LDAvis 는 토픽 모델링에 자주 이용되는 Latent Dirichlet Allocation (LDA) 모델의 학습 결과를 시각적으로 표현하는 라이브러리입니다. LDA 는 문서 집합으로부터 토픽 벡터를 학습합니다. 토픽 벡터는 단어로 구성된 확률 벡터, \(P(w \vert t)\) 입니다. 토픽 \(t\) 로부터 단어 \(w\) 가 발생할 확률을 학습합니다. 토픽 벡터는 bag-of-words model 처럼 고차원 벡터이기 때문에 여러 토픽 간의 관계를 파악하기가 어렵습니다. 또한 각 토픽의 키워드를 인식하기 어렵습니다. LDAvis 는 차원 축소 방법인 Principal Component Analysis (PCA) 와 키워드 추출 방법을 이용하여 토픽 간의 관계와 토픽 키워드를 손쉽게 이해할 수 있도록 도와줍니다. 이번 포스트에서는 Python 라이브러리인 gensim 을 이용하여 LDA 모델을 학습하고, LDAvis 의 Python wrapper 인 pyLDAvis 를 이용하여 시각화를 하는 과정을 살펴봅니다.
Visualize high dimensional space
고차원의 벡터를 이해하기 위하여 시각화 방법들이 이용됩니다. 대표적인 방법으로 t-SNE 라 불리는 t-Stochastic Neighbor Embedding 이 있습니다. t-SNE 는 고차원 공간에서 유사한 두 벡터가 2 차원 공간에서도 유사하도록, 원 공간에서의 점들 간 유사도를 보존하면서 차원을 축소합니다. 우리가 이해할 수 있는 공간은 2 차원 모니터 (지도) 혹은 3 차원의 공간이기 때문입니다.
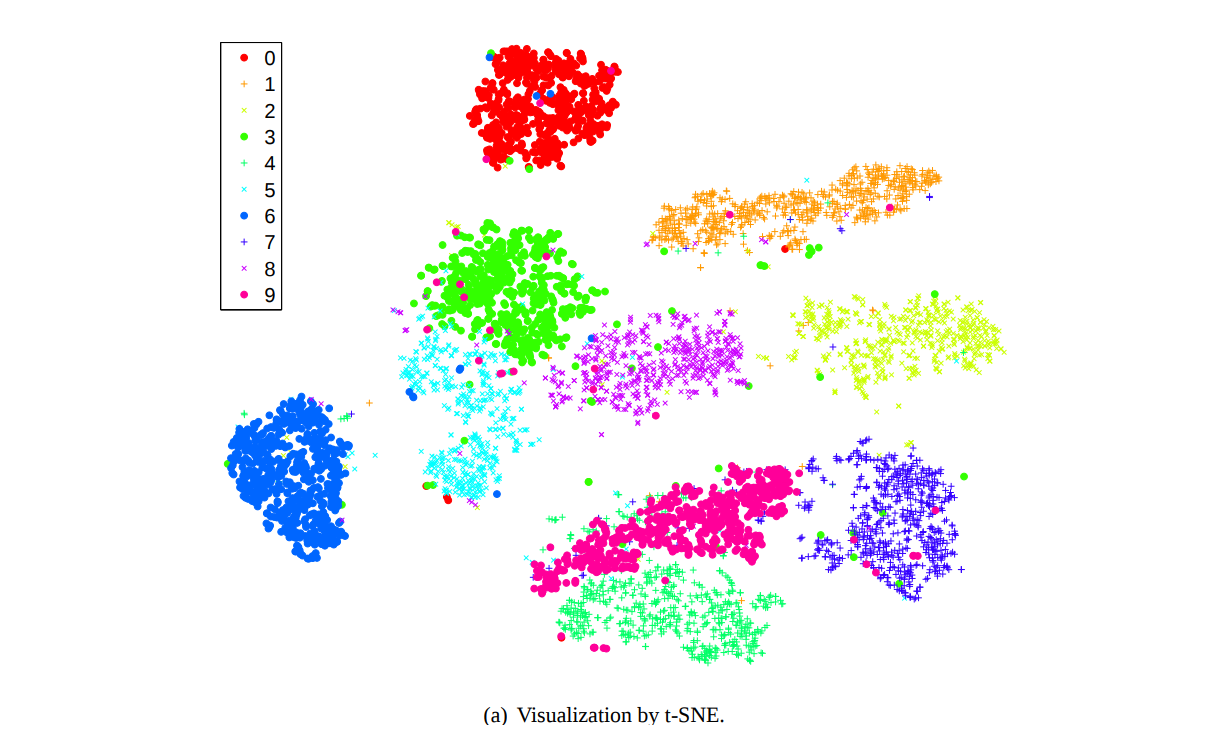
위 그림은 t-SNE 가 제안되었던 Maaten (2008) 에서 10 개의 숫자 손글씨인 MNIST 데이터를 2 차원으로 압축하여 시각화한 그림입니다. 같은 색은 같은 숫자를 의미합니다. MNIST 는 (28, 28) 크기의 784 차원 데이터입니다. 우리가 784 차원을 상상할 수는 없지만, 이를 2 차원으로 압축하면 어떤 이미지들이 유사한지 시각적으로 이해할 수 있습니다.
이런 목적으로, 딥러닝 모델들을 포함한 여러 머신 러닝 모델들이 학습하는 고차원의 벡터 공간을 이해하기 위한 목적으로 t-SNE 가 이용됩니다. (t-SNE 에 대한 자세한 설명은 이후 다른 포스트에서 다루겠습니다.)
t-SNE 외에도 Multi-Dimensional Scaling (MDS) 나 ISOMAP 과 같은 다양한 manifold 알고리즘들이 고차원의 시각화를 위해 이용됩니다. 그리고 더 나아가서는 Deep learning models 들도 시각화를 위해 이용될 수도 있습니다. 아래는 Hinton 교수님의 2006 년도 논문의 그림입니다. 약 2 만 개의 단어로 표현되는 20 News group 문서를 deep belief network 에 학습시켜 얻은 2 차원 벡터입니다. 여기서도 같은 색은 같은 카테고리를 의미합니다.
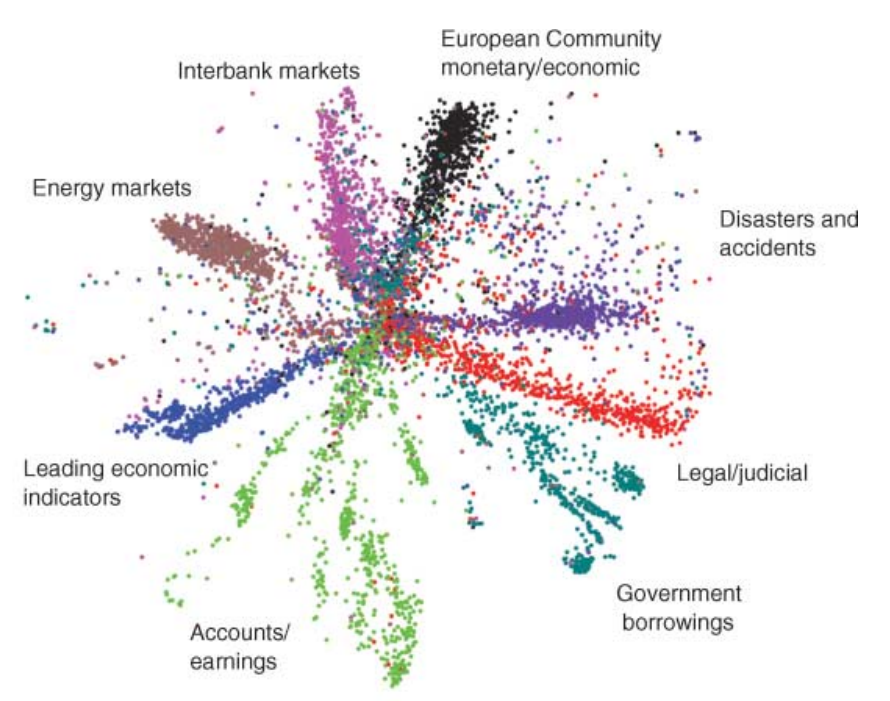
이 방법들 모두 원 공간에서 유사한 벡터가 저차원 공간에서도 유사하기를 기대합니다. 물론 유사도의 metrics 이 다를 수 있습니다. t-SNE 의 경우에는 2 차원의 공간에서 Euclidean distance 를 기준으로 유사하도록 유도합니다. Hinton 교수님의 그림은 벡터 간 내적 (inner product) 이 유사도로 이용됩니다.
고차원의 벡터 시각화에 대한 이야기로 시작한 이유는 토픽 모델링에서 자주 이용되는 Latent Dirichlet Allocation (LDA) 모델이 단어 공간으로 표현되는 토픽 벡터를 학습하기 때문입니다. 뒤이어 LDA 에 대하여 간단히 알아보도록 합니다.
Brief introduction of Latent Dirichlet Allocation (LDA)
Latent Dirichlet Allocation (LDA) 는 토픽 모델링에 이용되는 대표적인 알고리즘입니다. 여기서 말하는 토픽은 “어떤 주제를 구성하는 단어들”입니다. 추상적인 정의입니다. 흔히 우리가 말하는 “이 글의 주제”와 같습니다. 한 토픽을 설명하기 위하여 특정 단어들이 이용될 것입니다. 문서 집합에서 이 단어 집합을 찾으려는 것이 토픽 모델링입니다. 일종의 word-level semantic clustering 입니다.
LDA 는 세 가지 가정을 합니다. 첫째, “문서는 여러 개의 토픽을 지닐 수 있고 한 문서는 특정 토픽을 얼마나 지녔는지의 확률 벡터로 표현된다” 입니다. 이 말은 아래와 같은 식으로 기술됩니다. \(t\) 는 토픽, \(d\) 는 문서입니다.
\[P(t \vert d)\]둘째, “하나의 토픽은 해당 토픽에서 이용되는 단어의 비율로 표현된다” 입니다. 이는 아래와 같은 각 토픽 별 단어의 생성 확률 분포 식으로 표현됩니다. \(w\) 은 단어입니다.
\[P(w \vert t)\]그리고 한 문서에서 특정 단어들이 이용될 가능성은 위의 두 확률 분포의 곱으로 표현됩니다. 정확히는 이 사이에 각 토픽이 발생할 확률 \(P(t)\) 도 곱해집니다. 아래 식은 정확한 LDA 의 식이 아니지만, 개념적인 이해를 위해 아래처럼만 적어두도록 하겠습니다.
\[\prod_i P(w_i \vert t_i) \cdot P(t_i \vert d)\]사실 LDA 는 Probablistic Latent Semantic Indexing (pLSI) 의 모델의 학습할 패러메터의 개수를 줄여 over-fitting 을 방지하고, 새로운 문서에 대한 topic vector 를 inference 할 수 있도록 개선한 모델입니다. LDA 의 이해는 pLSI 의 이해로부터 시작하는 것이 좋습니다. pLSI 에서는 단어 \(w\) 와 문서 \(d\) 가 발생할 확률 \(P(w,d)\) 를 다음처럼 정의합니다. 한 문서가 특정한 토픽 벡터를 지니고, 각 토픽 별 단어 확률 분포와 이를 곱하여 한 문서에서 단어가 발생할 확률을 계산합니다.
\[P(w,d) = \sum_t P(w \vert t) \cdot P(t \vert d) \cdot P(t)\]그러나 우리는 토픽 \(t\) 의 분포를 모르기 때문에 이를 추정해야 합니다. pLSI 나 LDA 모두 이를 학습합니다. 그 결과 두 모델 모두 \(P(w \vert t)\) 를 학습합니다. 토픽 \(t\) 마다 단어 \(w\) 가 얼마나 자주 등장하는지에 대한 확률 분포입니다.
위 설명은 LDA 와 pLSI 의 간략한 설명입니다. 자세한 LDA 의 설명은 이후 다른 포스트에서 이어 하겠습니다. 기억할 점은, 토픽 모델링은 단어로 표현되는 토픽 벡터를 학습한다는 것 입니다. 그리고 이는 단어 개수만큼의 고차원이며, 이를 시각화하여 토픽 모델링의 결과를 이해하려 합니다.
Codes
Gensim 은 Python 으로 구현된 topic modeling / embedding 용 라이브러리입니다. Gensim 은 Python 사용자들에게 NLP 의 장벽을 낮춰준 정말 고마운 라이브러리입니다. 처음 0.12 버전까지는 Latent Dirichlet Allocation (LDA), Latent Semantic Indexing (LSI), Random Projection (RP) 와 같은 토픽 모델링 알고리즘들을 제공하였습니다. 이후 Google 에서 공개한 Word2Vec, Doc2Vec 및 Facebook Research 의 FastText, 그리고 keyword & key-sentence extraction 을 위한 TextRank (정확히는 그 변형) 까지 제공하고 있습니다.
pyLDAvis 를 이용하기 위해서는 일단 LDA 를 학습해야 합니다. 우리는 Gensim 을 이용하여 LDA 를 학습하는 방법부터 살펴봅니다.
Prepare trainable data from text
Gensim 의 공식 홈페이지에서는 LDA 를 학습하는 튜토리얼을 제공하고 있습니다. 이를 간략히 살펴봅니다.
우리는 문서 집합을 가지고 있습니다. 이는 텍스트 파일로, 한 줄이 하나의 문서에 해당합니다. 이 텍스트로부터 LDA 를 학습하기 위한 input data, corpus 를 만듭니다. 토크나이징은 미리 해두었습니다. 각 문서에서 명사만을 남기고, 다른 단어들은 모두 제거한 뒤 뛰어쓰기 기준으로 단어를 구분하였습니다. doc.split() 은 토크나이징 역할을 합니다.
corpus_path = '2016-10-20_nountokenized.txt'
class Documents:
def __init__(self, path):
self.path = path
def __iter__(self):
with open(self.path, encoding='utf-8') as f:
for doc in f:
yield doc.strip().split()
documents = Documents(corpus_path)Gensim 의 preprocessing utils 에는 아쉽게도 min count filtering 을 제공하는 vectorizer 가 없습니다. 이를 직접 구현해야 합니다. 일단 단어를 int 형식의 idx 로 변환하는 encoder, Dictioanry 를 학습합니다. Dictionary 에 list of list of str 형식의 documents 를 입력하면 Dictioanry 가 학습됩니다. 아래 예시에서는 총 37,987 개의 단어가 학습되었습니다.
import gensim
dictionary = gensim.corpora.Dictionary(documents)
print('dictionary size : %d' % len(dictionary)) # dictionary size : 37987이 중 40 번 이하로 등장한 단어들은 모두 제거하겠습니다. 이를 위해서 각 단어가 몇 번 등장하였는지 카운팅을 다시 해야 합니다. collections.Counter 를 이용하였습니다. 그리고 제거할 단어 removal_word_idxs 는 str 이 아닌 int 형식의 set 이어야 합니다. 이를 위해 min_count 이하로 등장한 단어를 dictionary.token2id 를 이용하여 int 로 변환하여 removal_word_idxs 에 저장합니다.
이를 filter_tokens 함수에 입력하여 제거합니다. 이 과정에서 다음과 같은 일이 발생합니다. 만약 ‘a’, ‘b’, ‘c’ 가 각각 100, 5, 50 번 등장하였다면, 40 번 이하로 등장한 단어 ‘b’ 가 token2id 에서 제거됩니다.
# before filter_tokens
dictionary.token2id = {
'a': 0,
'b': 1,
'c': 2,
...
}
# after filter_tokens
dictionary.token2id = {
'a': 0,
'c': 2,
...
}
idx 가 0, 1, 2 순서로 이용되어야 차원의 개수가 줄어듭니다. 이를 위해 compatify() 를 실행해야 합니다. 그 결과 idx 의 빈틈을 당겨서 새롭게 indexing 을 합니다. 이 부분을 굳이 이렇게 구현해야 하나 싶기는 합니다.
# after compatify
dictionary.token2id = {
'a': 0,
'c': 1,
...
}
여하튼 infrequent words 를 제거하면 10,354 개의 단어가 남습니다.
from collections import Counter
min_count = 40
word_counter = Counter((word for words in documents for word in words))
removal_word_idxs = {
dictionary.token2id[word] for word, count in word_counter.items()
if count < min_count
}
dictionary.filter_tokens(removal_word_idxs)
dictionary.compactify()
print('dictionary size : %d' % len(dictionary) # dictionary size : 10354Dictionary 에는 doc2bow 함수가 있습니다. 이 함수는 list of str 형식의 단어열을 (단어, 빈도수) list 로 변환하는 함수입니다. 그리고 LDA 의 학습 데이터 형식은 list of list of (int, int) 로 표현된 문서입니다. 이를 Corpus 라는 class 로 만듭니다. Corpus 는 우리가 앞서 학습한 Dictionary 를 이용합니다. 이후 len() 함수를 이용할 일도 있으니 미리 __len__ 함수도 구현해둡니다.
class Corpus:
def __init__(self, path, dictionary):
self.path = path
self.dictionary = dictionary
self.length = 0
def __iter__(self):
with open(self.path, encoding='utf-8') as f:
for doc in f:
yield self.dictionary.doc2bow(doc.split())
def __len__(self):
if self.length == 0:
with open(self.path, encoding='utf-8') as f:
for i, doc in enumerate(f):
continue
self.length = i + 1
return self.length
corpus = Corpus(corpus_path, dictionary)
for i, doc in enumerate(corpus):
if i >= 5: break
print(doc)For loop 을 이용하여 corpus 를 확인하면 아래처럼 각 문서별로 idx 로 변환된 (단어, 빈도수) 의 list 가 출력됩니다.
[]
[(0, 1), (1, 1), (2, 1), (3, 1)]
[(4, 1), (5, 4), (6, 1), (7, 1), (8, 1), (9, 1), (10, 1), ...]
[(5, 1), (53, 1), (91, 1), (93, 2), (136, 2), (147, 4), ...]
[(5, 1), (93, 2), (149, 1), (182, 1), (187, 1), (188, 1), ...]
Prepare trainable data from bag-of-words x
Gensim 을 이용하여 LDA 용 학습 데이터를 만들 때도 있지만, 다른 목적 때문에 sklearn.feature_extraction.text.CountVectorizer 를 이용하여 bag-of-words model 를 만들어 둘 때도 많습니다. 이를 Gensim 의 corpus 로 변환하려면 몇 가지 작업을 하여야 합니다. 저는 주로 bag-of-words model 을 만든 뒤, list of str 형식의 index2word 와 함께 pickling 을 하여 가지고 다니는 편입니다. x 는 scipy.sparse.csr_matrx 입니다.
import pickle
data_path = '2016-10-20-news-bow.pkl'
with open(data_path, 'rb') as f:
params = pickle.load(f)
x = params['x']
index2word = params['index2word']
word2index = params['word2index']gensim.matutils 에는 Sparse2Corpus 라는 함수를 제공합니다. 이 함수는 csr_matrix 같은 sparse matrix 를 Gensim 학습용 corpus 데이터로 변환해줍니다.
csr_matrix 는 rows 가 문서, columns 가 단어입니다. 하지만 토픽 모델링에서는 (단어, 문서) 형식의 sparse matrix 를 이용하는 경우가 많았습니다. 그렇기 때문에 Sparse2Corpus 의 argument 는 documents_columns=True 으로 설정된 경우가 많습니다. 이를 반드시 False 로 설정해야 합니다.
Dictionary 도 from_corpus 라는 함수를 제공합니다. gensim.corpora.Dictionary 은 document frequency (DF) 정보가 필요하기 때문에 corpus 와 idx to word 정보가 포함된 dictionary 를 입력해야 합니다. index2word 는 list of str 형식이기 때문에 enumerate 를 적용하면 (int, str) 형식으로 변형됩니다. 이를 dict 에 입력하면 형식이 dict 로 변형됩니다.
import gensim
from gensim.corpora.dictionary import Dictionary
corpus = gensim.matutils.Sparse2Corpus(x, documents_columns=False)
dictionary = Dictionary.from_corpus(
corpus,
id2word = dict(enumerate(index2word))
)LDA 의 학습은 gensim.models.LdaModel 에 corpus, dictionary 를 입력하고 num_topics 를 설정하면 됩니다. 학습된 모델은 pickling 을 이용하여 저장할 수 있습니다.
from gensim.models import LdaModel
lda_model = LdaModel(corpus, id2word=dictionary, num_topics=50)
with open(lda_model_path, 'wb') as f:
pickle.dump(lda_model, f)학습된 LDA model 은 doc - topic 행렬 정보를 가지고 있지 않습니다. 대신 \(P(w \vert t)\) 인 (topic, term) 행렬 정보와 \(P(t)\) 인 topic probability 를 저장하고 있습니다. 각각의 위치는 아래와 같습니다.
LDA 는 Gibbs sampling 에 기반하여 topic - term probability 를 학습합니다. Gensim 의 구현체는 학습 과정에서 발생한 topic - term frequency 정보가 모델에 저장되어 있습니다. lda_model.get_lambda() 를 실행하면 이 값을 받을 수 있습니다. 각 topic 의 빈도수의 합으로 topic - term frequency 를 나눠줌으로써 topic - term probability 를 구할 수 있습니다. 이 과정을 get_topic_term_prob 라는 함수로 만듭니다.
def get_topic_term_prob(lda_model):
topic_term_freqs = lda_model.state.get_lambda()
topic_term_prob = topic_term_freqs / topic_term_freqs.sum(axis=1)[:, None]
return topic_term_probLdaModel.alpha 에는 (n_topics,) 크기의 numpy.ndarray 가 저장되어 있습니다. Topic probability vector 입니다. get_topic_term_prob 함수를 이용하여 topic - term probability 를 가져옵니다. 확률 벡터이기 때문에 하나의 row 의 합은 1 입니다.
print(lda_model.alpha.shape) # (n_topics,)
print(lda_model.alpha.sum()) # 1.0
topic_term_prob = get_topic_term_prob(lda_model)
print(topic_term_prob.shape) # (n_topics, n_terms)
print(topic_term_prob[0].sum()) # 1.0Train and visualize trained LDA
pyLDAvis 의 학습은 더 간단합니다. 본래 LDAvis 는 Gensim 의 LDA 를 위해 만들어진 라이브러리가 아니지만, Python 사용자들의 많은 사람들이 Gensim LDA 를 이용하기 때문에 전용 함수를 하나 만들어줬습니다. 이를 gensimvis 라는 이름으로 import 합니다.
LDAvis 는 본래 다섯 가지 정보를 입력받습니다.
topic_term_dists # numpy.ndarray, shape = (n_topics, n_terms)
doc_topic_dists # numpy.ndarray, shape = (n_docs, n_topics)
doc_lengths # numpy.ndarray, shape = (n_docs,)
vocab # list of str, vocab list
term_frequency # numpy.ndarray, shape = (n_vocabs,)
gensim.models.LdaModel 에 위의 정보들이 어디에 포함되어 있는지 알기 때문에 pyLDAvis.gensim.prepare 함수는 학습된 LdaModel, corpus, dictionary 를 요구합니다.
import pyLDAvis.gensim as gensimvis
prepared_data = gensimvis.prepare(lda_model, corpus, dictionary)위에서 살펴본 바와 같이 term_topic_dists 는 학습된 모델로부터 간단히 만들 수 있습니다. 그러나 doc_topic_dists 는 gensim.LdaModel 이 학습 후 버려버립니다. 이는 아래와 같은 함수를 실행시켜 얻을 수 있습니다. inference 함수는 gensim 의 Corpus 를 입력해야 하며, 모델 학습 시에는 gamma 외에도 다른 값이 return 됩니다. 새로운 문서에 대한 inference 시에는 gamma 와 None 이 함께 return 되기 때문에 gamma, _ 로 inference 의 return 값을 받습니다.
gamma, _ = topic_model.inference(corpus)그러나 위 부분은 pyLDAvis 의 prepare 함수 내부에구현되어 있습니다. 우리가 실행할 함수는 오로직 gensimvis.prepare(lda_model, corpus, dictionary) 입니다.
학습된 LDA 모델로부터 추출된 정보들은 pyLDAvis._prepare.prepare 함수에 넘겨집니다. 최종적으로 PreparedData 라는 class 의 instance 가 return 됩니다. 이는 namedtuple 을 상속받은 함수로, to_dict 와 to_json 함수가 내장되어 있습니다. LDAvis 의 역할은 시각화에 필요한 정보들을 추출한 뒤, 이를 JSON 으로 변환하여 D3 로 구현된 시각화 HTML 페이지에 rendering 을 하는 것 입니다.
이 과정은 아래의 함수 하나로 실행됩니다. Jupyter notebook 에서 위 부분을 실행중이라면 output cell 에 HTML page 가 뜹니다.
pyLDAvis.display(prepared_data)이 정보를 저장하고 싶을 때에는 아래의 save_html 함수를 실행하면 됩니다.
pyLDAvis.save_html(prepared_data, pyldavis_html_path)해당 예시는 아래에 있습니다. 만약 아래에 pyLDAvis 의 결과가 출력되지 않는다면 데이터를 로딩하는 중일 수 있습니다 (2.2 Mb 크기입니다). 토픽을 누르면 해당 토픽의 키워드들이 오른쪽에 출력됩니다. lambda 를 조절하면 keyword score 의 두 기준의 weight 가 조율되어 새로운 키워드를 선택합니다.
LDAvis
LDAvis 는 두 가지 정보를 출력합니다. 첫째는 HTML 의 왼쪽에 출력되는 topic 의 2 차원 embedding vector 입니다. 비슷한 위치에 존재하는 토픽들은 서로 비슷한 문맥을 지니고 있습니다. 그리고 둘째는 오른쪽에 출력되는 각 토픽의 키워드 입니다. 이들의 원리를 살펴봅니다.
2-D visualization of topic vectors
토픽은 단어 개수의 차원을 지니고 있습니다. 이를 2 차원으로 압축하기 위해서는 차원 축소 방법이 이용되어야 합니다. LDAvis 는 Principal Component Analysis (PCA) 를 이용하여 n_terms 차원의 벡터들을 2 차원으로 압축합니다. 이는 아래와 같이 작동합니다.
from sklearn.decomposition import PCA
topic_vector = lda_model.expElogbeta
y = PCA(n_components=2).fit_transform(topic_vector)
print('{} -> {}'.format(topic_vector.shape, y.shape))
# (n_topics, n_terms) -> (n_topics, 2)PCA 의 특성상 모든 토픽에 자주 등장하는 단어는 큰 정보력을 지니지 못합니다. 토픽 간에 다른 패턴으로 등장하는 단어들을 중심으로 2 차원 지도의 좌표를 학습합니다.
Topic labeling from keyword extraction
이전의 clustering labeling 포스트 에서 언급한 것처럼 keyword extraction 연구들에서 공통적으로 제안하는 키워드의 기준은 두 가지 입니다. 첫째는 salience 입니다. 한 토픽의 키워드라면, 각 토픽에 속한 많은 문서들에서 등장해야 합니다. 즉 \(P(w \vert t)\) 가 커야 합니다.
둘째는 discriminative power 입니다. \(P(w \vert t)\) 가 가장 높은 단어는 ‘a, the, -은, -는, -이, -가’ 와 같은 문법적인 단어일 것입니다^1. 하지만 ‘a’라는 단어는 어떤 토픽을 명확히 지시해주지도 않습니다. 차별성이 없는 단어는 키워드로 부적합합니다. 그래서 LDAvis 에서는 \(P(w \vert t)\) 를 \(P(w)\) 로 나누었습니다. 한 토픽에서 자주 등장하는 단어라 하더라도 본래 자주 등장하는 단어라면 그 중요도를 낮추겠다는 의미입니다. 이는 마치 Inverse Document Frequency (IDF) 의 관점과도 비슷합니다.
그러나 최고의 discriminative power 를 지닌 단어는 infrequent terms 일 가능성이 높습니다. 한 토픽에서만 등장한 단어는 몇 번 등장하지 않을 가능성이 높습니다. 즉, salience 와 discriminative power 사이에는 negative correlation 이 있습니다. 앙면을 모두 고려하여 키워드를 선택해야 합니다.
그래서 LDAvis 에서는 두 관점의 중요도를 사람이 직접 정할 수 있도록 하였습니다. HTML 의 오른쪽 상단에 \(\lambda\) 라는 값이 있습니다. 이 값은 [0, 1] 사이에서 조절가능한 값입니다. 그리고 그 아래 키워드 랭킹은 다음의 점수로 계산됩니다. \(\lambda\) 를 1 로 설정하면 토픽 별로 가장 자주 등장하는 단어들을 우선적으로 키워드로 선택한다는 의미이며, \(\lambda\) 를 0 에 가깝게 설정할수록 토픽 간에 차이가 많이 나는 단어를 선택한다는 의미입니다.
\[\lambda \cdot P(w \vert t) + (1 - \lambda) \cdot \frac{P(w \vert t)}{P(w)}\]이처럼 알고리즘이 키워드를 선택하지 않고 사람이 조절 가능하도록 여유를 둔 이유도 있습니다. \(P(w \vert t)\) 나 \(\frac{P(w \vert t)}{P(w)}\) 는 토픽 모델링이 학습한 고차원 공간을 바라보는 한 가지 관점입니다. 그리고 두 가지 관점간의 중요도를 조절하여 고차원의 공간을 조명하는 것과 같습니다. 그런데 고차원 공간의 정보를 압축하여 이해할 때에는 언제나 왜곡이 생깁니다. 이러한 왜곡 때문에 실제로는 가까운데 차원 축소의 결과 멀리 떨어진 것처럼 보이는 점들도 있습니다 (t-SNE 포스트에서 더 자세히 다룹니다). 그렇기 때문에 한 기준으로 이해한 하나의 2 차원 지도를 보여주는 것이 아니라, 관점의 interploation 을 거쳐 다각도로 공간을 바라본다면 좀 더 깊은 이해를 할 수 있습니다. 이는 마치 한 물체를 앞에서부터 뒤까지 돌아가며 살펴보는 것과 같습니다. 그런 의미에서 LDAvis 는 해석의 여지를 의도적으로 사람에게 주었습니다.
Reference
- Hinton, G. E., & Salakhutdinov, R. R. (2006). Reducing the dimensionality of data with neural networks. science, 313(5786), 504-507.
- Maaten, L. V. D., & Hinton, G. (2008). Visualizing data using t-SNE. Journal of machine learning research, 9(Nov), 2579-2605.
- Sievert, C., & Shirley, K. (2014). LDAvis: A method for visualizing and interpreting topics. In Proceedings of the workshop on interactive language learning, visualization, and interfaces (pp. 63-70).
Notes
- [^1] 실제로 이를 junk term 이라하여, 토픽 모델링의 품질을 저하하는 요인이기도 합니다. 이에 대한 내용은 다른 포스트에서 다루도록 합니다