때문에 문서 분류가 잘 되었다고 말이죠.
From Table, we can see that neural network based methods that do not explore hierarchical document structure, such as LSTM, CNN-word, CNN-char have little advantage over traditional methods for large scale (in terms of document size) text classification.
또한 주목할 점 중 하나는, 모델은 복잡한 dense network 인데, 실제로 모델이 이용하는 정보들은 더욱 sparse 하다는 점입니다. 적어도 문장 / 문서 분류에서의 딥러닝 모델의 역할은 새로운 정보의 추출이 아닌, 필요한 정보의 선택으로 보입니다.
Transformer (self-attention)
그런데 HAN 까지도 word, sentence encoder 를 RNN 계열의 모델들을 이용하였습니다. 하지만 RNN 은 몇 가지 본질적인 문제점들을 가지고 있습니다. 첫째로 모델의 크기가 큽니다. LSTM 과 같은 모델은 hidden to hidden, cell to cell 연산을 위하여 매우 큰 행렬들을 지닙니다. 그리고 RNN 은 반드시 sequence 의 마지막 부분까지 계산이 완료되어야 학습을 할 수 있습니다. Back-propagation through time (BPTT) 를 생각해보면 반드시 그래야 합니다. 그 결과 하나의 sequence 에 대한 작업을 병렬적으로 진행할 수가 없습니다. 마지막으로 RNN 이 오로직 local context 만을 저장하는 문제를 완화해보자 LSTM 이나 GRU 와 같은 모델이 제안되었지만, 이들도 long dependency 를 잘 학습하지는 못했습니다. 또한 멀리 떨어진 두 단어의 정보가 하나의 context vector 에 포함되기 위해서는 여러 번의 행렬 곱셈을 해야만 합니다.
Self-attention 은 이를 해결하기 위한 방법입니다. Transformer 는 오로직 feed-forward neural network 를 이용하여 encoder, decoder, attention network 를 모두 구축한 encoder - decoder system 입니다. 이는 처음 번역을 위하여 제안되었습니다.
아래 그림은 Transformer 논문에 나온 세 개의 그림입니다. 오른쪽이 왼쪽 네모를 확대한 부분입니다. 이들에 대하여 하나씩 알아봅니다.
일단 Transformer 는 6 개 층의 transformer block 으로 이뤄진 encoder, decoder 와 encoder - decoder 를 연결하는 attention 으로 이뤄져 있습니다. 이는 마치 sequence to sequence + attention 과 비슷한 형태입니다. 단, encoder 와 decoder 가 깊이가 6 층인 모델입니다. 그리고 각 transformer block 은 길이가 \(n\) 인 input sequence 를 입력받아서 길이가 똑같은 output sequence 를 출력합니다. 그리고 각 sequence item 의 차원도 모두 \(d_{model}\) 로 동일합니다. 논문에서는 \(d_{model}=512\) 를 이용하였습니다. 즉, 5 개의 단어로 이뤄진 문장은 처음 embedding lookup 을 통하여 \((5, 512)\) 의 sequence 로 입력됩니다. 그리고 매 block 을 통과할 때마다 똑같은 \((5, 512)\) 크기의 sequence 로 출력됩니다.
![]()
처음 살펴볼 부분은 scaled dot product attention 부분입니다. 위 그림의 가장 오른쪽에 위치한 부분입니다. 아래 그림은 \(l\) 번째 block 에 길이가 \(n\) 인 input sequence 가 입력된 경우입니다. 만약 첫번째 transformer block 이라면 word embedding sequence 에 positional encoding 이 더해진 값이 input sequence 로 입력됩니다. 그 이후에는 이전 layer 의 output sequence 가 그대로 input 으로 입력됩니다.
Transformer 가 input sequence 를 입력받아 처음 하는 작업은 각 sequence item 을 세 종류의 차원으로 변화하는 것입니다. \(W_l^Q, W_l^K, W_l^V\) 는 각각 sequence item \(x_i\) 를 \(q_i, k_i, v_i\) 로 변환합니다. 각각은 query, key, value 로 불립니다. key - value 는 이름 그대로 {key:value} 입니다. key 에 해당하는 결과값이 value 에 저장됩니다. Query \(q_i\) 와 key \(k_j\) 는 \(x_i, x_j\) 의 상관성을 측정하기 위한 정보입니다. Attention weight \(a_{ij}\) 는 \(f(q_i, k_j)\) 에 의하여 계산됩니다. 이는 sequence to sequence 에서도 살펴보았습니다. Seq2seq + attention 에서는 \(e_{ij} = f(s_{i-1}, h_j)\) 로 정의되었고, 이 때 \(s_{i-1}\) 이 query, \(h_j\) 가 key 입니다. 새로운 representation 을 만들기 위한 위치에 해당하는 값을 query 라 하고, 이 query 와 얼마나 상관성이 있는지를 측정하는 값을 key 라 합니다. Query 와 key 에 의하여 상관성 (attention weight) 이 측정되면, 이 값과 value \(v_j\) 의 가중평균으로 최종 representation 을 학습합니다.
Seq2seq + attention 에서는 key 와 value 모두 \(h_j\) 였습니다. 그런데 key 와 value 의 정보를 나눠서 서로 다른 패러매터로 학습하면 그 결과가 더 좋습니다. 그렇기 때문에 Transformer 에서는 query, key, value 라는 세 개의 정보를 이용하여 attention 을 계산합니다. 그리고 \(W_l^Q, W_l^K, W_l^V\) 는 각 layer \(l\) 에서 input item 의 공간을 변환하는 역할을 합니다.
Transformer 는 sequence to sequence 에서와는 다른 형식의 attention function 을 이용합니다. Sequence to sequence 처럼 \(f_1(q) + f_2(k)\) 와 같이 input key, query pair 의 정보가 더해지는 경우를 additive attention 이라 합니다. 이와 다르게 \(f_1(q) \times f_2(k)\) 처럼 query, key pair 의 정보의 내적을 이용하는 경우를 multiplicative attention 이라 합니다. Transformer 는 후자를 이용합니다.
\(a_{ij}\) 를 계산하기 위한 \(attention(x_iW_l^Q, x_jW_l^K, x_jW_l^V)\) 을 간단히 \(attention(q_i, k_j, v_j)\) 라 합니다. Position \(i\) 와 \(j\) 의 상관성은 \(q_i\) 와 \(k_j\) 벡터의 내적을 key vector 의 dimension 의 root 값으로 나눠서 정의합니다. \(\sqrt{d_k}\) 로 나눈 이유는 벡터의 차원이 커질수록 내적값이 커질 가능성이 높고, 여기에 exponential 을 씌워 Softmax 를 만들면 극단적인 값들이 만들어지기 때문입니다. 일종의 scaling 입니다.
그리고 모든 \(k_j\) 에 대하여 \(e_{ij}\) 를 계산한 뒤, 이에 대한 Softmax 를 계산합니다. 그 결과 각 position \(1\) 부터 \(n\) 까지의 \(a_{ij}\) 가 계산되고 \(j\) 에 해당하는 \(v_j\) 를 곱하여 position \(i\) 에 대한 새로운 representation 을 만듭니다. 이는 마치 멀리 떨어진 두 단어의 정보를 합쳐 새로운 단어의 representation 을 표현한 것과 같습니다. 뒤쪽의 그림에서 살펴볼텐데, ‘it’ 이라는 단어의 representation 을 표현하기 위하여 문장의 다른 단어들, ‘the, animal’ 등의 정보가 이용됩니다. 뒤에서 다시 설명하겠습니다.
그래서 scaled dot product attention 이라는 이름이 붙었습니다. 단, 아직 우리는 위 그림의 Mask (Opt.) 는 설명하지 않았습니다. 이 부분은 decoder 의 self-attention 에만 존재합니다.
![]()
그런데 한 개의 \(attention(q_i, k_j, v_j)\) 에 의한 output 의 크기를 \(d_{model}=512\) 로 만들지 않습니다. 64 차원의 벡터로 작게 만드는 대신, 서로 다른 \(W_l^{K,1}, W_l^{K,2}, \dots\) 을 \(h=8\) 개 만들어 8 번의 attention 과정을 거칩니다. 그리고 그 결과를 concatenation 합니다. 이를 multi-head attention 이라 합니다. 하나의 attention 은 하나의 관점으로의 해석 역할을 합니다. 여러 개의 attention 을 나눠 작업하면 더 다양한 정보가 모델에 저장된다고 합니다. 이는 마치 여러 관점으로 input sequence 를 해석하는 것과 같습니다. 이는 마치 VGG network 에서 5x5 convolution filter 하나 보다 3x3 convolution filter 두 개를 중첩하여 학습하면 패러매터의 숫자도 줄어들면서 더 좋은 성능을 보여준다는 맥락으로도 해석할 수 있을 것 같습니다.
이 때 두 input sequence item \(x_i\) 와 \(x_j\) 가 얼마나 멀리 떨어져 있던지 상관없이 attention 에 의하여 곧바로 연결이 됩니다. 하지만 RNN 에서는 떨어진 거리만큼의 path 가 필요합니다. RNN 은 두 정보를 연결하기 위하여 실제 문장에서의 거리만큼의 연산을 해야하고, 그 과정에서 정보가 손실되거나 노이즈들이 포함될 가능성이 높습니다. 그러나 attention 에서는 이 과정이 직접적으로 일어납니다.
그리고 그 결과를 ReLU 가 포함된 2 layers feed forward network 에 입력합니다. Multi-head attention 과정만으로는 정리되지 않은 정보를 재정리 하는 역할을 합니다.
![]()
지금까지의 과정은 각 시점별로 문장 전체의 정보들을 종합하여 새로운 문맥적인 정보를 만드는 것입니다. 이 값을 input item 에 더합니다. 이는 input sequence 에 포함되지 않은 문맥적인 정보를 input sequence 로부터 가공하여 input sequence 에 더한다는 의미입니다. 이를 residual connection 이라 합니다.
![]()
이 과정까지 거치면 encoder 에서의 한 번의 transformer block 을 통과한 것입니다. 이 과정을 6 번 거칩니다. Layer 의 높이가 올라갈수록 문맥적인 의미들이 추가됩니다.
Encoder 는 주어진 문장 전체를 살펴보며 각 시점의 정보들을 더 좋은 representation 으로 encoding 하는 역할을 합니다. Decoder 는 현재까지 알려진 정보를 바탕으로 새로운 문장을 생성하는 역할을 합니다. 그렇기 때문에 decoder 가 attention 을 이용할 때 지금 이후의 시점에 대한 정보를 사용할 수는 없습니다. 즉 \(x_i\) 와 연결될 수 있는 position 은 \(1, 2, \dots, i-1\) 입니다. 이처럼 attention 에 제약을 거는 과정을 masking 이라 합니다. Decoder 의 scaled dot-product attention 에는 이 과정이 포함되어 있습니다.
![]()
Decoder 가 단어를 생성할 때에는 encoder 의 정보도 필요합니다. Sequence to sequence 에서 source sequence \(h_j\) 를 이용한 것처럼 Transformer 에서도 encoder 의 마지막 layer 의 output sequence 의 값을 key, value 로 이용합니다. 이를 encoder - decoder attention 이라 합니다. 이처럼 query 와 key, value 의 출처가 서로 다른 경우를 주로 attention 이라 합니다. 하지만 앞서 설명한 encoder, decoder 에서의 attention 은 query, key, value 의 출처가 각각 encoder 혹은 decoder 였습니다. 이처럼 query 와 key, value 의 출처가 같은 경우를 self-attention 이라 합니다.
Encoder - decoder attention 은 decoder 가 \(x_i\) 의 정보를 표현하기 위하여 input sequence 의 item \(j\) 의 정보를 얼마나 이용할지 결정하는 역할을 합니다.
![]()
그리고 decoder 의 transformer block 에는 decoder self-attention 의 결과에 encoder - decoder attention 의 결과가 더해져서 feed-forward neural network 에 입력됩니다.
![]()
Transformer 는 매 block 마다 문맥적인 의미를 생성하여 sequence 에 더하는 방식으로 sequence representation 을 업데이트합니다. 그렇게하여 encoder 는 input sequence 의 의미를 잘 표현하는 sequence representation 을 만들고, decoder 는 이 정보를 이용하며 질 좋은 output sequence representation 을 만듭니다. Update 라는 표현을 쓴 이유는 새롭게 만든 정보를 residual connection 을 통하여 block 의 input 에 그대로 더해주기 때문입니다. 의미를 보강하는 역할을 합니다.
Attention weight matrix 에 의하여 그 결과도 확인할 수 있습니다. 아래 그림은 영어를 프랑스어로 번역하는 과정에서의 encoder layer 5 번에서 6 번으로의 attention 입니다. 대명사의 의미에 대한 정보가 그 대명사와 의미적으로 연결된 단어들의 정보로부터 만들어집니다.
![]()
이러한 과정은 더 이상 encoder 의 역할이 단어를 표현하는 것이 아니란 점을 의미합니다. 한 단어 ‘bank’ 는 문맥에 따라서 은행 혹은 강둑으로 해석될 수 있지만, word embedding vector 는 우리가 word sence disambiguation 을 하기 전까지는 고정이 되어 있습니다. 만약 문장에 ‘road’ 라는 단어가 있었다면 이 정보를 반영하여 은행이라는 의미에 가까운 representation 으로, ‘river’ 가 있었다면 강둑에 가까운 의미로 ‘bank’ 의 representation 을 변화할 수 있습니다.
After starting with representations of individual words or even pieces of words, they aggregate information from surrounding words to determine the meaning of a given bit of language in context. For example, deciding on the most likely meaning and appropriate representation of the word “bank” in the sentence “I arrived at the bank after crossing the…” requires knowing if the sentence ends in “… road.” or “… river.”
Transformer 는 다른 모델들보다 패러매터의 숫자가 적고, feed-forward 를 이용하기 때문에 병렬화가 쉽습니다. 빠른 연산이 가능합니다. 그럼에도 불구하고 멀리 떨어진 단어 간의 정보가 곧바로 연결되기 때문에 정확한 모델링도 가능합니다.
BERT (language model using transformer)
BERT 는 Transformer 를 이용하여 학습한 언어 모델 입니다. BERT 는 pre-trained model 로, 여기에 sentence classification 이나 sequential labeling 를 추가하여 fine-tuning 하여 이용합니다. BERT 는 Transformer 의 구조를 이해하면 구조적으로는 특별한 점은 없습니다. 단 pre-training task 의 방식이 특이합니다.
Pre-training task 는 이 모델의 목적과 상관없이 학습하는 task 입니다. 모델은 학습해야 하는 방향을 설정해줘야 loss 를 정의할 수 있습니다. 예를 들어 분류 문제의 경우에는 분류 정확도가 될 수 있습니다. 그런데 어떤 목적에 이용될지 모르니, 왠만한 tasks 에 도움이 될법한 다른 tasks 로 모델의 학습 방향을 설정하는 것을 pre-training task 라 합니다. BERT 는 language model 을 학습합니다. Language model 은 앞에 등장한 단어 \(x_1, x_2, \dots, x_{i-1}\) 을 이용하여 \(x_i\) 를 예측하는 문제입니다. 그런데 BERT 는 조금 다르게 문장의 임의의 단어를 맞추는 방식의 masked language model 이라는 pre-training task 를 이용합니다.
BERT 의 input 구조도 다른 language model 과 다릅니다. 데이터에서 연속된 두 개의 문장을 붙여 하나의 input 에 입력합니다. 앞 문장의 맨 앞에는 [CLS] 를, 각 문장의 끝 부분에는 [SEP] 이라는 special token 을 입력합니다. 그리고 이들에 대한 token embeddings 을 lookup 합니다. Special tokens 도 각각 token embedding vectors 가 하나씩 존재합니다.
거기에 segment embeddings 도 lookup 합니다. 앞 문장은 \(E_A\), 뒷 문장은 \(E_B\) 를 lookup 하여 더해줍니다. 이는 각 단어가 소속된 문장에 대한 정보를 간접적으로 표현하는 정보입니다. 그리고 token 위치에 따른 position embedding vectors 도 더해줍니다. 즉 각 token 별로 세 개의 embedding vectors 가 lookup 되어 더해집니다.
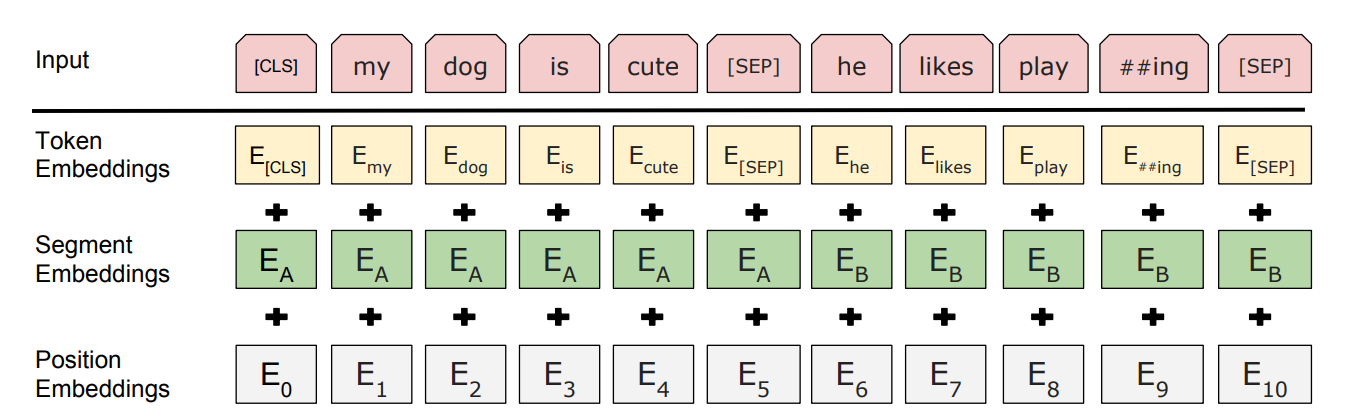
Masked Language Model 은 문장 내 단어의 일부를 [mask] 라는 special token 으로 치환한 뒤, 이 단어가 원래 무엇이었는지를 맞추는 문제입니다. Word2Vec 이 앞/뒤의 \(w\) 개의 단어를 이용하여 가운데 단어를 맞추는 것과 비슷합니다. 각 문장마다 15 % 의 단어를 임의로 맞출 것입니다. 그런데 그 15 % 의 단어를 모두 [mask] 로 치환하지는 않습니다. 15 % 중 80 % 는 실제로 [mask] 로 치환하고, 10 % 는 상관없는 임의의 단어, 나머지 10 % 는 단어를 그대로 유지합니다. 그리고 모두 다 원래 무슨 단어였는지를 맞춥니다. 이는 모든 단어를 [mask] 로 변환하면 그 과정에서도 bias 가 생기기 때문입니다.
논문의 예시에서는 “my dog is hairy” 라는 문장에서 “hairy” 를 맞추는 것으로 formulation 이 되었습니다. 그리고 각각 아래의 확률로 문장이 치환됩니다.
- “my dog is [mask]” (80%)
- “my dog is apple” (10%)
- “my dog is hairy” (10%)
이 말고도 한 가지 pre-training task 를 동시에 풉니다. 두 개의 문장이 연속되기 때문에 앞의 문장을 input 으로, 뒤의 문장이 실로 뒤에 위치하는지 판별하는 문제를 풉니다. 이를 위하여 50 % 는 실제 문장으로, 나머지 50 % 는 데이터에서 임의로 선택한 문장을 가지고 옵니다. 이는 Q&A 와 같이 두 개의 문장을 동시에 이용하는 tasks 를 위하여 문장 내 상관성을 BERT 모델에 학습하기 위해서 입니다.
학습된 BERT 는 그 목적에 따라 서로 다른 output 을 이용합니다. 예를 들어 sentence similarity 와 같이 두 개의 문장이 입력되어야 하는 경우에는 [CLS] 의 output vector 가 이용됩니다. Sentence classification 과 같은 작업에서도 [CLS] 의 output vector 를 이용합니다. Sequential labeing 에서는 각 단어에 해당하는 output 을 이용합니다.
각 목적에 맞는 모델 (classifier, sequential labeler) 의 input 으로 이들을 입력한 뒤, task model 의 loss 를 이용하여 fine-tuning 을 하여 최종 모델을 만듭니다.
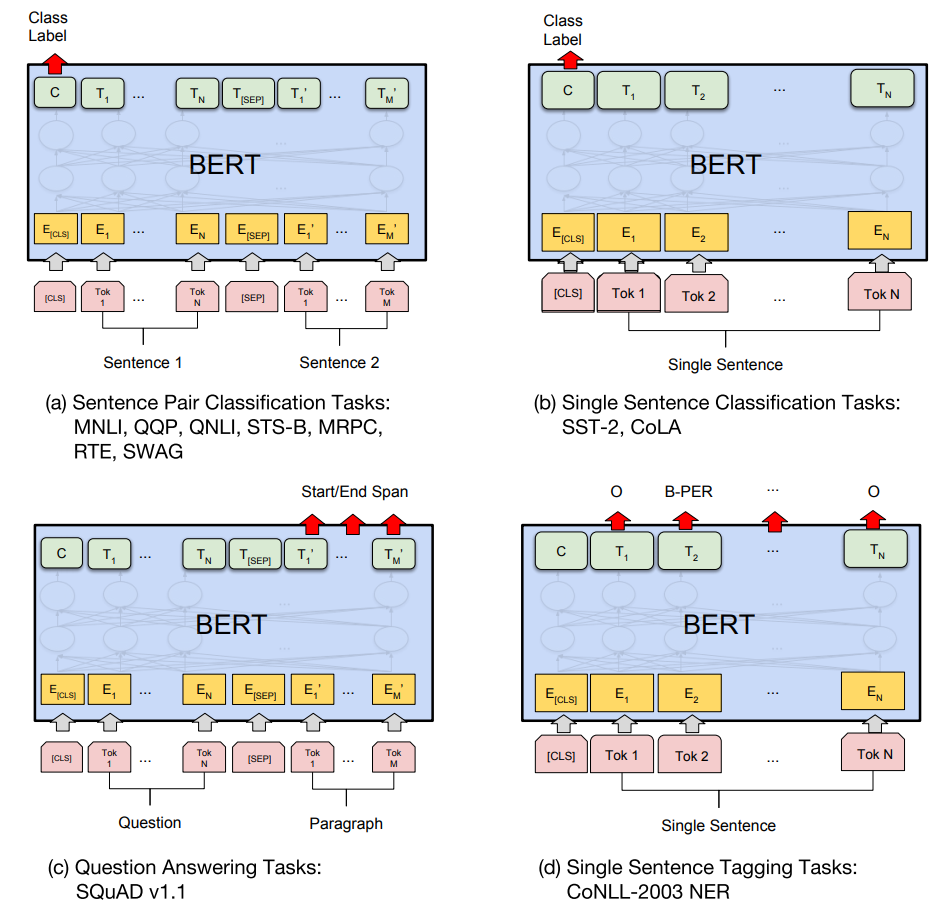
BERT 의 놀라운 점은 Wikipedia 나 BookCorpus 와 같은 일반적인 corpus 를 이용하여 학습한 단일 모델을 이용하여 11 개의 NLP tasks 에서 모두 state of the art 를 기록한 것입니다. 이는 그만큼 질 좋은 language model 이 학습되었다는 것을 의미합니다. 두번째 놀라운 점은 resource 입니다. 크기가 서로 다른 모델 두 가지를 언급했는데, 작은 모델도 4 개의 TPU 를 이용하여 4 일간 학습하였다고 합니다. TPU 는 Google 이 딥러닝과 같은 계산을 위하여 만든 하드웨어입니다. 개인이 시도하기에는 불가능한 수준의 스케일로 모델을 학습시키고, 그 결과로 여러 tasks 의 성능을 향상시켰습니다. Google 은 가끔씩 Google 만이 할 수 있는 연구들을 선보입니다. 모든 문제가 대량의 리소스를 이용한 방식으로 계산되어야 하는 것은 아니겠지만, 적어도 language model 에서는 이러한 방식이 효과가 있어 보입니다.
References
- Bahdanau, D., Cho, K., & Bengio, Y. (2014). Neural machine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473.
- Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C. (2003). A neural probabilistic language model. Journal of machine learning research, 3(Feb), 1137-1155.
- Cho, K., Van Merriënboer, B., Gulcehre, C., Bahdanau, D., Bougares, F., Schwenk, H., & Bengio, Y. (2014). Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078.
- Devlin, J., Chang, M. W., Lee, K., & Toutanova, K. (2018). Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805.
- Joulin, A., Grave, E., Bojanowski, P., & Mikolov, T. (2016). Bag of tricks for efficient text classification. arXiv preprint arXiv:1607.01759.
- Lin, Z., Feng, M., Santos, C. N. D., Yu, M., Xiang, B., Zhou, B., & Bengio, Y. (2017). A structured self-attentive sentence embedding. arXiv preprint arXiv:1703.03130.
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
- Sutskever, I., Vinyals, O., & Le, Q. V. (2014). Sequence to sequence learning with neural networks. In Advances in neural information processing systems (pp. 3104-3112).
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., … & Polosukhin, I. (2017). Attention is all you need. In Advances in Neural Information Processing Systems(pp. 6000-6010).
- Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A., Salakhudinov, R., … & Bengio, Y. (2015, June). Show, attend and tell: Neural image caption generation with visual attention. In International conference on machine learning (pp. 2048-2057).
- Yang, Z., Yang, D., Dyer, C., He, X., Smola, A., & Hovy, E. (2016). Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (pp. 1480-1489).