이전 포스트에서 한국어 어절의 특징인 L + [R] 구조를 이용하여 통계 기반으로 명사를 추출하는 방법을 제안하였습니다. 통계는 대부분 major pattern 에 유리합니다. 통계적으로 유의할 만큼의 관찰이 없으면 잘못된 판단을 하기 쉽습니다. Unsupervised algorithms 는 exception 을 잘 처리할 수 있는 탄탄한 논리가 필요합니다. 이번 포스트에서는 이전 포스트의 명사 추출 방법이 잘못된 판단을 할 수 있는 위험 요소들을 살펴보고 이를 해결하는 방법들을 소개합니다.
Brief review of previous post. Noun extraction
이번 포스트는 이전 포스트에서 제안한 LRNounExtractor 에 대한 내용을 전제로 합니다.
한국어는 5언 9 품사로 이뤄져 있습니다. 그 중 한국어로 이뤄진 텍스트의 70 % 이상이 체언 (명사, 수사, 대명사) 입니다. 명사는 어떤 개념을 설명하기 위한 단어입니다. 텍스트의 도메인마다 다른 개념들이 존재하기 때문에 각 도메인마다 서로 다른 명사들이 존재합니다. 그렇기 때문에 명사에 의한 미등록단어 문제가 가장 심각합니다. 그러나 사람은 새로운 도메인이라 하더라도 몇 개의 문서만 읽어보면 새로운 명사를 제대로 인식할 수 있습니다. 이는 한국어 어절 구조에 특징이 있기 때문입니다.
한국어의 어절은 L + [R] 구조입니다. 띄어쓰기가 제대로 되어있다면 한국어는 의미를 지니는 단어 명사, 동사, 형용사, 부사, 감탄사가 어절의 왼쪽 (L part)에 등장합니다. 문법 기능을 하는 조사는 어절의 오른쪽 (R part)에 등장합니다. 앞서 전성어미를 이야기하였습니다. ‘시작했던’의 ‘했던’을 조사로 취급한다면 ‘시작/명사 + 했던/조사’이 됩니다. 명사, 부사, 감탄사는 그 자체로 단일 어절을 이루기도 합니다. 반드시 R part 가 필요하지 않습니다. 그렇기 때문에 어절의 구조를 L + [R] 로 생각할 수 있습니다.
A가 어떤 단어인지는 모르지만 명사로 유추할 수 있습니다. A 오른쪽에 우리에게 익숙한 조사들이 3번 모두 등장하였기 때문입니다.
- 어제 A라는 가게에 가봤어
- A에서 보자
- A로 와줘
하지만 규칙을 이용하는 것은 무리가 있습니다. ‘-은, -는, -이, -가’는 우리가 자주 이야기하는 조사들입니다. 하지만, ‘하/어근 + 는/어미’, ‘받/어근 + 은/어미’ 처럼 대표적으로 이용되는 어미이기도 합니다. 에이핑크 맴버인 ‘손나은’도 ‘손나/명사 + 은/조사’가 아닙니다. 그러나 ‘손나은 + -이, -의, -에게’ 처럼 ‘손나은’의 오른쪽에 다양한 조사들이 등장합니다. 하나의 규칙보다는 전체적인 R parts 의 분포를 살펴봐야 합니다.
드라마의 오른쪽에는 ‘-를, -다, -의, -로’와 같은 단어들이 등장합니다. 반대로 이들의 앞, L parts 에는 명사가 등장할 가능성이 높습니다.
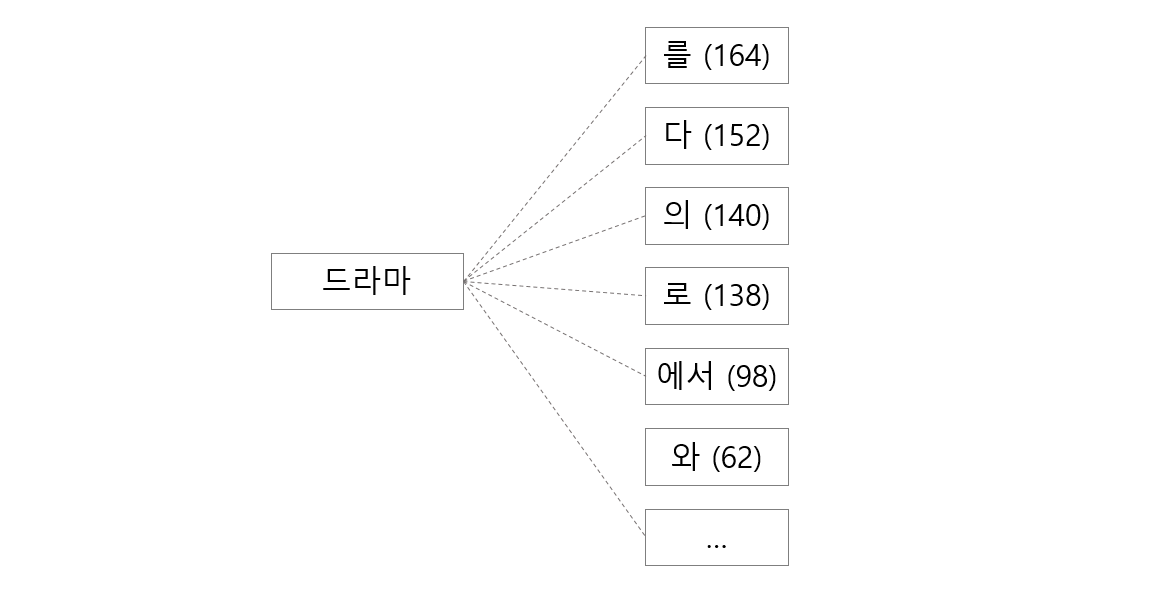
이는 R parts 를 이용하여 L parts 가 명사인지 아닌지를 분류하는 text classification 문제입니다. Logistic regression 이나 Naive Bayes 와 같이 bag of words model 에서 잘 작동하는 classifiers 의 coefficients 를 R parts 의 점수로 이용할 수 있습니다. ‘드라마’의 오른쪽에 등장한 R parts 의 빈도수를 고려한 weighted sum 으로 ‘드라마’가 명사인지를 판단 할 수 있습니다.
위 방법만으로는 명사가 아닌 단어들이 명사로 추출되는 경우들이 발생합니다. ‘떡볶이’는 다른 조사들과 함께 자주 등장하여 명사로 추출됩니다. 하지만 명사는 단일 명사가 하나의 어절이 되기도 합니다. ‘-이’는 대표적인 조사이기 때문에 ‘떡볶’ 역시 높은 명사 점수를 받을 수 있습니다. 이 경우를 방지하기 위하여 ‘떡볶이’가 명사이고 끝 부분의 1음절이 조사인 경우는 추출된 명사에서 제외합니다.
‘대학생으로’ 역시 ‘대학생’이 명사이지만, ‘-로’ 가 대표적인 조사이기 때문에 ‘대학생으’도 명사로 추출됩니다. 이번에는 떡볶이와 반대의 경우로 더 긴 단어의 마지막 글자와 그 뒤에 자주 등장하는 R parts 를 합쳤을 때 (-으 + -로) 조사이면 이를 추출된 명사에서 제외합니다.
위의 방법으로도 도메인에 특수한 명사들이 잘 추출됨을 확인할 수 있었습니다. 자세한 결과는 이전 포스트를 참고하세요.
Problems
이전 포스트에서 제안하였던 soynlp.noun.LRNounExtractor 명사 추출기를 처음 디자인했던 때는 2015년 4월 입니다. 그 동안 여러 데이터에 이 알고리즘을 적용해 보면서 일반화 성능에 한계가 있다는 느낌을 자주 받았습니다. 자주 등장한 명사들은 추출 성능이 좋았지만, infrequent nouns 을 놓치는 경향이 있었습니다. Infrequent noun 이야 bow model 을 만들면 무시되어 사실상 신경쓰지 않았습니다만, 더 중요한 점은 명사가 아닌데 명사로 추출되는 단어들이 있었습니다. 이런 문제를 해결하기 위하여 후처리 과정을 다듬었던 버전이 soynlp.noun.NewsNounExtractor 입니다.
그러나 후처리는 근본적인 해결방법이 아니라는 생각을 하였습니다. 하지만 LRNounExtractor 의 문제점을 유형화하지 못하여 개선 방향을 잘 잡지 못했습니다.
최근에 고마운 pull request 를 받았습니다. Pull request 에서 수정된 코드들이 이전 명사 추출기의 문제점을 명확히 집었을 뿐더러, 유형화하지 못했던 LRNounExtractor 의 다른 문제점을 정리할 수 있도록 도와줬습니다. 이를 바탕으로 오랜만에 version 2 의 명사 추출기를 만들었습니다.
이번 포스트에서는 LRNounExtractor 의 문제점에 대하여 살펴보고 이를 해결하기 위해 개선한 방법들을 이야기합니다.
Problem 1. 어미, 조사에 모두 해당하는 R parts: -은, -는
아래는 이전 버전의 명사 추출기인 LRNounExtractor 가 이용하는 R parts 에 대한 coefficients 입니다. ‘-은, -는’은 대표적인 조사이지만 coefficient 가 음수입니다. ‘먹 + 은’, ‘가 + 는’ 처럼 ‘-은, -는’은 자주 이용되는 어미이기 때문입니다.
은 -0.606532
을 0.504724
의 0.999867
이 0.999185
를 0.999605
는 -0.619916
만 0.951425
다만 -0.953206
세종 말뭉치에서 학습한 R parts 의 coefficients 는 세종 말뭉치의 특징을 반영합니다. 만약 세종 말뭉치의 용언들의 다수가 ‘-은, -는’을 이용하여 활용된다면 이들의 coefficient 는 negative 입니다.
더 큰 문제는 infrequent noun 의 경우 몇 개의 조사만 이용한다는 점입니다. 만약 (L=’A’, R=’’, 1번), (L=’A’, R=’은’, 1번) 등장하였다면 A는 명사가 아니라고 판단됩니다.
어미와 조사가 분명히 다름에도 불구하고 하나의 feature 로 취급했던 것이 근본적인 문제였습니다. 판단하기에 충분한 정보가 없을 때에는 억측을 하지 않는 것이 좋다고 생각합니다. 판단하기 어려운 단어들을 따로 정리하여 사용자에게 보여주는 것 만으로도 분석에 도움이 될 것입니다. 불완전한 정보를 이용하여 잘못된 판단을 내리는 것보다 훨씬 좋습니다.
이러한 문제점을 해결하기 위하여 version 2 에서는 R features 각각에 대한 coefficients 를 활용하지 않습니다. 대신 R features 를 positive, negative, common features 세 종류로 분류합니다.
Positive features 는 조사 혹은 ‘-하는’과 같은 형용사가 포함되어 있습니다. Negative features 는 어근의 오른쪽에 등장하는 어미 집합 입니다. Common features 는 ‘-은, -는’ 처럼 조사와 어미 둘 모두에 해당하는 features 입니다. 이들은 판별 과정에 영향을 주지 않아야 합니다.
Common features 가 아니라면 점수의 크기는 중요하지 않습니다. 각 종류의 features 에 대한 카운팅으로 계산 방법을 단순화할 수 있습니다. 또한 세종말뭉치의 패턴에 의하여 R features 의 coefficients 가 학습되지 않는다는 장점도 있습니다.
여기에 두 가지 features 를 추가하였습니다. Unknown features 는 positive, negative, common 이 아닌 features 입니다. 우리가 아직 모르는 R features 일수도 있습니다. 아직은 이를 prediction 과정에 이용하지는 않습니다. End features 는 L part 가 하나의 어절로 구성된 경우입니다. 명사는 조사와 결합되기도 하지만, 그 자체로 어절을 이루기도 합니다. end feature 는 이 경우를 counting 합니다.
이전의 명사 추출기는 명사의 오른쪽에 등장한 글자들인 (-는, -를, … )을 이용하여 드라마가 명사인지 판단하였습니다. 이 점수가 어느 수준 이상이라면 ‘드라마’는 명사입니다. 그리고 이 때는 (L=’드라마’, R=’’) 인 경우도 명사로 취급할 수 있습니다.
뉴스 데이터에서는 기관명 다음에 조사가 붙지 않는 경우가 많습니다. 대부분의 R parts 가 빈 칸이라 하더라도 다양한 조사들이 몇 번만 등장한다면 우리는 더 확신을 가지고 명사를 추출할 수 있습니다. 또한 (L=’드라마’, R=’’) 를 명사로 고려함으로써, ‘드라마’의 빈도수를 정확히 계산할 수 있습니다.
드라마 + [('', 1285), ('는', 66), ('를', 57), ... ]
Problem 2. ‘감사합니다 + 만’ vs ‘감사합니 + 다만’
Pull request 에서 언급된 상황은 ‘감사함니다만’이란 어절이었습니다. ‘-만’ 은 대표적인 조사입니다. 그렇기 때문에 ‘감사합니다’가 명사로 추출됩니다. 이는 이전 버전의 명사 추출기의 후처리의 규칙에서도 거를 수 없는 경우 였습니다.
제안해주신 방법은 ‘-만, -다만’ 처럼 L parts 의 끝부분의 글자와 R part 의 글자를 합한 글자가 feature 일 경우, 이를 prediction 에 이용하지 않는 것이었습니다. 만약 ‘감사합니다’가 실제로 명사였다면 ‘-만’ 외에도 다양한 조사가 등장할 것입니다.
Pull request 의 전문은 github 에 있습니다. 이를 기반으로 아래와 같은 세분화된 규칙을 만들었습니다.
exist_longer_pos 는 ‘대학생으 + 로’ 와 ‘대학생 + 으로’ 의 경우를 방지하는데 유용합니다. ‘대학생으’가 명사인지 판단할 때 R feature 에 -‘로’가 등장하였다면, ‘-으로’가 positive feature 에 포함되기 때문에 counting 을 하지 않습니다.
대신 ‘가고있다 + 고’ 처럼 ‘-고’에 의하여 ‘가고있다’라는 L part 가 명사로 추출되지 않게 만들기 위하여 더 긴 negative features 가 있을 경우에는 negative features 에 count 를 추가합니다.
def _predict(word, features):
pos, common, neg, unk, end = 0, 0, 0, 0, 0
for r, freq in features:
if r == '':
end += freq
continue
if _exist_longer_pos(word, r): # ignore
continue
if _exist_longer_neg(word, r): # negative -다고
neg += freq
continue
if r in _common_features:
common += freq
elif r in _pos_features:
pos += freq
elif r in _neg_features:
neg += freq
else:
unk += freq
return pos, common, neg, unk, end다섯 종류의 features 의 빈도수를 이용하여 명사 점수를 계산합니다. 1차 적인 명사 점수를 계산하는데는 positive, negative features 의 빈도수만 이용됩니다. 이전처럼 명사 점수의 범위를 \([-1, 1]\) 로 만들기 위하여 기본 점수는 아래처럼 정의합니다. 이 점수가 minimum_noun_score 보다 크다면 명사로 인식합니다.
\[score(l) = \frac{\#pos - \#neg}{\#pos + \#neg}\]명사의 빈도수를 계산할 때에는 end 와 common 이 이용됩니다. end 는 단일 명사가 하나의 어절을 이룬 경우이며, common 은 ‘-은, -는’ 같은 조사의 빈도수입니다. l 이 명사라고 확신할 수 있으니 common features 를 positive features 로 취급합니다.
이전 버전의 LRNounExtractor 에서는 어절의 왼쪽에 등장한 substring count 를 명사 빈도수로 계산하였지만, 이는 정확한 빈도수가 아닙니다. ‘아이유 (100 번)’, ‘아이돌 (100 번)’, ‘아이 + 가 (100 번)’ 등장하였을 경우, ‘아이’라는 명사의 빈도수는 100 이 되어야 합니다. 하지만 이전 버전의 명사 추출기에서는 ‘아이’의 빈도수가 300 으로 계산되었습니다. R features 의 빈도수 기준으로 명사의 빈도수를 계산하면 이러한 문제를 해결할 수 있습니다.
pos, common, neg, unk, end = _predict(word, features)
base = pos + neg
score = 0 if base == 0 else (pos - neg) / base
support = pos + end + common if score >= minimum_noun_score else neg + end + commonProblem 3. R features 가 다양하지 않을 경우 판단을 유보
‘감사합니다’라는 L part 의 오른쪽에는 {‘’, ‘-만’} 처럼 특정한 R part 만 등장합니다. 자주 등장한 L part 임에도 불구하고 한 두 개의 R part 가 등장한다면 명사가 아닐 것이라는 의심을 해야 합니다. ‘감사합니다’가 명사였다면 다양한 조사가 등장할 가능성이 높기 때문입니다.
min_num_of_features 라는 사용자 설정 parameter 를 따로 두어, 이 값을 넘지 않는 R features 를 지닌 단어에 대해서는 prediction 을 하지 않는 것이 더 좋다 판단하였습니다.
이에 이용되는 R features 는 unknown 이 아니며, 더 긴 R features 의 substring 이 아니어야 합니다. 이 조건을 만족하는 R features 의 종류가 min_num_of_features 보다 작으면 exception case 로 넘깁니다.
def _get_nonempty_features(word, features):
return [r for r, _ in features if (
( (r in _pos_features) and (not _exist_longer_pos(word, r)) ) or
( (r in _neg_features) and (not _exist_longer_neg(word, r)) ) )]
def predict(word, minimum_noun_score=0.3):
features = self.lrgraph.get_r(word, -1)
pos, common, neg, unk, end = _predict(word, features)
base = pos + neg
score = 0 if base == 0 else (pos - neg) / base
support = pos + end + common if score >= minimum_noun_score else neg + end + common
features_ = _get_nonempty_features(word, features)
if len(features_) > min_num_of_features:
return score, support
else:
# handling exceptionProblem 4. 짧은 단어에 불리한 R parts distribution
‘떡볶이’ vs ‘떡볶 + 이’ 의 경우에, ‘떡볶이’가 명사로 판단된다면 ‘떡볶’은 명사로 판단할 필요가 없습니다. L parts 에 떡볶이 (100 번), 떡볶 (100 번) 등장하였다면 ‘떡볶-‘은 ‘떡볶이’의 substring 일 가능성이 높습니다. 하지만 떡볶이 (100 번), 떡볶 (300 번) 등장하였다면, 떡볶 (200 번) 은 ‘-이’ 외에도 다른 조사와 함께 등장하였는지 살펴볼 필요가 있습니다.
‘떡볶 (100 번)’, ‘떡볶이 (100 번)’ 인 경우에 ‘떡볶’을 명사 후보에서 제외시키기 위하여 길이가 긴 어절 순서대로 명사를 추출합니다. ‘떡볶이’가 명사로 추출되었다면 L-R graph 에서 ‘떡볶이’로 인하여 만들어진 L-R pair 를 지웁니다. (‘떡볶이’, ‘’, 100 번), (‘떡볶’, ‘이’, 100 번), (‘떡’, ‘볶이’, 100 번)이 L-R graph 에서 지워지기 때문에 ‘떡볶’은 features 가 존재하지 않습니다. 만약 ‘떡볶 (300번)’ 이 었다면 ‘떡볶 (200 번)’ 에 대한 prediction 만 이뤄집니다.
def _batch_prediction_order_by_word_length(
noun_candidates, minimum_noun_score=0.3):
prediction_scores = {}
n = len(noun_candidates)
for i, (word, _) in enumerate(noun_candidates):
# base prediction
score, support = predict(word, minimum_noun_score)
prediction_scores[word] = (score, support)
# if their score is higher than minimum_noun_score,
# remove eojeol pattern from lrgraph
if score >= minimum_noun_score:
for r, count in lrgraph.get_r(word):
if r == '' or (r in _pos_features):
lrgraph.remove_eojeol(word+r, count)
return prediction_scores명사의 후보도 줄였습니다. 이전 버전의 명사 추출기 에서는 모든 L parts 의 substring 에 대하여 prediction 을 수행하였습니다. 그러나 soynlp 의 명사 추출기는 L-R graph 구조를 가정합니다. R parts 에 positive feature 가 한 개 이상 등장하지 않은 L 은 명사일 가능성이 없습니다. 이들에 대해서는 prediction 을 하지 않습니다 .
단일 명사가 언제나 하나의 어절을 이루는 경우에는 명사 추출 후보에서 제외될 수 있습니다. 그러나 이때는 어자피 R features 가 존재하지 않기 때문에 prediction 이 이뤄지지 않습니다. 그러나 이 단어가 복합명사라면 아직 기회는 있습니다 (Problem 5 참고).
아래는 2016-10-20 뉴스에서 앞의 두 글자가 ‘아이’인 152 개의 명사 후보들에 대한 prediction score 의 변화입니다.
아래 표의 두 번째 column 은 명사로 추출된 어절을 L-R graph 에서 지우지 않은 경우이며, 세 번째 column 은 명사로 추출된 경우 Noun + Positive features 를 L-R graph 에서 지운 경우입니다.
‘아이오아이와’, ‘아이오아이에’는 각각 ‘아이오아이와 + 의’, ‘아이오아이에 + 게’에 의하여 선택된 명사 후보입니다. 이들의 오른쪽에는 한 종류의 R feature 만 등장하여 min_num_of_features 에 의한 filtering 에 걸렸습니다. 이들의 명사 점수는 0 점으로 처리됩니다.
‘아이오아이’는 250 번 등장하였으며 명사로 추출됩니다. 이후 L=’아이오아이 + R=[’’, 와의, 에게, 는, …] 은 L-R graph 에서 제거됩니다.
그 효과는 ‘아이오아’에서 나타납니다. 이전에는 아이오아 + [이, 이는] 때문에 명사 점수가 1 점이었습니다만, ‘아이오아이’가 포함된 어절이 L-R graph 에서 제거됨으로써 명사 점수가 0 점으로 바뀌었습니다.
더 극적인 경우는 ‘아이디’ 입니다. ‘-어’는 대표적인 어미이기 때문에 ‘아이디어’ 에 의하여 ‘아이디’의 명사 점수는 -0.526 이며, 등장 빈도수는 231 이었습니다.
하지만 ‘아이디어’가 명사로 추출된 이후 ‘아이디어’가 포함된 모든 어절이 L-R graph 에서 사라짐으로써 ‘아이디’의 명사 점수는 0.903 으로 올랐으며, 등장 빈도수는 100 으로 감소하였습니다. 감소한 131 번에는 ‘아이디어’를 포함한 다른 단어의 빈도수가 포함되어 있습니다.
위와 같은 경우들에 의하여 ‘아이’라는 단어의 명사 점수도 변화하였음을 볼 수 있습니다.
| L part | without removing covered eojeols (noun score, frequency) |
with removing covered eojeols (noun score, frequency) |
|---|---|---|
| 아이디폭스바겐코리 | (0, 0) | (0, 0) |
| 아이오케이컴퍼니 | (0, 1) | (0, 1) |
| 아이러브영주사 | (0, 1) | (0, 1) |
| 아이폰7플러스 | (1.0, 8) | (1.0, 8) |
| 아이카이스트랩 | (1.0, 18) | (1.0, 18) |
| 아이로니컬하게 | (0, 0) | (0, 0) |
| 아이메이크업 | (0, 1) | (0, 1) |
| 아이로니컬하 | (0, 0) | (0, 0) |
| 아이에스동서 | (1.0, 20) | (1.0, 20) |
| 아이들과미래 | (1.0, 3) | (1.0, 3) |
| 아이콘트롤스 | (1.0, 8) | (1.0, 8) |
| 아이온스퀘어 | (1.0, 5) | (1.0, 5) |
| 아이오아이와 | (0, 18) | (0, 18) |
| 아이폰7이라 | (0, 0) | (0, 0) |
| 아이리오보험 | (0, 1) | (0, 1) |
| 아이스하키보 | (0, 0) | (0, 0) |
| 아이오아이에 | (0, 7) | (0, 7) |
| 아이러브프라 | (0, 1) | (0, 1) |
| 아이슬란드에 | (0, 0) | (0, 0) |
| 아이돌그룹에 | (0, 0) | (0, 0) |
| 아이레벨홀에 | (0, 0) | (0, 0) |
| 아이플레이에 | (0, 0) | (0, 0) |
| 아이파크타워 | (0, 1) | (0, 1) |
| 아이피노믹스 | (1.0, 3) | (1.0, 3) |
| 아이엠벤쳐스 | (1.0, 10) | (1.0, 10) |
| 아이러니하게 | (0, 2) | (0, 2) |
| 아이러니하고 | (0, 0) | (0, 0) |
| 아이스크림으 | (0, 0) | (0, 0) |
| 아이비리그 | (1.0, 2) | (1.0, 2) |
| 아이스크림 | (1.0, 87) | (1.0, 87) |
| 아이슬란드 | (1.0, 19) | (1.0, 19) |
| 아이돌그룹 | (1.0, 16) | (1.0, 16) |
| 아이오아이 | (1.0, 250) | (1.0, 250) |
| 아이플레이 | (1.0, 7) | (1.0, 7) |
| 아이레벨홀 | (0, 1) | (0, 1) |
| 아이러니하 | (0, 0) | (0, 0) |
| 아이템이고 | (0, 1) | (0, 1) |
| 아이돌이라 | (0, 0) | (0, 0) |
| 아이들에게 | (0, 51) | (0, 51) |
| 아이에스시 | (0, 1) | (0, 1) |
| 아이디어라 | (0, 1) | (0, 1) |
| 아이디어들 | (1.0, 13) | (1.0, 13) |
| 아이템쿠폰 | (1.0, 2) | (1.0, 2) |
| 아이덴티티 | (1.0, 24) | (1.0, 24) |
| 아이스커피 | (0, 1) | (0, 1) |
| 아이템들이 | (0, 3) | (0, 3) |
| 아이콘이었 | (0, 0) | (0, 0) |
| 아이폰입니 | (0, 0) | (0, 0) |
| 아이폰이었 | (0, 0) | (0, 0) |
| 아이콘입니 | (0, 0) | (0, 0) |
| 아이웨딩측 | (0, 0) | (0, 0) |
| 아이진호텔 | (0, 0) | (0, 0) |
| 아이러니라 | (0, 0) | (0, 0) |
| 아이에스동 | (0.866, 14) | (0, 0) |
| 아이스하키 | (1.0, 3) | (1.0, 3) |
| 아이디어에 | (0, 4) | (0, 4) |
| 아이튠즈에 | (0, 0) | (0, 0) |
| 아이오와에 | (0, 0) | (0, 0) |
| 아이수퍼에 | (0, 0) | (0, 0) |
| 아이쿱생협 | (1.0, 2) | (1.0, 2) |
| 아이스퀘어 | (1.0, 4) | (1.0, 4) |
| 아이돌하기 | (0, 0) | (0, 0) |
| 아이디어로 | (0, 9) | (0, 9) |
| 아이돌로서 | (0, 1) | (0, 1) |
| 아이폰7뿐 | (0, 0) | (0, 0) |
| 아이섀도우 | (1.0, 2) | (1.0, 2) |
| 아이스케어 | (0, 1) | (0, 1) |
| 아이템으로 | (0, 29) | (0, 29) |
| 아이콘으로 | (0, 20) | (0, 20) |
| 아이폰7으 | (0, 0) | (0, 0) |
| 아이쇼핑으 | (0, 0) | (0, 0) |
| 아이였으므 | (0, 2) | (0, 2) |
| 아이라이너 | (0, 2) | (0, 2) |
| 아이들이 | (0, 176) | (0, 176) |
| 아이디어 | (1.0, 329) | (1.0, 329) |
| 아이폰7 | (1.0, 371) | (1.0, 371) |
| 아이언맨 | (1.0, 8) | (1.0, 8) |
| 아이오와 | (1.0, 10) | (1.0, 10) |
| 아이튠즈 | (1.0, 44) | (1.0, 44) |
| 아이수퍼 | (0.666, 2) | (0.666, 2) |
| 아이돌이 | (0, 7) | (0, 7) |
| 아이템으 | (0, 0) | (0, 0) |
| 아이콘으 | (0, 0) | (0, 0) |
| 아이처럼 | (0, 25) | (0, 25) |
| 아이템이 | (-1.0, 11) | (-1.0, 11) |
| 아이파크 | (1.0, 86) | (1.0, 86) |
| 아이리버 | (1.0, 16) | (1.0, 16) |
| 아이러니 | (1.0, 33) | (1.0, 33) |
| 아이씨디 | (1.0, 6) | (1.0, 6) |
| 아이오페 | (0, 1) | (0, 1) |
| 아이언스 | (1.0, 4) | (1.0, 4) |
| 아이템들 | (1.0, 14) | (1.0, 14) |
| 아이에게 | (0, 20) | (0, 20) |
| 아이에이 | (0.714, 5) | (0.714, 5) |
| 아이센스 | (1.0, 7) | (1.0, 7) |
| 아이라인 | (1.0, 4) | (1.0, 4) |
| 아이폰만 | (0, 0) | (0, 0) |
| 아이돌들 | (0, 1) | (0, 1) |
| 아이알라 | (1.0, 5) | (1.0, 5) |
| 아이섀도 | (0.5, 5) | (1.0, 5) |
| 아이피부 | (0, 2) | (0, 2) |
| 아이보리 | (1.0, 16) | (1.0, 16) |
| 아이폰보 | (0, 0) | (0, 0) |
| 아이들보 | (0, 0) | (0, 0) |
| 아이웨딩 | (0.989, 93) | (0.989, 93) |
| 아이엠텍 | (1.0, 4) | (1.0, 4) |
| 아이들에 | (0, 4) | (0, 4) |
| 아이같다 | (0, 1) | (0, 1) |
| 아이들하 | (0, 0) | (0, 0) |
| 아이돌로 | (0, 4) | (0, 4) |
| 아이오아 | (1.0, 143) | (0, 0) |
| 아이플레 | (0, 3) | (0, 0) |
| 아이비아 | (0, 2) | (0, 2) |
| 아이오빈 | (1.0, 2) | (1.0, 2) |
| 아이비케 | (0, 1) | (0, 1) |
| 아이티에 | (0, 2) | (0, 2) |
| 아이콘에 | (0, 0) | (0, 0) |
| 아이돌계 | (0, 8) | (0, 8) |
| 아이들과 | (0, 31) | (0, 31) |
| 아이레스 | (0, 2) | (0, 2) |
| 아이튠스 | (1.0, 5) | (1.0, 5) |
| 아이들만 | (0, 3) | (0, 3) |
| 아이유와 | (0, 5) | (0, 5) |
| 아이실론 | (1.0, 2) | (1.0, 2) |
| 아이패드 | (1.0, 21) | (1.0, 21) |
| 아이리스 | (1.0, 11) | (1.0, 11) |
| 아이맥에 | (0, 0) | (0, 0) |
| 아이템과 | (0, 6) | (0, 6) |
| 아이폰으 | (0, 0) | (0, 0) |
| 아이쇼핑 | (0, 2) | (0, 2) |
| 아이아 | (0, 1) | (0, 1) |
| 아이구 | (0, 0) | (0, 0) |
| 아이들 | (1.0, 570) | (1.0, 570) |
| 아이폰 | (1.0, 358) | (1.0, 358) |
| 아이콘 | (1.0, 84) | (1.0, 84) |
| 아이엠 | (1.0, 40) | (1.0, 40) |
| 아이템 | (1.0, 220) | (1.0, 220) |
| 아이돌 | (1.0, 283) | (1.0, 283) |
| 아이쿱 | (0.777, 7) | (1.0, 7) |
| 아이티 | (1.0, 44) | (1.0, 44) |
| 아이같 | (0, 3) | (0, 3) |
| 아이맥 | (1.0, 8) | (1.0, 8) |
| 아이유 | (1.0, 31) | (1.0, 31) |
| 아이디 | (-0.526, 231) | (0.903, 100) |
| 아이브 | (0, 1) | (0, 1) |
| 아이라 | (0, 0) | (0, 0) |
| 아이더 | (1.0, 8) | (1.0, 8) |
| 아이허 | (0, 0) | (0, 0) |
| 아이언 | (1.0, 8) | (1.0, 8) |
| 아이보 | (0, 14) | (0, 0) |
| 아이였 | (-1.0, 5) | (-1.0, 5) |
| 아이이 | (0, 0) | (0, 0) |
| 아이에 | (0, 6) | (0, 3) |
| 아이치 | (0, 5) | (0, 5) |
| 아이린 | (1.0, 11) | (1.0, 11) |
| 아이다 | (1.0, 17) | (1.0, 17) |
| 아이오 | (0, 9) | (0, 0) |
| 아이섀 | (0, 2) | (0, 0) |
| 아이 | (0.766, 568) | (1.0, 568) |
이처럼 긴 단어부터 명사 유무를 판단한 뒤, 명사가 포함된 어절을 L-R graph 에서 제거함으로써 짧은 명사들이 제대로 추출되지 못하던 문제를 해결할 수 있습니다.
Problem 5. 복합명사
조사나 어미가 어절의 R part 위치에 존재하지 않으면서 어절 내에 여러 개의 명사가 존재한다면 이를 복합명사로 판단할 수 있습니다. 이 복합명사가 여러 조사들과 함께 자주 등장하였다면 그 자체가 명사로 추출될 수도 있지만, 복합명사 하나로 어절이 구성될 경우에는 R features 가 없기 때문에 R features 를 이용한 prediction 을 할 수 없습니다. 하지만 복합 명사를 구성하는 단일 명사들을 인식함으로써 이를 복합명사로 추출할 수 있습니다.
이를 위하여 soynlp.tokenizer 의 Max Score Tokenizer 를 이용하였습니다. prediction 과정에서 minimum_noun_score 이상의 점수를 얻은 명사들의 점수를 noun_scores 로 만듭니다. {‘경찰’, ‘병원’, ‘국립’} 이 모두 명사로 추출되었다면 ‘국립경찰병원’은 Max Score Tokenizer 에 의하여 [‘국립’, ‘경찰’, ‘병원’]으로 나뉘어질 것입니다. Max Score Tokenizer 에 의하여 나뉘어진 모든 단어의 점수가 minimum_noun_score 이상이라면 이를 복합명사로 인식합니다.
from soynlp.tokenizer import MaxScoreTokenizer
_compound_decomposer = MaxScoreTokenizer(scores={'경찰': 1.0, '병원': 1.0, '국립':0.95})
_compound_decomposer.tokenize('국립경찰병원', flatten=False)
# (단어, begin, end, score, length)
# [('국립', 0, 2, 0.95, 2), ('경찰', 2, 4, 1, 2), ('병원', 4, 6, 1, 2)]Package. soynlp
위 과정이 정리된 package 는 soynlp github 에 공개되어 있습니다. 현재의 이름은 LRNounExtractor_v2 입니다. 아직도 일반화 성능의 실험이 끝나지 않았기 때문에 이전의 모든 버전들을 남겨두고 있습니다.
from soynlp.utils import DoublespaceLineCorpus
from soynlp.noun import LRNounExtractor_v2
corpus_path = '2016-10-20-news'
sents = DoublespaceLineCorpus(corpus_path, iter_sent=True)Train, extraction 은 train(), extract() 순서로 함수를 이용하던지 train_extract() 함수를 한 번에 이용하여도 됩니다.
noun_extractor = LRNounExtractor_v2(verbose=True)
#noun_extractor.train(sents)
#nouns = noun_extractor.extract()
nouns = noun_extractor.train_extract(sents)verbose=True 로 설정하면 아래와 같은 명사 추출 과정이 출력됩니다. 추출된 명사의 개수, 그 중 복합 명사의 개수가 출력되며, 이 명사들이 등장한 어절의 빈도수도 출력됩니다.
[Noun Extractor] counting eojeols
[Noun Extractor] complete eojeol counter -> lr graph
[Noun Extractor] has been trained.
[Noun Extractor] batch prediction was completed for 146445 words
[Noun Extractor] checked compounds. discovered 35044 compounds
[Noun Extractor] 86133 nouns (35044 compounds) with min count=1
[Noun Extractor] 71.69 % eojeols are covered
[Noun Extractor] flushing ... done
30.091 건의 뉴스로부터 명사를 추출하는데 약 26 초가 걸렸습니다.
noun_extractor._compounds_components 에는 복합 명사를 구성하는 units 이 기록되어 있습니다. dict[str] = tuple of str 형식입니다.
list(noun_extractor._compounds_components.items())[:10]
# [('잠수함발사탄도미사일', ('잠수함', '발사', '탄도미사일')),
# ('미사일대응능력위원회', ('미사일', '대응', '능력', '위원회')),
# ('글로벌녹색성장연구소', ('글로벌', '녹색성장', '연구소')),
# ('시카고옵션거래소', ('시카고', '옵션', '거래소')),
# ('대한민국특수임무유공', ('대한민국', '특수', '임무', '유공')),
# ('철도산업발전소위원회', ('철도', '산업발전', '소위원회')),
# ('포괄적핵실험금지조약', ('포괄적', '핵실험', '금지', '조약')),
# ('유엔북한인권사무소', ('유엔', '북한인권', '사무소')),
# ('교육문화위원장', ('교육', '문화', '위원장')),
# ('중앙투자심사위원회', ('중앙투자심사', '위원회'))]학습된 명사 추출기를 이용하여 복합명사를 분해하는 함수를 추가하였습니다.
print(noun_extractor.decompose_compound('두바이월드센터시카고옵션거래소'))
# ('두바이', '월드', '센터', '시카고', '옵션', '거래소')하지만 알려지지 않은 명사가 하나라도 있을 경우 분해가 되지 않습니다. 복합명사 유무를 고려하여 어절에서 명사를 잘라내는 부분은 NounExtractor 가 아닌 NounTokenizer 에서 다룰 에정입니다.
print(noun_extractor.decompose_compound('두바이월드센터시카고옵션거래소라라라라'))
# ('두바이월드센터시카고옵션거래소라라라라라',)이 작업을 하며 두 가지 utils 를 만들었습니다. EojeolCounter 는 이름 그대로 어절의 빈도수를 계산합니다. LRGraph 는 앞서 이야기한 L-R graph 입니다. EojeolCounter 에서 LRGraph 로 변환하는 함수도 만들었습니다. 이는 to_lrgraph() 를 이용합니다. L, R 의 최대 길이를 조절 할 수 있습니다.
from soynlp import LRGraph
from soynlp import EojeolCounter
eojeol_counter = EojeolCounter(sents, min_count=1, max_length=15)
lrgraph = eojeol_counter.to_lrgraph(l_max_length=10, r_max_length=9)LRGraph 는 get_r, get_l 함수를 이용하여 L, R features 를 확인할 수 있습니다. 기본 설정은 빈도수 기준 상위 10 개의 features 가져옵니다만, 이는 argument 로 조절할 수 있습니다. -1 과 같은 음수를 입력하면 모든 features 를 가져옵니다.
lrgraph.get_r('드라마', 20) # 빈도수 기준 상위 20 개의 R features
lrgraph.get_l('라고', -1) # -라고 로 끝나는 모든 어절의 L partsLRNounExtractor_v2 는 LRGraph 를 이용하여 분석가가 직접 L-R 구조를 편하게 살펴볼 수 있도록 하였습니다. train 이 끝난 noun_extractor.lrgraph 의 get_r, get_l 을 이용할 수 있습니다.
print(noun_extractor.lrgraph.get_r('두바이월드센터'))
# [('에도', 7)]Conclusion
명사는 미등록단어 문제를 가장 많이 일으키는 단어입니다. 그리고 한국어 텍스트에서 가장 많이 등장하는 단어이기도 합니다. LRNounExtractor_v2 의 성능이 좋다는 가정 하에, 70% 가 넘는 어절이 명사를 포함합니다. 그 뿐 아니라 명사 인식이 잘 되어야 용언 추출이 쉬워집니다. 명사 뿐 아니라 다른 품사 단어의 추출을 위해서도 명사는 잘 추출되어야 합니다.
soynlp 0.0.5+ 이후에 이용 가능하며, 아직 테스트 작업 중입니다. git clone 으로 이용할 수 있으며, 사용코드는 위 포스트와 같습니다.