코모란 (KOrean MORphological ANalyzer) 은 자바로 구현된 한국어 형태소 분석기입니다. KoNLPy 에도 포함되어 있습니다. 지금은 version 3.x 가 공개되었고, KoNLPy 에는 version 2.x 가 포함되었습니다. 두 버전의 자바 사용방법과 version 3.x 를 Jupyter notebook 의 Python 환경에서 이용하도록 하는 방법을 기록하였습니다. 코모란이 제공하는 사용자사전 추가 기능을 Python 에서도 이용하는 방법도 포함되어 있습니다.
Install Komoran (Java)
코모란은 shin285 님이 공개하신 한국어 형태소 분석기 입니다. Java 로 구현되어 있으며, shineware github 에는 version 2.x 가, shin285 의 github 에는 version 3.x 가 공개되어 있습니다.
Version 2.x 에서는 다음의 library 의 dependency 가 있습니다. 코모란에서 이용하는 자료구조와 utils 입니다.
Version 3.x 에서는 이 둘 외에도 aho-corasick 가 필요합니다. 각 library 의 github 의 링크를 걸어뒀습니다.
git clone 을 이용하여 코드를 받는다면 dependency 가 있는 라이브러리들을 각각 clone 해야 합니다.
Making JAR file
Dependency 가 있는 라이브러리를 jar 파일로 만든 뒤 추가합니다. Project 를 추가할 수도 있지만 Python 환경에서 이용하기 위하여 어자피 jar 파일을 만들겁니다. jar 는 Java ARchive 의 약자로, 자바 클래스 파일과 데이터 파일들이 합쳐진 파일입니다. 배포용으로 압축할 때 이용됩니다.
Java 를 이용하기 위하여 eclipse 를 이용하였습니다. 자바 및 eclipse 설치는 구글링하면 좋은 블로그들이 많이 검색됩니다. 코모란이 이용하는 commons, ds, aho-corasick 을 eclipse 를 이용하여 jar 파일로 만듭니다.
먼저 eclipse 를 켜고, git clone 을 한 Java project 를 입력합니다. Eclipse 의 Package Explorer 칸에서 우클릭 (Right clock) 을 하여 New » Java Project 를 누릅니다.
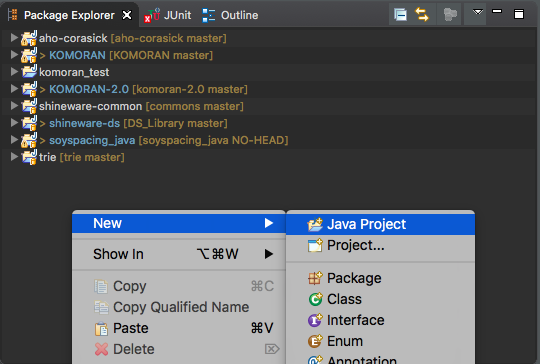
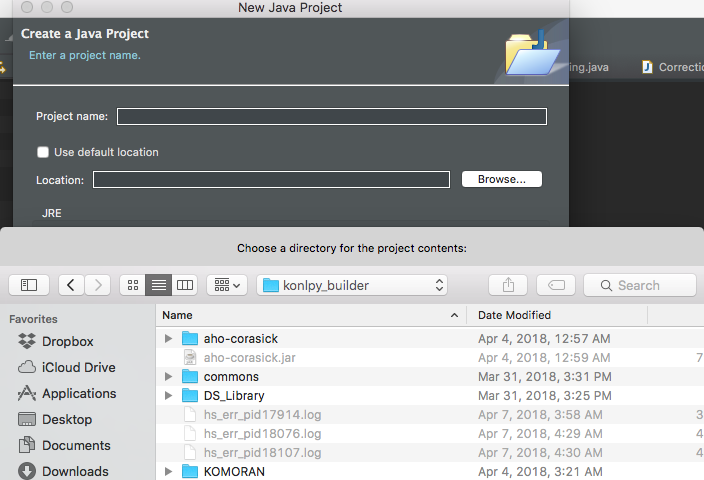
Default 는 “use default location” 이 클릭되어 있습니다. Workspace 에 새로운 폴더를 만드는 것인데, 이 체크를 풀고 Browse 를 누릅니다. 이미 존재하는 directory 를 가져올 수 있습니다. git clone 이 된 폴더를 찾아 Ok 를 누릅니다.
Package Explorer 에 추가한 프로젝트가 보입니다. shineware-commons, shineware-ds, aho-corasick 폴더를 각각 우클릭합니다. Export » Java » JAR file 를 누릅니다. 필요한 파일들을 클릭한 뒤, jar file path 에 이름을 절대주소로 입력하면 jar file 이 만들어집니다.
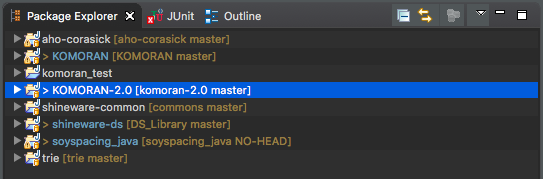
Komoran 2.x (Java)
위와 동일한 방법으로 git clone 한 코모란 2.x 의 폴더를 Java project 에 추가합니다. 이제 우리가 만든 jar 파일을 추가합니다. Package Explorer 의 코모란 폴더를 우클릭 한 뒤 Properties 를 누릅니다. 왼쪽의 Java Build Path 를 누른 뒤, 우측 상단의 Libraries 를 누릅니다.
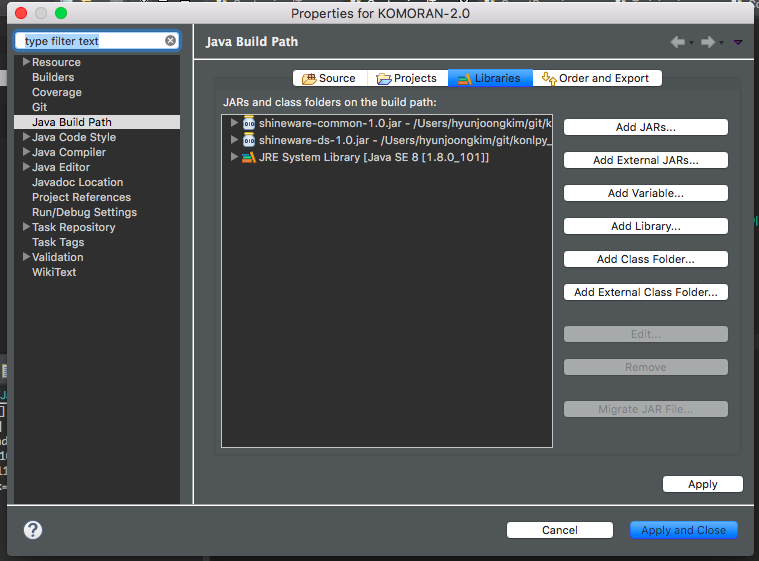
Java project 안의 폴더에 있는 jar 라면 Add JARs 를, Java project 밖에 위치한 jar 파일을 이용하려면 Add External JARs 를 누릅니다. 우리가 만든 jar 파일들을 클릭하여 OK 를 누릅니다. Path 가 제대로 입력되었다면 위 그림처럼 우리가 추가한 라이브러라기 화면이 보입니다.
코모란 코드에는 unittest 라이브러리인 JUnits 도 포함되어 있습니다. Properties » Libraries » Add Library 를 누르시면 JUnits 를 이용할 수 있습니다.
코모란 2.x 의 생성자는 model directory 주소를 입력해야 합니다. git clone 된 폴더의 models 에는 아래와 같은 네 개의 모델 파일이 있습니다. 이 폴더의 주소를 modelPath 로 입력합니다.
Komoran komoran = new Komoran(modelPath);- irregular.model
- observation.model
- pos.table
- transition.model
analyze() 함수에 String 을 입력하면 형태소 분석 결과를 return 합니다.
String sentences = "";
komoran.analyze(sentences);analyze 는 sentence segmentation 까지 고려한 함수라 생각됩니다. Return type 이 List<List<[TOKEN]]» 형태입니다. Pair<String, String> 은 commons 의 class 입니다.
우리는 한 문장을 입력하였으니, List 의 첫번째 item 을 가져와서 그 결과를 확인해 봅니다.
import kr.co.shineware.nlp.komoran.core.analyzer.Komoran;
import kr.co.shineware.util.common.model.Pair;
public class KomoranTest {
public static void main(String[] args) {
String modelPath = "models";
Komoran komoran = new Komoran(modelPath);
List<List<Pair<String, String>>> sentences = komoran.analyze("청하는아이오아이출신입니다");
List<Pair<String, String>> sentence = sentences.get(0);
for (Pair<String, String> token : sentence)
System.out.println(token);
}
}Pair 의 first, second 는 각각 단어와 품사정보 입니다. token.getFirst(), token.getSecond() 를 하면 각각 String return 이 됩니다. ‘아이오아이’는 미등록단어 문제가 발생합니다.
Pair [first=청하, second=VV]
Pair [first=는, second=ETM]
Pair [first=아이오, second=NNP]
Pair [first=아이, second=NNG]
Pair [first=출신, second=NNG]
Pair [first=이, second=VCP]
Pair [first=ㅂ니다, second=EC]
코모란은 사용자사전을 추가할 수 있는 기능을 제공합니다. dic.user 파일에 단어를 추가하였습니다. 사용자사전 파일은 단어와 품사가 tap 구분이 된 형식입니다.
아이오아이 NNP
사용자사전은 setUserDic() 에 파일주소를 입력하면 됩니다.
komoran.setUserDic("user_data/dic.user");
komoran.analyze("청하는아이오아이출신입니다");다시 analyze() 함수를 실행시키면 사용자 사전의 단어로 형태소 분석이 되었음을 확인할 수 있습니다.
Pair [first=청하, second=VV]
Pair [first=는, second=ETM]
Pair [first=아이오아이, second=NNP]
Pair [first=출신, second=NNG]
Pair [first=이, second=VCP]
Pair [first=ㅂ니다, second=EC]
Komoran 3.x (Java)
코모란 3.x 의 사용법은 2.x 와 비슷합니다. aho-corasick 라이브러리만 하나 더 추가합니다. DEFAULT_MODEL.FULL 과 .RIGHT 가 있습니다. 저는 full model 을 이용하였습니다. Version 2.x 처럼 직접 model directory path 를 입력할 수도 있습니다.
analyze() 함수의 return 에서 getTokenList() 를 하면 List
import java.util.List;
import kr.co.shineware.nlp.komoran.constant.DEFAULT_MODEL;
import kr.co.shineware.nlp.komoran.core.Komoran;
import kr.co.shineware.nlp.komoran.model.Token;
public class CustomizedTest {
public static void main(String[] args) {
Komoran komoran = new Komoran(DEFAULT_MODEL.FULL);
komoran.setUserDic("user_data/dic.user");
List<Token> tokens = komoran.analyze("청하는아이오아이출신입니다").getTokenList();
for(Token token : tokens)
System.out.println(token);
}
}Token 에는 morph, pos, begin, end index 가 포함되어 있습니다.
Token [morph=청하, pos=VV, beginIndex=0, endIndex=2]
Token [morph=는, pos=ETM, beginIndex=2, endIndex=3]
Token [morph=아이오아이, pos=NNG, beginIndex=3, endIndex=8]
Token [morph=출신, pos=NNG, beginIndex=8, endIndex=10]
Token [morph=이, pos=VCP, beginIndex=10, endIndex=11]
Token [morph=ㅂ니다, pos=EC, beginIndex=10, endIndex=13]
각각의 정보를 가져오는 방법과 return type 은 아래와 같습니다.
tokens.get(0).getBeginIndex(); // int
tokens.get(0).getEndIndex(); // int
tokens.get(0).getMorph(); // String
tokens.get(0).getPos(); // StringKOMORAN in Python (Jupyter notebook)
코모란 3.x 를 Python 에서 이용할 수 있습니다. KoNLPy 의 역할이 바로 코모란과 같은 Python 이 아닌 다른 언어로 구현된 코드를 Python 에서 이용할 수 있도록 도와주는 것입니다. .py 파일로 만드는 부분에 대해서는 아직 정리를 완료하지 못했습니다. 그전에 jupyter notebook 의 Python kernel 에서 자바 프로젝트를 이용하는 방법에 대하여 먼저 기록합니다.
이를 위해서는 Jpype2 가 필요합니다.
pip install Jpype2
Jpype 는 Python 에서 JVM 을 띄운 뒤, 서로 통신을 하는 라이브러리입니다. JVM 을 띄울 때 우리가 이용할 libraries 를 모두 입력합니다. 이를 위하여 앞서 jar 파일을 만들었습니다.
코모란이 이용할 모델과 jar 파일의 위치가 다를 수도 있으니 model_path, library_directory 를 따로 떼어뒀습니다. max_memory 는 JVM 이 이용할 최대 메모리 크기입니다. 1 Gb 로 설정하였습니다.
# User parameters
model_path='./komoran/models'
library_directory = './komoran/libs'
max_memory=1024
# Library paths
libraries = [
'{}/aho-corasick.jar',
'{}/shineware-common-1.0.jar',
'{}/shineware-ds-1.0.jar',
'{}/komoran-3.0.jar'
]
# classs path and jvm path
classpath = os.pathsep.join([lib.format(library_directory) for lib in libraries])
jvmpath = jpype.getDefaultJVMPath()
# Running JVM
jpype.startJVM(
jvmpath,
'-Djava.class.path=%s' % classpath,
'-Dfile.encoding=UTF8',
'-ea', '-Xmx{}m'.format(max_memory)
)jpype 에 의하여 생성된 JVM 에는 우리가 추가한 library 가 있습니다. Java 에서 Komoran class 를 import 할 때와 똑같이 package 주소를 JPackage 안에 입력합니다. 해당 패키지의 Komoran 클래스를 이용할 때에는 package.Komroan 이라 하면 됩니다. Java 코딩을 Python 에서 하면 됩니다.
package = jpype.JPackage('kr.co.shineware.nlp.komoran.core')
komoran = package.Komoran(model_path)사용자 사전을 추가하는 함수는 setUserDic() 였습니다. Python 에서도 이 함수를 이용하기 위하여 set_user_dictionary() 를 만듭니다.
def set_user_dictionary(path):
komoran.setUserDic(path)analyze().getTokenList() 의 return type 은 jpype 를 통하여 JVM 에 띄어진 java.util.ArrayList 입니다.
print(komoran.analyze(sent).getTokenList())jpype._jclass.java.util.ArrayList
Java 에서의 코드를 그대로 가져오면 됩니다. KoNLPy 의 [(str morph, str pos)] 형식의 pos() 함수를 만들기 위해서 tokens 를 자바처럼 코딩합니다.
def pos(sent):
tokens = komoran.analyze(sent).getTokenList()
tokens = [(token.getMorph(), token.getPos()) for token in tokens]
return tokens이 함수들을 모두 종합하여 Komoran python class 를 만듭니다.
import jpype
import os
class Komoran:
def __init__(self, model_path='./komoran/models',
library_directory = './komoran/libs', max_memory=1024):
libraries = [
'{}/aho-corasick.jar',
'{}/shineware-common-1.0.jar',
'{}/shineware-ds-1.0.jar',
'{}/komoran-3.0.jar'
]
classpath = os.pathsep.join([lib.format(library_directory) for lib in libraries])
jvmpath = jpype.getDefaultJVMPath()
try:
jpype.startJVM(
jvmpath,
'-Djava.class.path=%s' % classpath,
'-Dfile.encoding=UTF8',
'-ea', '-Xmx{}m'.format(max_memory)
)
except Exception as e:
print(e)
package = jpype.JPackage('kr.co.shineware.nlp.komoran.core')
self.komoran = package.Komoran(model_path)
def set_user_dictionary(self, path):
self.komoran.setUserDic(path)
def pos(self, sent):
tokens = self.komoran.analyze(sent).getTokenList()
tokens = [(token.getMorph(), token.getPos()) for token in tokens]
return tokensJpype 를 처음 써보기 때문에 Jpype 에서 서로 주고받을 수 있는 데이터 타입에는 어떤 것들이 있는지 확인하지 못했습니다. 여기서 확인한 것은 String 뿐입니다.
Todo: Packaging as python library
Jupyter notebook 에서는 위 코드가 잘 작동함을 확인하였습니다. 하지만 하나의 Python kernel 에서 여러 개의 JVM 을 띄울 수가 없습니다. 또한 .py 파일로 만드는 과정에서 몇 가지 오류가 발생하였는데, 이를 해결하여 python library 로 만들어둬야겠습니다.