Carblog 는 데이터분석 사례의 프로젝트이름 입니다. Carblog 는 키워드 기반으로 수집된 문서 집합에서 의도한 문서 만을 선택하는 문제입니다. 네이버 블로그에 차량 이름을 쿼리로 입력하여 데이터를 수집하였습니다. 하지만 하나의 단어는 여러 의미를 지닙니다. 소나타는 차량의 이름이기도 하지만, 클래식 음악의 형식이기도 합니다. 혹은 가수 아이비의 “유혹의 소나타”라는 노래 제목에 포함된 단어이기도 합니다. 키워드 기반으로 수집된 문서에는 우리가 예상하지 못한 수많은 주제의 문서들이 포함되어 있습니다. 학습데이터를 마련하여 문서 판별기를 만들 수도 있겠지만, 학습데이터를 만드는 과정이 고통스럽습니다. 좀 더 멋지게 데이터 기반으로 학습데이터를 마련하지 않고서 차량 문서들만을 선택하는 필터를 만듭니다.
Carblog Introduction
예전에 다른 팀의 연구를 도와준 적이 있었습니다. 한국에서 판매되는 여러 차량의 버즈 분석을 수행하기 위하여 차량 관련 문서들을 수집해야 했습니다. 데이터의 수집 방식은 네이버 블로그에 질의어를 입력하여, 해당 질의어가 포함된 문서들을 수집하는 방식이었습니다. 아래 표의 27 개의 질의어를 이용하여 2010. 1 ~ 2015. 7 에 작성된 블로그, 2,844,955 건을 수집하였습니다. 누구라도 아래의 27 개 질의어로부터 수집하고자 했던 문서의 implicit label 이 차량이라는 것은 알 수 있을 것입니다.
| A6 | BMW5 | BMW | K3 | K5 | K7 | QM3 |
| 그랜저 | 벤츠E | 산타페 | 소나타 | 스포티지 | 싼타페 | 쏘나타 |
| 쏘렌토 | 아반떼 | 아반테 | 제네시스 | 코란도C | 투싼 | 티구안 |
| 티볼리 | 파사트 | 폭스바겐골프 | 현기차 | 현대자동차 | 현대차 |
하지만 문제가 발생했습니다. 하나의 단어에는 여러 개의 의미가 포함되어 있습니다. 왠만한 단어는 다의어입니다. 우리가 발견했던, 차량 외 주제들입니다. 아주 조금만 예를 든 것일 뿐, 사실은 엄청나게 많은 주제들이 도사리고 (under cover) 있습니다.
| 질의어 | 차량 외 주제 |
|---|---|
| A6 | 광교신도시A6블록 / 갤럭시탭A6 |
| K3 | 홍콩 관광버스 노선번호 / 한국축구 리그 / 슈퍼스타K3 / 비타민K3 |
| 소나타 | 클래식 음악 형식 / 아이비의 유혹의 소나타 |
| 제네시스 | 락벤드 / 피부치료 / 탄산수제조기 / 터미네이터4 / 메이플스토리 캐릭터 기술 |
| 티볼리 | 리조트 이름 / 코펜하겐 티볼리 공원 / 루이뷔동 백이름 / 이탈리아 도시 |
그렇다면 우리는 왜 이 많은 주제의 문서들을 제거해야 할까요? 아래는 달 별로 K3 를 포함한 문서의 개수에 대한 line chart 입니다. 사실 기아자동차의 K3 는 2012 년에 출시되었습니다. 2011 년도에는 슈퍼스타 K3 가 한창 진행되던 시기입니다. 이 때 생성된 블로그들은 사실 차량 관련 문서가 아니라 슈퍼스타 K3 에 관련된 문서인 것이죠. 또한 2011 년도 이전에도 매달 500 여건 정도의 K3 를 포함한 문서가 발생합니다. 슈퍼스타 외에도 다른 의미의 K3 가 있음이 분명합니다.
우리는 차량 외 주제의 문서들을 제거해야 정확한 버즈 분석을 수행할 수 있겠군요. 이제부터는 각 질의어를 카테고리라 명하겠습니다. 이후 “Carblog” 태그가 붙은 문서들에서 이용되는 카테고리라는 의미는 해당 질의어가 포함된 문서집합 입니다.
List-up problems
우리는 앞서 언급한 문제를 차량 외 주제의 문서를 제거하는 것이라 정의하겠습니다. 이 문제를 풀 수 있는 방법은 다양할 것입니다. 그 중 하나는 군집화 방법을 이용하는 것입니다. 문서 군집화 알고리즘을 학습하면 비슷한 주제의 문서들이 하나의 군집을 이룰 것입니다. 그 중에서 차량 외 주제를 포함하는 군집들을 뭉탱이로 제거할 수도 있겠네요. 각 문서에 대하여 하나씩 확인하는 것보다 훨씬 효율적이라 생각됩니다.
혹은 각 문서의 토픽을 찾을 수도 있을 겁니다. 우리는 직관적인 통계를 하나 이용할 수 있습니다. 분명 위 카테고리에 포함된 다수의 문서들은 차량 관련 문서일 것입니다. 그렇기 때문에 ‘차량’, ‘엔진오일’과 같은 단어를 포함하는 문서는 여러 카테고리에 골고루 존재할 것입니다. 하지만 ‘터미네이터’는 ‘제네시스’ 카테고리에서만 등장할 것입니다. ‘악장’이라는 단어도 ‘소나타’ 카테고리에서 유독 많이 등장합니다. Implicit 한 label 이 존재합니다. 이를 잘 이용한다면 어쩌면 우리는 문서의 토픽을, 적어도 문서의 토픽이 차량인지 아닌지 정도는 구분할 수 있을 것 같습니다.
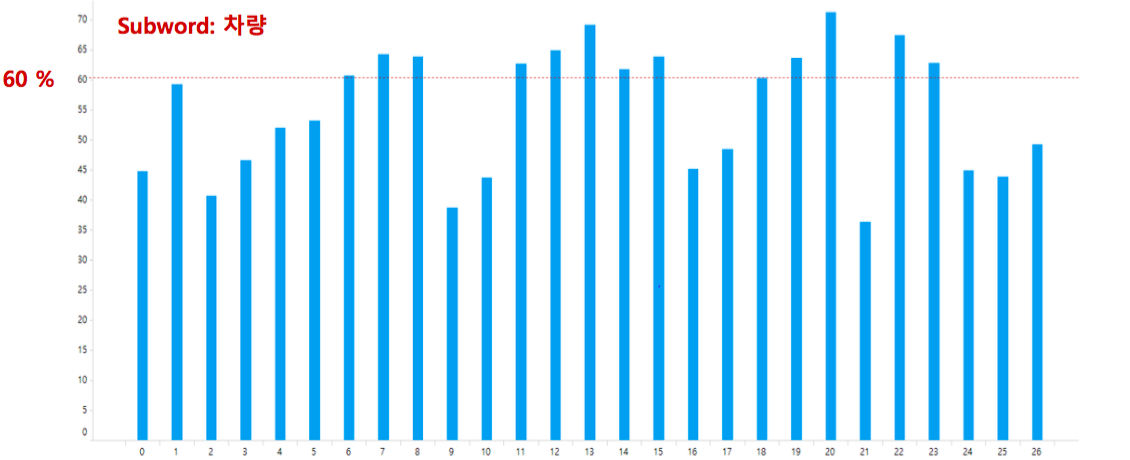
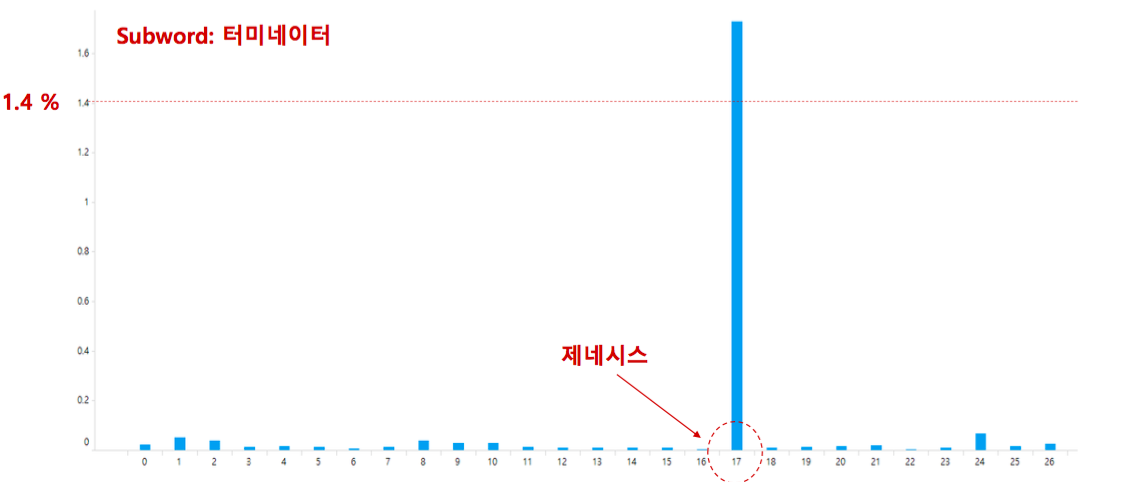
카테고리 별로 차량 외 주제들이 존재하지만, 그 양은 차량과 비교하면 매우 작습니다. Class imbalance 현상이 존재합니다. 이 때에는 Latent Dirichlet Allocation (LDA) 와 같은 토픽 모델링이나 k-means 와 같은 문서 군집화 방법들이 잘 학습되지 않습니다. 경험을 기반으로 하는 머신 러닝 알고리즘들은 많이 등장하는 클래스의 데이터의 패턴을 더 잘 학습하기 때문입니다. Minor topic discovery 역시 이 데이터로 풀어볼 수 있는 재미있는 문제입니다.
텍스트 데이터를 분석하기 위해서는 문장을 단어열로 분해하는 토크나이징 (tokenizing) 과정을 거쳐야 합니다. 이때에는 품사 판별을 포함한 다양한 방법들이 이용될 수 있습니다. 하지만 블로그 데이터에서는 KoNLPy 에서 제공되는, 다른 말뭉치로 학습된 형태소 분석기 / 품사판별기와 같은 엔진들이 잘 작동하지 않습니다. 미등록단어 (out of vocabulary) 문제가 발생합니다. 미등록단어 문제를 간단히 설명하면, 모델이 학습 때 보지 못했던 단어에 대하여 엉뚱하게 처리를 하는 것입니다. ‘폭스바겐골프’ 라는 자동차 명을 한 번도 학습하지 못했다면, 여우인 ‘폭스’, 그리고 스포츠 ‘골프’를 단어로 인식하여 ‘폭스 - 바겐 - 골프’로 잘못 분해할 수도 있습니다. 이를 해결하는 것도 한 가지 문제이겠네요.
이 데이터를 통하여 우리는 다양한 문제를 풀어볼까 합니다. 지금까지 언급한 재밌는 데이터분석 문제를 나열하면 아래와 같습니다.
- 문서 군집화를 이용한 차량 외 문서 제거
- Major topic 추출을 통한 차량 외 문서 제거
- Class imbalanced 인 minor topic 추출을 통한 차량 외 문서 제거
- 미등록단어 문제를 해결하는 토크나이저
Thanks to
Carblog 분석 프로젝트를 함께 하는 Dongyoung Min에게 감사를 드립니다.