품사 판별 (Part-of-Speech tagging) 은 string 형식의 문장으로부터 [(단어, 품사), (단어, 품사), … ] 형식으로 문장을 구성하는 단어와 품사를 인식하는 문제입니다. 한 문장은 여러 개의 단어/품사열 (sequence of word and tag) 의 후보가 만들어 질 수 있으며, 품사 판별 과정에서는 가능한 단어/품사열 후보 중 가장 적절한 것을 선택해야 합니다. 이는 길이가 \(n\) 인 input sequence \(x_{1:n}\) 에 대하여 가장 적절한 output sequence \(y_{1:n}\) 을 찾는 문제이기도 합니다. 이를 위하여 sequential labeling 이 이용될 수 있습니다. Sequential labeling 을 이용하는 초기의 품사 판별기는 Hidden Markov Model (HMM) 을 이용하였습니다. 그러나 구조적인 한계 때문에 이후에 Conditional Random Field (CRF) 가 제안된 뒤로 CRF 가 품사 판별 문제의 sequential labeling module 로 이용되었습니다. 최근에는 word embedding 을 features 로 이용하기 위하여 deep neural network 계열의 sequential labeling 방법이 이용되기도 합니다. 품사 판별기의 원리를 이해하기 위해서는 사람이 이해하기 쉬운 features 를 이용하는 CRF 기반 품사 판별기를 알아보는 것이 좋습니다. 이번 포스트에서는 CRF 를 이용하여 한국어 품사 판별기를 학습하고, 주어진 단어/품사열에 대한 적합성, score 를 계산하는 부분을 구현합니다. 단 Viterbi style 의 CRF decoding 과정은 다루지 않습니다.
Conditional Random Field (CRF)
일반적으로 classification 이라 하면, 하나의 입력 벡터 \(x\) 에 대하여 하나의 label 값 \(y\) 를 return 하는 과정입니다. 그런데 입력되는 \(x\) 가 벡터가 아닌 sequence 일 경우가 있습니다. \(x\) 를 길이가 \(n\) 인 sequence, \(x = [x_1, x_2, \ldots, x_n]\) 라 할 때, 같은 길이의 \(y = [y_1, y_2, \ldots, y_n]\) 을 출력해야 하는 경우가 있습니다. Labeling 은 출력 가능한 label 중에서 적절한 것을 선택하는 것이기 때문에 classification 입니다. 데이터의 형식이 벡터가 아닌 sequence 이기 때문에 sequential data 에 대한 classification 이라는 의미로 sequential labeling 이라 부릅니다.
띄어쓰기 문제나 품사 판별이 대표적인 sequential labeling 입니다. 품사 판별은 주어진 단어열 \(x\) 에 대하여 품사열 \(y\) 를 출력합니다.
- \(x = [이것, 은, 예문, 이다]\) .
- \(y = [명사, 조사, 명사, 조사]\) .
띄어쓰기는 길이가 \(n\) 인 글자열에 대하여 [띈다, 안띈다] 중 하나로 이뤄진 Boolean sequence \(y\) 를 출력합니다.
- \(x = 이것은예문입니다\) .
- \(y = [0, 0, 1, 0, 1, 0, 0, 1]\) .
Conditional Random Field (CRF) 는 sequential labeling 을 위하여 potential functions 을 이용하는 softmax regression 입니다. Deep learning 계열 모델인 Recurrent Neural Network (RNN) 이 sequential labeling 에 이용되기 전에, 다른 많은 모델보다 좋은 성능을 보인다고 알려진 모델입니다.
Sequential labeling 은 길이가 \(n\) 인 sequence 형태의 입력값 \(x = [x_1, x_2, \ldots, x_n]\) 에 대하여 길이가 \(n\) 인 적절한 label sequence \(y = [y_1, y_2, \ldots, y_n]\) 을 출력합니다. 이는 \(argmax_y P(y_{1:n} \vert x_{1:n})\) 로 ㅍ현할 수 있습니다.
Softmax regression 은 벡터 \(x\) 에 대하여 label \(y\) 를 출력하는 함수입니다. 하지만 입력되는 sequence data 가 단어열과 같이 벡터가 아닐 경우에는 이를 벡터로 변환해야 합니다. Potential function 은 categorical value 를 포함하여 sequence 로 입력된 다양한 형태의 값을 벡터로 변환합니다.
Potential function 은 Boolean 필터처럼 작동합니다. 아래는 두 어절로 이뤄진 문장, “예문 입니다” 입니다. 앞의 한글자와 그 글자의 띄어쓰기, 그리고 현재 글자를 이용하여 현재 시점 \(i\) 를 벡터로 표현할 수 있습니다.
- \(x = '예문 입니다'\) .
- \(F_1 = 1\) if \(x_{i-1:i} =\) ‘예문’ else \(0\)
- \(F_2 = 1\) if \(x_{i-1:i} =\) ‘예문’ & \(y[i-1] = 0\) else \(0\)
- \(F_3 = 1\) if \(x_{i-1:i} =\) ‘문입’ else \(0\)
- \[\cdots\]
앞글자부터 현재 글자, 그리고 앞글자의 띄어쓰기 정보를 이용한다는 것을 템플릿으로 표현할 수 있습니다. 현재 시점을 \(i\) 가 아닌 \(0\) 이라 표현하였습니다.
- templates
- \(x_{-1:0}\) .
- \(x_{-1:0}\) & \(y_{-1}\) .
그림은 위 예시 템플릿을 이용하여 ‘예문 입니다’에 potential functions 을 적용한 결과입니다. 마치 5 개의 문서에 대한 term frequency vector 처럼 보입니다.
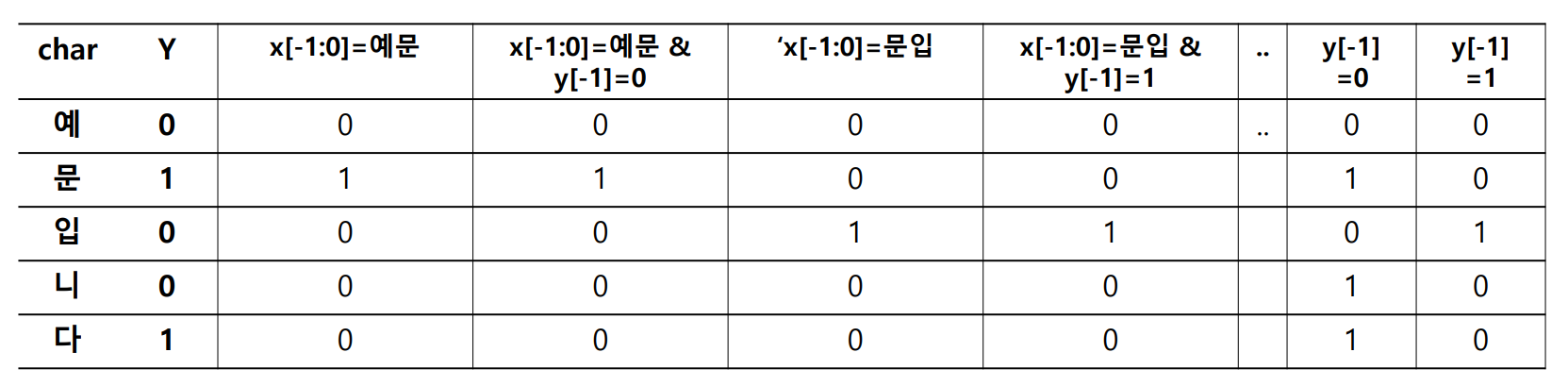
품사 판별을 위한 sequential labeling 이라면 input sequence 는 단어열이며, output sequence 는 각 단어에 해당하는 품사열입니다. 이를 위해서는 아래와 같은 potential funtion 을 이용할 수 있습니다. 이 potential functions 의 의미는, 현재 단어 \(x_i\) 의 앞 단어인 \(x_{i-1}\) 이 ‘이것’일 경우라는 의미입니다. 앞/뒤의 단어 혹은 앞 단어의 품사 정보가 특정한 경우 (\(F_j\)) 인지 True, False 로 확인하는 함수들입니다.
- \(x = [이것, 은, 예문, 이다]\) .
- \(F_1 = 1\) if \(x_{i-1} =\) ‘이것’ & \(x_i =\) ‘은’ else \(0\)
- \(F_2 = 1\) if \(x_{i-1} =\) ‘이것’ & \(x_i =\) ‘예문’ else \(0\)
- \(F_3 = 1\) if \(x_{i-1} =\) ‘은’ & \(x_i =\) ‘예문’ else \(0\)
- \(x_{vec} = [(0, 0, 0), (1, 0, 0), (0, 0, 1), (0, 0, 0)]\) .
이처럼 potential functions 은 임의의 형태의 데이터라 하더라도 Boolean filter 를 거쳐 high dimensional sparse Boolean vector 로 표현합니다. Conditional Random Field 는 특정 상황일 때 특정 label 의 확률을 학습하는 모델입니다.
CRF 와 비슷한 모델 중 Maximum Entropy Markov Model (MEMM) 이 있습니다. MEMM 은 \(P(y_{1:n} \vert x_{1:n})\) 를 다음처럼 계산합니다.
\[P(y \vert x) = \prod_{i=1}^{n} \frac{exp(\sum_{j=1}^{m} \lambda_j f_j (x, i, y_i, y_{i-1}))}{ \sum_{y^{`}} exp(\sum_{j^{`}=1}^{m} \lambda_j f_j (x, i, y_i^{'}, y_{i-1}^{'})) }\]\(f_j\) 는 potential function 입니다. Potential functions 에 의하여 \(m\) 차원의 sparse vector 로 표현된 \(x_i\)와 coefficient vector \(\lambda\) 의 내적에 exponential 이 취해집니다. 다른 labels 후보 \(y^{'}\) 의 값들의 합으로 나뉘어집니다. \(n\) 번의 softmax regression classification 을 순차적으로 하는 형태입니다. 하지만 MEMM 은 label bias 문제가 발생합니다. 이를 해결하기 위하여 CRF 가 제안되었습니다.
CRF 의 \(P(y_{1:n} \vert x_{1:n})\) 은 다음처럼 기술됩니다.
\[P(y \vert x) = \frac{exp(\sum_{j=1}^{m} \sum_{i=1}^{n} \lambda_j f_j (x, i, y_i, y_{i-1}))}{ \sum_{y^{'}} exp(\sum_{j^{'}=1}^{m} \sum_{i=1}^{n} \lambda_j f_j (x, i, y_i^{'}, y_{i-1}^{'})) }\]\(n\) 번의 logistic classification 이 아닌, vector sequences, 즉 matrix 에 대한 한 번의 logistic classification 입니다. 자세한 Conditional Random Field 의 설명은 이전 블로그 를, Conditional Random Field 를 이용하여 만든 띄어쓰기 교정기는 이 블로그를 참고하세요.
Why Conditional Random FIeld (CRF) is better than Hidden Markov Model (HMM) in sequential labeling?
Consider context (Solving unguaranteed independency problem of HMM)
단어열이 주어졌을 때, 한 단어 \(x_i\) 의 품사를 추정할 때에는 그 주변 단어들, \(x_{i-k:i}\) 나 \(x_{i:i+l}\) 가 문맥적인 힌트가 됩니다. 그런데 앞선 HMM 의 포스트에서 언급하였듯이 HMM 은 unguaranteed independency problem 이란 문제가 있습니다. HMM 에서 \(x_i\) 는 \(y_i\) 만 그 상관성을 emission probability 로 학습할 수 있습니다. \(x_i\) 이전에 \(x_{i-1}\) 에 어떤 단어가 등장하였는지는 상관하지 않습니다. HMM 은 문맥을 “직접적으로” 고려하는 기능이 없습니다. 단지 state 간의 transition probability 인 \(P(y_i \vert y_{i-1})\) 에 의하여 간접적으로 단어 간 문맥이 반영되길 바랄 뿐입니다. HMM 은 품사 판별처럼 앞, 뒤의 observation 을 함께 고려해야 하는 상황에서의 sequential labeling 에는 적합하지 않은 방법입니다.
그러나 CRF 는 앞, 뒤의 단어로 이뤄진 문맥을 직접적으로 이용합니다. Potential function 을 만들 때, \(x_{i-1:i+1}\) 을 이용한다면, trigram 의 문맥에서 가운데 단어의 품사를 추정한다는 의미입니다. 예를 들어 아래와 같이 ‘이’ 앞에, \(x_{i-1}\) = ‘남’, 뒤에 \(x_{i+1}\) = ‘빼줬어’가 등장하였을 때, 가운데 단어 $$x_i$ = ‘이’는 Josa 일 가능성이 높다는 의미입니다.
남, 이, 빼줬어 -> [Noun, Josa, Verb]
만약 \(x_{i-1, i+1}\) 을 feature 로 이용한다면, 앞/뒤에 \(x_{i-1}\) = ‘남’, \(x_{i+1}\) = ‘빼줬어’이 등장한다면 그 가운데 단어는 무엇이 되던지 (\(x_i\) 를 feature 로 이용하지 않으므로) 가운데 단어의 품사를 추정한다는 의미입니다.
CRF 는 이처럼 앞/뒤에 등장하는 단어를 직접적으로 확인함으로써 특정 문맥에서의 \(x_i\) 의 품사를 추정할 수 있습니다.
CRF can learn context
HMM 은 emission probability, \(P(x_i \vert y_i), P(word \vert tag)\) 에 의하여 단어가 등장할 가능성을 계산합니다. 그리고 이는 학습 말뭉치에 어떤 품사 \(y\) 에서 단어 \(x\) 가 등장했던 확률입니다. 즉 학습 말뭉치에 존재하지 않은 단어에 대해서는 emission probability 가 0 입니다. 그렇기 때문에 학습 말뭉치에 존재하지 않은 단어에 대해 품사를 부여하기가 어렵습니다.
물론 HMM 기반 방법은 특정 단어에 대하여 임의의 emission probability 를 부여함으로써 사용자 사전을 손쉽게 추가할 수도 있었습니다.
하지만 tagger 가 단어를 직접 외우지 않고, 그 단어의 문맥, 앞/뒤의 단어를 외운다면 가운데에 등장하는 임의의 단어에 대하여 품사를 추정할 수 있습니다. 앞서 살펴본 \(x_{i-1, i+1}\) 은 이런 기능을 합니다. Infrequent 한 여러 개의 단어를 외우기 보단, frequent words 로 이뤄진 infrequent word 의 문맥을 외움으로써 다양한 infrequent word 에 대한 품사를 추정할 수 있습니다.
Appending user dictionary
CRF based tagger 에도 사용자 사전을 입력하는 것이 어렵지 않습니다. 사용자 사전의 단어 \(w\) 를 품사 \(t\) 로 입력하려면 \(x_i=w, y_i=t\) 라는 state feature 를 만들고, 이 state feature 의 regression coefficient 를 해당 품사의 가장 큰 값으로 정의해주면 됩니다.
State feature 는 potential function 에 의하여 만들어진 feature \(F\) 에 대한 품사 \(t\) 의 regression coefficient 입니다. Implementation code 를 살펴보면 이해가 더 빠를 것입니다.
Implementing CRF based Part-of-Speech Tagger
학습 말뭉치를 이용하여 품사 판별이나 형태소 분석용 tagger 를 학습하기도 합니다. 학습 말뭉치는 다음과 같은 데이터로 구성되어 있습니다.
아래는 세종 말뭉치의 예시입니다. 세종 말뭉치는 한국어 형태소 분석을 위하여 국립국어원에서 배포한 말뭉치입니다. 한 문장이 (morpheme, tag) 형식으로 기술되어 있습니다. 아래는 네 개의 문장의 스냅샷입니다.
[['뭐', 'NP'], ['타', 'VV'], ['고', 'EC'], ['가', 'VV'], ['ㅏ', 'EF']]
[['지하철', 'NNG']]
[['기차', 'NNG']]
[['아침', 'NNG'], ['에', 'JKB'], ['몇', 'MM'], ['시', 'NNB'], ['에', 'JKB'], ['타', 'VV'], ['고', 'EC'], ['가', 'VV'], ['는데', 'EF']]
우리는 linear-chained CRF tagger 를 만들어봅니다. 이는 앞 시점의 tag 인 \(y_{i-1}\) 의 정보를 이용하는 CRF 입니다.
우리는 corpus 가 nested list 구조라 가정합니다. 각 문장 sent 는 [(word, tag), (word, tag), … ] 형식입니다. 이는 앞선 HMM based tagger에서 이용한 학습 말뭉치의 형식과 동일합니다.
Potential function
(단어, 품사)열로 구성된 문장의 앞/뒤에 ‘BOS’ 와 ‘EOS’를 추가합니다. 이 값은 자주 이용할 것이니 bos, eos 라는 변수로 따로 저장해둡니다.
Conditional Random Field 기반 알고리즘들은 potential function 을 자유롭게 디자인할 수 있습니다. 확장성을 위하여 potential function 의 abstract class 를 하나 만든 뒤, 모든 potential function 은 이를 상속하도록 합니다. AbstractFeatureTramsformer 라는 abstract class 를 만들었습니다. 그리고 공통적으로 이용되는 sentence_to_xy 라는 함수와 potential function 을 구현합니다.
FeatureTransformer 를 함수처럼 이용할 수 있도록 call 함수를 정의합니다. list of (word, pos) 형식의 sentence 가 입력되면 이를 feature 로 변환된 문장, encoded_sentence 와 품사열 tags 를 return 하는 sentence_to_xy 함수로 넘겨줍니다.
구현의 편의를 위하여 sentence 의 앞에 (bos, bos), 문장 뒤에 (eos, eos) 라는 (단어, 품사)를 입력합니다. 그리고 zip(*) 을 이용하여 단어열과 품사열을 분리합니다. 이를 각각 words_, tags_ 라 명합니다.
potential_function 은 단어열 words_ 와 품사열 tags_ 를 입력받아, 이로부터 품사를 만듭니다. words_, tags_ 의 맨 앞과 뒤에는 bos, eos 가 존재하므로, 0 이 아닌 1 번째 단어열부터 n 개의 시점에 대하여 to_feature 함수를 이용하여 features 를 만듭니다.
이제 모든 FeatureTransformer 는 abstact class 를 상속받고 to_feature 라는 함수만 구현하면 됩니다.
bos = 'BOS'
eos = 'EOS'
class AbstractFeatureTransformer:
def __call__(self, sentence):
return self.sentence_to_xy(sentence)
def sentence_to_xy(self, sentence):
"""Feature transformer
:param list_of_tuple pos: a sentence [(word, tag), (word, tag), ...]
"""
words, tags = zip(*sentence)
words_ = tuple((bos, *words, eos))
tags_ = tuple((bos, *tags, eos))
encoded_sentence = self.potential_function(words_, tags_)
return encoded_sentence, tags
def potential_function(self, words_, tags_):
n = len(tags_) - 2 # except bos & eos
sentence_ = [self.to_feature(words_, tags_, i) for i in range(1, n+1)]
return sentence_
def to_feature(self, sentence):
raise NotImplementedBaseFeatureTransformer 는 다음의 features 를 이용하는 potential function 입니다.
| format | note |
|---|---|
| x[0] | 현재 단어. crf based tagger 가 단어를 외울 수 있도록 합니다 |
| x[0] & y[-1] | 현재 단어와 앞 단어의 품사. 앞 단어의 품사를 문맥으로 이용하도록 합니다. Noun + 이 일 경우, ‘이’가 Josa 일 가능성을 높여줍니다. |
| x[-1:0] | 앞 단어와 현재 단어입니다. 앞 단어를 문맥으로 이용합니다. |
| x[-1:0] & y[-1] | 앞 단어 뿐 아니라 그 단어의 품사까지 문맥으로 이용합니다. |
| x[-1,1] | 앞/뒤에 등장한 단어입니다. |
| x[-1,1] & y[-1] | 앞/뒤에 등장한 단어와 앞 단어의 품사 입니다. |
class BaseFeatureTransformer(AbstractFeatureTransformer):
def __init__(self):
super().__init__()
def to_feature(self, words_, tags_, i):
features = [
'x[0]=%s' % words_[i],
'x[0]=%s, y[-1]=%s' % (words_[i], tags_[i-1]),
'x[-1:0]=%s-%s' % (words_[i-1], words_[i]),
'x[-1:0]=%s-%s, y[-1]=%s' % (words_[i-1], words_[i], tags_[i-1]),
'x[-1,1]=%s-%s' % (words_[i-1], words_[i+1]),
'x[-1,1]=%s-%s, y[-1]=%s' % (words_[i-1], words_[i+1], tags_[i-1])
]
return features만약 HMM 이 이용하는 정보들만을 이용하는 CRF 를 만들고 싶다면 아래처럼 현재 단어 x[0] 만 이용하는 to_feature 함수를 만듭니다. 이제 모델이 학습하는 정보는 오로직 \(x_i\) 와 \(y_i\) 의 관계 뿐입니다.
class HMMStyleFeatureTransformer(AbstractFeatureTransformer):
def __init__(self):
super().__init__()
def to_feature(self, words_, tags_, i):
features = [
'x[0]=%s' % words_[i],
]
return features우리는 crfsuite 를 Python 에서 이용할 수 있도록 wrapping 을 한 python-crfsuite 라이브러리를 이용할 것입니다. 이 라이브러리는 \(y_{i-1:i}\) 의 transition probability 를 따로 학습합니다. 즉 y[-1] feature 를 기본으로 학습합니다. HMM 은 transition probability 와 emission probability 를 학습해야 합니다. 위의 HMMStyleFeatureTransformer 를 이용하여 만드는 feature 는 emission probability 에 해당하는 부분입니다.
Trainer
학습을 위한 Trainer 를 class 로 만듭니다. 만약 Trainer 를 만들 때 init 함수에 학습 데이터가 입력되면 train 함수를 이용하여 학습을 합니다. 그 외의 min_count, l2_cost, l1_cost, max_iter, verbose 는 python-crfsuite 의 parameters 입니다. sentence_to_xy 는 우리가 앞서 만들어 둔 FeatureTransformer 입니다.
class Trainer:
def __init__(self, corpus=None, sentence_to_xy=None, min_count=3,
l2_cost=1.0, l1_cost=1.0, max_iter=300, verbose=True):
self.sentence_to_xy = sentence_to_xy
self.min_count = min_count
self.l2_cost = l2_cost
self.l1_cost = l1_cost
self.max_iter = max_iter
self.verbose = verbose
if corpus is not None:
self.train(corpus)CRF 는 potential function 을 만들기에 따라서 수천만개의 features 가 만들어지기도 합니다. 즉 수천만 차원의 softmax regression 을 학습하는 경우들도 생기는데, 많은 종류의 features 의 빈도수는 매우 작습니다. 일반화 성능을 높이면서 모델을 가볍게 만들기 위하여 min frequency cutting 만 해줘도 모델이 가벼워집니다.
python-crfsuite 에는 min frequency cutting 을 하는 기능이 있습니다. 하지만, 메모리에 모든 features 를 올려둔 뒤에 frequency 를 계산합니다. 애초에 만들어둘 필요가 없는 features 를 한 번은 만들게 됩니다. 그리고 이 과정에서 out-of-memory issue 를 마주하기도 합니다.
이런 일을 방지하려면 python-crfsuite 를 이용하기 전에 min frequency cutting 을 하는 것이 좋습니다. 이를 위하여 scan_features 함수를 만듭니다. potential function 을 이용하여 features 를 만든 뒤, 미리 min frequency cutting 을 수행하여 모델이 이용할 features 만 counter 에 담아 return 합니다.
class Trainer:
...
def scan_features(self, sentences, sentence_to_xy, min_count=2):
def trim(counter, min_count):
counter = {
feature:count for feature, count in counter.items()
# memorize all words no matter how the word occured.
if (count >= min_count) or (feature[:4] == 'x[0]' and not ', ' in feature)
}
return counter
counter = {}
for i, sentence in enumerate(sentences):
# transform sentence to features
sentence_, _ = sentence_to_xy(sentence)
# count
for features in sentence_:
for feature in features:
counter[feature] = counter.get(feature, 0) + 1
# remove infrequent features
counter = trim(counter, min_count)
return countertrain 함수는 sentences 가 입력되면 먼저 scan_features() 함수를 이용하여 모델이 이용할 features 를 입력 받습니다. 이후 정보를 보기 편한 형태로 기록하기 위하여 각 features 의 idx 와 count 를 Feature 라는 namedtuple 로 만들어둡니다. 이 정보는 self._features 에 넣어둡니다.
각 idx 가 어떤 feature 인지 inverse index 인 idx2feature 를 만듭니다. 이 값은 Feature.idx 기준으로 정렬하여 feature 를 list 에 넣어둡니다.
from collections import namedtuple
Feature = namedtuple('Feature', 'idx count')
class Trainer:
...
def train(self, sentences):
features = self.scan_features(
sentences, self.sentence_to_xy,
self.min_count, self.scan_batch_size)
# feature encoder
self._features = {
# wrapping feature idx and its count
feature:Feature(idx, count) for idx, (feature, count) in
# sort features by their count in decreasing order
enumerate(sorted(features.items(), key=lambda x:-x[1]
))
}
# feature id decoder
self._idx2feature = [
feature for feature in sorted(
self._features, key=lambda x:self._features[x].idx)
]
self._train_pycrfsuite(sentences)
self._parse_coefficients()모델이 이용할 features 만 선택한 다음 python-crfsuite 를 이용하여 CRF model 을 학습합니다. python-crfsuite 의 package name 은 pycrfsuite 입니다.
python-crfsuite 는 Trainer 를 만든 뒤 학습 데이터를 (x, y) 기준으로 Trainer.append() 함수에 넣어줘야 합니다.
python-crfsuite 는 L1, L2 regularization 을 제공합니다. 만약 l1_cost 를 0 으로 정하면 L2 regularization 만 됩니다. 소수의 features 만을 이용하여 classification 을 잘하고 싶은 것이 아니기 때문에, L2 regularization 만 이용합니다 (l1_cost 를 0 으로 설정합니다).
python-crfsuite 는 c++ 의 crfsuite 를 script 로 실행합니다. 그리고 그 결과를 Trainer.train() 함수에 입력되는 ‘temporal_model’ 파일에 적어둡니다. 학습된 모델을 이용하려면 이 파일로부터 trained model 을 읽어야 합니다.
import pycrfsuite
class Trainer:
...
def _train_pycrfsuite(self, sentences):
trainer = pycrfsuite.Trainer(verbose=self.verbose)
for i, sentence in enumerate(sentences):
# transform sentence to features
x, y = self.sentence_to_xy(sentence)
# use only conformed feature
x = [[xij for xij in xi if xij in self._features] for xi in x]
trainer.append(x, y)
# set pycrfsuite parameters
params = {
'feature.minfreq':max(0,self.min_count),
'max_iterations':max(1, self.max_iter),
'c1':max(0, self.l1_cost),
'c2':max(0, self.l2_cost)
}
# do train
trainer.set_params(params)
trainer.train('temporal_model')학습된 모델을 읽어들여 coefficient 인 \(\lambda\) 를 읽어들입니다. pycrfsuite.Tagger() 를 만든 뒤, 앞서 학습한 모델을 open 합니다. Tagger.info() 를 하면 모델의 parameters 를 얻을 수 있습니다.
state_features 는 (features, class) 간의 regression coefficient, \(\lambda\) 입니다. 아래와 같은 형식의 dict 입니다. 예를 들어 (x[0]=’뭐’, ‘Noun’): 7.960767 은 현재 시점의 단어 \(x_i\), ‘뭐’가 명사일 score 가 7.960767 이라는 의미이며, ‘x[0]=뭐, y[-1]=BOS’ 는, 문장의 첫 글자 ‘뭐’가 감탄사일 score 가 2.300112 라는 의미입니다.
{
('x[0]=뭐', 'Noun'): 7.960767
('x[0]=뭐', 'Exclamation'): 13.623959
('x[0]=뭐, y[-1]=BOS', 'Noun'): 2.345766
('x[0]=뭐, y[-1]=BOS', 'Exclamation'): 2.300112
('x[-1:0]=BOS-뭐', 'Noun'): 2.34576
...
}
transitions 는 transition score 입니다. 아래와 같은 형식의 dict 입니다. \(y_{i-1}\) = ‘Noun’ 일 때 \(y_i\) = ‘Noun’ 일 score 가 9.027282 라는 의미입니다. 특히 (‘Noun’, ‘Eomi’) 처럼 명사 다음에 어미가 등장할 가능성은 거의 없기 때문에 negative score 인 -1.583352 이 학습됩니다. 즉 \(y_{i-1}\) = ‘Noun’ 이면 \(y_i\) 는 ‘Eomi’ 가 될 가능성이 줄어든다는 의미입니다.
{
('Noun', 'Noun'): 9.027282,
('Noun', 'Verb'): 6.565445,
('Noun', 'Eomi'): -1.583352,
('Noun', 'Josa'): 7.388192,
...
}
이 값을 class attribute 로 저장해둡니다.
class Trainer:
...
def _parse_coefficients(self):
# load pycrfsuite trained model
tagger = pycrfsuite.Tagger()
tagger.open('temporal_model')
# state feature coeffitient
debugger = tagger.info()
self.state_features = debugger.state_features
# transition coefficient
self.transitions = debugger.transitionsTrainer 의 학습 결과를 JSON 으로 저장합니다. JSON 은 key 를 str 로 받아야 합니다. 하지만 state_feature 나 transition 은 tuple of str 입니다. 이를 str 로 변환하기 위하여 ‘ -> ‘.join() 을 실행합니다. 이 함수를 통하여 JSON 에 저장되는 state_features_json 는 다음과 같이 변환됩니다. 이후 load 할 때 ‘ -> ‘ 기준으로 split 하여 tuple 로 변환하면 됩니다.
{
'x[0]=뭐 -> Noun': 7.960767,
'x[0]=뭐 -> Exclamation': 13.623959
'x[0]=뭐, y[-1]=BOS -> Noun': 2.345766
'x[0]=뭐, y[-1]=BOS -> Exclamation': 2.300112
'x[-1:0]=BOS-뭐 -> Noun': 2.34576
...
}
transition 에 대해서도 동일한 string concatenation 을 수행합니다.
JSON 으로 저장할 때에는 한글값이 있기 때문에 ensure_ascii=False 로 설정합니다. 또한 이후 파일을 직접 읽을 때 해석이 편하도록 indent=2 로 설정합니다. indent > 0 으로 설정하면 nested 구조에 맞춰 들여쓰기가 indent 값만큼 됩니다.
import json
class Trainer:
...
def _save_as_json(self, json_path):
# concatenate key that formed as tuple of str
state_features_json = {
' -> '.join(state_feature):coef
for state_feature, coef in self.state_features.items()
}
# concatenate key that formed as tuple of str
transitions_json = {
' -> '.join(transition):coef
for transition, coef in self.transitions.items()
}
# re-group parameters
params = {
'state_features': state_features_json,
'transitions': transitions_json,
'idx2feature': self._idx2feature,
'features': self._features
}
# save
with open(json_path, 'w', encoding='utf-8') as f:
json.dump(params, f, ensure_ascii=False, indent=2)Sequential labeling 을 위한 CRF model 의 학습이 모두 끝났습니다.
Tagging using CRF
학습한 CRF 모델을 이용하여 word sequence 에 대한 score 를 계산해봅니다. 가능한 모든 후보들에 대한 score 의 합으로 이 값을 나눈다면, 각 후보에 대한 확률 형식이 됩니다. CRF 에서 \(P(y \vert x)\) 가 가장 큰 \(y\) 를 찾는 것은 \(exp(\sum \lambda_{ij} F(x, y_i, y_{i-1}, i)\) 가 가장 큰 \(y\) 를 찾는 것과 같습니다.
사용 가능한 형태소 분석기나 품사 판별기를 만들려면 문장에서 단어열을 만드는 look-up 부분을 구현해야 합니다. 또한 가능한 문장 후보 (단어, 품사)열을 모두 열거한 다음에 각 후보의 확률을 계산하지도 않습니다. 문장이 조금만 길어져도 (단어, 품사) 열의 후보 개수는 기하급수적으로 늘어나며, 중복된 계산이 많아지기 때문입니다. 이때는 Viterbi style 의 decode 함수를 구현해야 합니다. 지금은 CRF tagger 의 작동 원리를 이해하는 것이 목적이므로, 주어진 단어열의 score 를 계산하는 score() 함수를 구현합니다.
JSON 형식으로 저장한 CRF model 의 coefficients 를 읽습니다. 앞서 저장한 것과 반대로 ‘ -> ‘ 을 이용하여 state_features 와 transitions 의 key 를 split() 합니다.
class TrainedCRFTagger:
def __init__(self, model_path=None, coefficients=None,
feature_transformer=None, verbose=False):
self.feature_transformer = feature_transformer
self.verbose = verbose
if model_path:
self._load_from_json(model_path)
def _load_from_json(self, json_path, marker = ' -> '):
with open(json_path, encoding='utf-8') as f:
model = json.load(f)
# parse transition
self._transitions = {
tuple(trans.split(marker)): coef
for trans, coef in model['transitions'].items()
}
# parse state features
self._state_features = {
tuple(feature.split(marker)): coef
for feature, coef in model['state_features'].items()
}score 함수는 (단어, 품사) 열로 구성된 문장에 대한 score 를 계산하는 함수입니다. 여러 후보 중 이 score 가 가장 높은 (단어, 품사) 열이 정답 문장으로 선정됩니다.
이 함수는 potential function 에 의하여 만들어진 (activated 된) features 의 coefficient 를 누적합니다. Activated 되지 않은 features 라면 그 값이 0 이기 때문에 coefficient 와의 곱도 0 입니다. 즉, activated 된 features 에 대해서만 regression coefficient 를 더해주면 됩니다.
먼저 학습에 이용하였던 FeatureTransformer 를 이용하여 (단어, 품사) 열을 list of features 로 만들어줍니다.
State transitions 의 score 를 더하기 위해서 zip(tags, tags[1:]) 을 이용하여 연속된 두 개의 state, s0 와 s1 을 yield 합니다. self.transitions 에서 (s0, s1) 에 해당하는 coefficient 를 가지고와 누적하여 더해줍니다.
State features 는 아래와 같은 형식의 features 입니다. x[0]=’뭐’ 이고, 문장의 맨 첫 단어일 경우, ‘Noun’ 일 점수 2.345766 이 ‘Exclamation’ 일 점수 2.300112 보다 높으므로, 이 정보만을 이용하면 ‘뭐’ 라는 문장의 첫 단어 ‘뭐’의 품사는 ‘Noun’ 입니다.
('x[0]=뭐, y[-1]=BOS', 'Noun'): 2.345766
('x[0]=뭐, y[-1]=BOS', 'Exclamation'): 2.300112
이처럼 주어진 (단어, 품사) 열의 점수를 계산하여 return 합니다.
class TrainedCRFTagger:
...
def score(self, sentence):
# feature transform
sentence_, tags = self.feature_transformer(sentence)
score = 0
# transition weight
for s0, s1 in zip(tags, tags[1:]):
score += self.transitions.get((s0, s1), 0)
# state feature weight
for features, tag in zip(sentence_, tags):
for feature in features:
coef = self.state_features.get((feature, tag), 0)
score += coef
return score아직 str 형식의 문장이 주어졌을 때, (단어, 품사) 열로 만드는 부분은 구현하지 않았습니다. 이는 이후에 다른 포스트에서 다룹니다. 우리는 후보에 대한 evaluation (scoring) 과정만 구현하였습니다.
Evaluator (scoring) testing
구현한 CRF tagger 를 이용하여 세종 말뭉치를 학습합니다. 그리고 이를 이용하여 ‘뭐 타고가’ 라는 예문의 네 가지 (단어, 품사)열 후보에 대한 확률값을 계산합니다.
candidates = [
[('뭐', 'Noun'), ('타', 'Verb'), ('고', 'Eomi'), ('가', 'Noun')],
[('뭐', 'Noun'), ('타', 'Verb'), ('고', 'Noun'), ('가', 'Noun')],
[('뭐', 'Noun'), ('타', 'Verb'), ('고', 'Eomi'), ('가', 'Verb'), ('ㅏ', 'Eomi')],
[('뭐', 'Noun'), ('타', 'Verb'), ('고', 'Noun'), ('가', 'Verb'), ('ㅏ', 'Eomi')]
]
for sent in candidates:
print('\n{}'.format(sent))
print(trained_crf.score(sent))그 결과 정답인 [(‘뭐’, ‘Noun’), (‘타’, ‘Verb’), (‘고’, ‘Eomi’), (‘가’, ‘Verb’), (‘ㅏ’, ‘Eomi’)] 가 가장 큰 log prob. 값을 지님을 확인할 수 있습니다. Length normalization 을 하지 않으면 [(‘뭐’, ‘Noun’), (‘타’, ‘Verb’), (‘고’, ‘Eomi’), (‘가’, ‘Noun’)] 가 가장 큰 log score 를 지닙니다.
[('뭐', 'Noun'), ('타', 'Verb'), ('고', 'Eomi'), ('가', 'Noun')]
66.006717
[('뭐', 'Noun'), ('타', 'Verb'), ('고', 'Noun'), ('가', 'Noun')]
27.143626000000005
[('뭐', 'Noun'), ('타', 'Verb'), ('고', 'Eomi'), ('가', 'Verb'), ('ㅏ', 'Eomi')]
100.06197299999997
[('뭐', 'Noun'), ('타', 'Verb'), ('고', 'Noun'), ('가', 'Verb'), ('ㅏ', 'Eomi')]
58.769561
위의 예시에서는 HMM 도 CRF 도 정답을 구하였습니다만, 앞서 언급한 것처럼 CRF 는 HMM 보다 문맥을 볼 수 있기 때문에 훨씬 정확한 성능을 보여주며, potential function 을 설계하기에 따라 어느 정도 미등록 단어의 품사도 추정할 수 있습니다.
위 구현체들은 링크의 github 에 올려두었습니다. 이 곳에는 str 형식의 문장에서 단어 후보를 만드는 과정까지 구현된 코드가 올라갈 예정입니다. Decode 에 대한 구현 과정은 다음 포스트에서 다룹니다.
Reference
- McCallum, A., Freitag, D., & Pereira, F. C. (2000, June). Maximum Entropy Markov Models for Information Extraction and Segmentation. In ICML
- Lafferty, J., McCallum, A., & Pereira, F. C. (2001). Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In ICML