이전의 KR-WordRank 에는 토크나이저를 이용하지 않는 한국어 키워드 추출 기능만 있었는데, 최근에 KR-WordRank 에 핵심 문장을 추출하는 기능을 추가하여 KR-WordRank (1.0) 을 배포하였습니다. TextRank 는 핵심 문장을 선택하기 위하여 토크나이저를 이용하지만 (물론 이전 포스트에서 subword tokenizer 를 이용하면 된다는 점도 확인하였습니다), KR-WordRank 의 단어 가능 점수 (Ranking 값) 을 토크나이저의 재료로 이용하는 것은 어려웠습니다. 또한 TextRank 의 핵심 문장 선택의 논리에 동의되지 않는 부분이 있어서 이를 개선한 기능을 KR-WordRank 에 추가하였습니다. 이 포스트에서는 이에 대한 개발 과정 및 실험 결과를 정리합니다.
WordRank & KR-WordRank
WordRank 는 띄어쓰기가 없는 중국어와 일본어에서 graph ranking 알고리즘을 이용하여 단어를 추출하기 위해 제안된 방법입니다. Ranks 는 substring 의 단어 가능 점수이며, 이를 이용하여 unsupervised word segmentation 을 수행하였습니다. WordRank 는 substring graph 를 만든 뒤, graph ranking 알고리즘을 학습합니다.
Substring graph 는 아래 그림의 (a), (b) 처럼 구성됩니다. 먼저 문장에서 띄어쓰기가 포함되지 않은 모든 substring 의 빈도수를 계산합니다. 이때 빈도수가 같으면서 짧은 substring 이 긴 substring 에 포함된다면 이를 제거합니다. 아래 그림에서 ‘seet’ 의 빈도수가 2 이고, ‘seeth’ 의 빈도수가 2 이기 때문에 ‘seet’ 는 graph node 후보에서 제외됩니다. 두번째 단계는 모든 substring nodes 에 대하여 links 를 구성합니다. ‘that’ 옆에 ‘see’와 ‘dog’ 이 있었으므로 두 마디를 연결합니다. 왼쪽에 위치한 subsrting 과 오른쪽에 위치한 subsrting 의 edge 는 서로 다른 종류로 표시합니다. 이때, ‘do’ 역시 ‘that’의 오른쪽에 등장하였으므로 링크를 추가합니다. 이렇게 구성된 subsrting graph 에 HITS 알고리즘을 적용하여 각 subsrting 의 ranking 을 계산합니다.
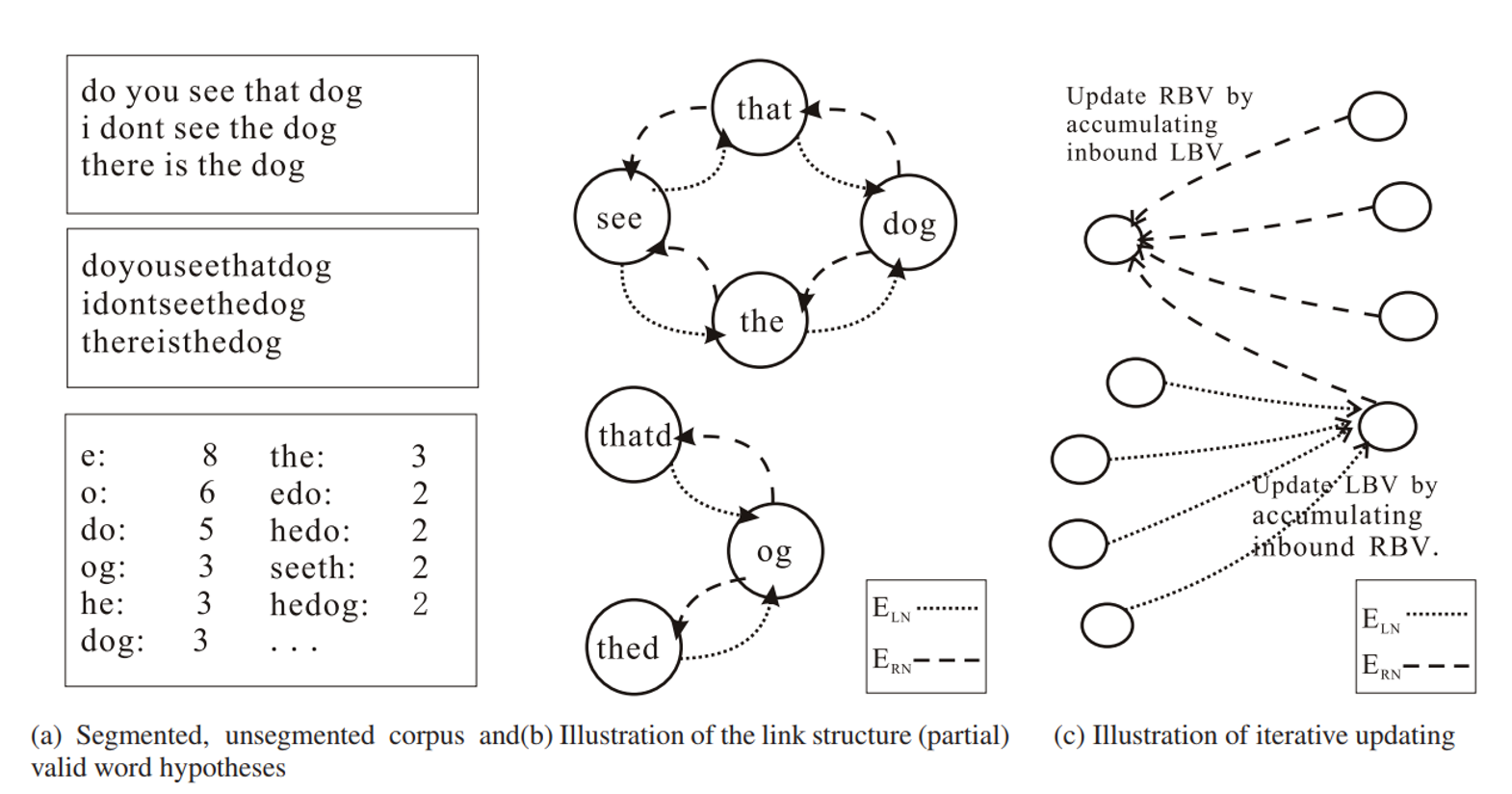
WordRank 의 가설은 HITS 와 비슷합니다. 단어의 좌/우에는 단어가 등장하고, 단어가 아닌 substring 좌/우에는 단어가 아닌 substring 이 등장합니다. 단어는 다른 많은 단어들과 연결되기 때문에 질 좋은 links 가 많이 연결되며, 단어가 아닌 substring 은 소수의 backlinks 를 받습니다. 그마저도 단어가 아닌 substring 으로부터 출발한 links 입니다. Ranking update 를 하면, 단어들은 rank 가 높아집니다.
그러나 WordRank 를 한국어 데이터에 그대로 적용하면 학습 결과가 좋지 않습니다. 첫째로 한국어 텍스트 데이터에는 띄어쓰기가 있습니다. 일부 띄어쓰기 오류가 존재하지만, 이는 오류이기 때문에 다수는 띄어쓰기가 되어 있습니다. 둘째로 한국어는 교착어이며 어절은 두 개 이상의 단어 혹은 형태소가 결합되어 만들어집니다. 이 때 의미를 지니는 단어들은 어절의 왼쪽 (L) 에, 문법 기능을 하는 단어나 형태소는 어절의 오른쪽 (R) 에 등장하며, 우리가 추출하고 싶은 미등록 단어들은 L 에 해당합니다. 하지만 WordRank 는 띄어쓰기 정보를 무시하며, L 과 R 에 관계없이 모든 단어를 추출합니다.
KR-WordRank 는 이러한 문제점을 개선하기 위하여 제안된, 한국어 단어 추출을 위한 WordRank 개선 모델 입니다. KR-WordRank 는 띄어쓰기 정보를 이용하며, 어절 내의 subword 의 위치 (L, R) 를 분리하여 subword graph 의 마디로 만듭니다. 또한 추출된 단어 중 중복적인 어절을 제거하는 후처리 과정을 추가하였습니다. 만약 영화평 문장에서 단어를 추출할 경우에는 영화 뿐 아니라 영화다, 영화의, 영화는 과 같이 영화를 포함한 많은 어절들이 높은 랭킹을 가지게 됩니다. 이 때 다/R, 의/R, 는/R 도 높은 랭킹을 지니기 때문에 영화다 가 더 높은 랭킹을 지니는 L 과 R 의 결합 영화/L + 다/R 일 경우에는 이를 추출된 단어 집합에서 제거합니다.
KR-WordRank 에 대한 자세한 설명은 이전의 포스트를 참고하세요.
처음에는 비지도학습 기반으로 한국어 텍스트에서 단어를 추출하기 위하여 KR-WordRank 를 만들었는데, 이는 단어 추출기보다도 키워드 추출기의 역할을 하고 있었습니다. KR-WordRank 는 subword graph + PageRank 로 학습된 ranking 을 단어 점수로 이용하는데, 이 값이 매우 큰 subwords 는 주어진 문서 집합에서 등장하는 단어를 이용하여 단어 그래프를 만든 뒤 TextRank 를 이용하여 랭킹을 학습하였을 때에도 높은 랭킹값을 지닙니다. Subword graph 는 word graph 에 단어가 아닌 subwords 들이 조금 더 추가된 그래프이기 때문입니다. 그래서 어느 순간부터는 ‘한국어 문서 집합에서 미등록단어 문제를 해결하며 동시에 키워드를 추출하는 방법’으로 KR-WordRank 를 이용하고 있습니다.
Sentence extraction with KR-WordRank
KR-WordRank 는 subwords 의 랭킹을 계산하여 단어 혹은 키워드를 추출합니다. 이 때 단어가 아닌 subwords 를 제거하기 위하여 후처리 과정이 필수로 이용됩니다. 즉, subwords 의 랭크 값은 단어 점수로 그대로 이용하기가 어렵습니다. 이전에 KR-WordRank 를 이용하는 토크나이저를 만들어보려 여러 번 시도해 보았는데 좋은 결과를 얻지 못하였습니다. 그리고 문장을 토크나이징 할 수 없기 때문에 핵심 문장을 추출하는 것이 어렵겠다고 생각하였습니다.
그런데 최근에 핵심 문장의 선택 기준에 대해 고민하는 도중에, 핵심 문장의 추출을 위해 토크나이저를 이용해야만 한다는 생각이 바뀌었습니다. TextRank 의 문장 간 유사도 척도 때문에 PageRank 로부터 높은 랭크 값을 부여 받은 문장들은 문서 집합 내에서 자주 등장하는 단어를 많이 포함하는 문장입니다. 이러한 기준의 문장을 핵심 문장으로 찾는 것이 핵심이지, 반드시 토크나이징을 하여 문장 간 유사도를 계산한 뒤 PageRank 를 학습시킬 필요는 없습니다. 그리고 문서 집합 내에서 자주 등장하는 단어는 주로 TextRank 가 단어 그래프로부터 선택하는 키워드들입니다. 즉, TextRank 의 핵심 문장의 조건은 문서 집합 내에서 키워드로 선택된 단어를 많이 포함하는 문장이며, 이는 상식적으로도 핵심 문장의 조건에 부합합니다. 그리고 한 문장에서 특정 단어가 포함되어 있는지 확인하는 작업은 어렵지 않습니다.
이를 위해 우선 키워드를 학습해야 합니다. KR-WordRank 는 선택된 키워드 집합을 핵심 문장 추출의 argument 로 이용합니다. 이는 이전의 KR-WordRank 를 이용할 수 있습니다. 개발을 위하여 라라랜드의 영화평 데이터를 이용하였습니다.
from krwordrank.word import KRWordRank
texts = [] # Comments about 'La La Land (2016)'
wordrank_extractor = KRWordRank(min_count=5, max_length=10)
keywords, rank, graph = wordrank_extractor.extract(texts, num_keywords=100)
추출된 100 개의 키워드는 아래와 같습니다. 괄호 안은 PageRank 에 의하여 학습된 각 단어의 랭크입니다. 물론 그리고 와 같은 불필요한 단어도 키워드로 학습되지만, 대부분의 단어들은 영화를 잘 설명하는 단어들 입니다.
| 영화 (201.024) | 현실 (15.192) | ㅠㅠ (10.083) | 내가 (7.498) | ost (6.092) |
| 너무 (81.536) | 생각 (14.909) | 많이 (9.885) | 엔딩 (7.407) | 아니 (6.072) |
| 정말 (40.537) | 지루 (13.779) | 사람 (9.568) | 별로 (7.318) | 함께 (6.069) |
| 음악 (40.434) | 다시 (13.598) | 모두 (9.204) | 대한 (7.047) | 10 (6.017) |
| 마지막 (38.598) | 감동 (13.583) | 남는 (9.055) | 이렇게 (7.016) | 슬픈 (5.994) |
| 뮤지컬 (23.198) | 보는 (12.472) | 기대 (9.054) | 중간에 (6.963) | 서로 (5.906) |
| 최고 (21.810) | 좋아 (11.982) | 재즈 (9.039) | 평점 (6.945) | 두번 (5.834) |
| 사랑 (20.638) | 재밌 (11.893) | 라이언 (8.989) | 라라 (6.657) | 특히 (5.827) |
| 꿈을 (20.437) | 재미 (11.393) | 연출 (8.609) | 가슴 (6.569) | 남자 (5.787) |
| 아름 (20.324) | 좋고 (11.347) | 눈물이 (8.557) | 엠마 (6.435) | 행복 (5.752) |
| 영상 (20.283) | 계속 (11.117) | 하지만 (8.517) | 그런 (6.377) | 추천 (5.749) |
| 여운이 (19.471) | 느낌 (10.994) | 모든 (8.420) | 내용 (6.370) | 색감 (5.727) |
| 진짜 (19.064) | 조금 (10.989) | 이런 (8.417) | 오랜만에 (6.248) | 하나 (5.660) |
| 노래 (18.732) | 처음 (10.747) | 봤는데 (8.382) | 보면 (6.225) | ㅎㅎ (5.550) |
| 보고 (18.567) | 결말 (10.583) | 올해 (8.073) | 이야기 (6.188) | 않은 (5.411) |
| 좋았 (17.618) | 연기 (10.501) | 꿈과 (7.746) | 가장 (6.161) | 봤습니다 (5.357) |
| 그냥 (16.554) | 장면 (10.347) | 같은 (7.700) | 마음 (6.144) | 피아노 (5.299) |
| 스토리 (16.277) | 그리고 (10.341) | 배우 (7.603) | 한번 (6.135) | 멋진 (5.287) |
| 좋은 (15.641) | 하는 (10.265) | of (7.594) | 감독 (6.134) | 약간 (5.269) |
| 인생 (15.388) | 있는 (10.161) | 내내 (7.536) | 없는 (6.101) | 많은 (5.041) |
그리고 위의 100 개의 키워드의 랭크값을 단어 점수로 이용하여 문장 내에서 위의 단어가 존재하는지 확인합니다. 이를 위해 soynlp 의 MaxScoreTokenizer 를 이용하였습니다. 이에 대한 설명과 사용법은 이전의 soynlp tokenizer 포스트를 참고하세요.
이후에 위의 키워드 점수를 이용하여 키워드 벡터를 만들 것입니다. 하지만 PageRank 에 의하여 학습된 랭크값의 분포는 지수분포와 비슷합니다. 각 키워드 랭킹의 편차를 완화하기 위하여 랭크값의 1/2 승을 취합니다. 만약 모든 키워드가 동일한 가중치를 가지도록 만들고 싶다면 아래 함수의 scaling 에 lambda x:1 과 같은 함수를 설정할 수도 있습니다.
import math
def make_vocab_score(keywords, scaling=None):
if scaling is None:
scaling = lambda x:math.sqrt(x)
return {word:scaling(rank) for word, rank in keywords.items()}
keywords = make_vocab_score(keywords)
그리고 문장 내에 키워드들이 포함되어 있는지를 표현하는 문서 단어 행렬을 만듭니다. x 는 각 문장에 어떤 키워드가 포함되어 있는지를 표현하는 Boolean vector 입니다.
from scipy.sparse import csr_matrix
from soynlp.tokenizer import MaxScoreTokenizer
def vectorize(sents, vocab_to_idx, tokenize):
rows, cols, data = [], [], []
for i, sent in enumerate(sents):
terms = set(tokenize(sent))
for term in terms:
j = vocab_to_idx.get(term, -1)
if j == -1:
continue
rows.append(i)
cols.append(j)
data.append(1)
n_docs = len(sents)
n_terms = len(vocab_to_idx)
return csr_matrix((data, (rows, cols)), shape=(n_docs, n_terms))
tokenizer = MaxScoreTokenizer(scores=keywords)
idx_to_vocab = [vocab for vocab in sorted(keywords, key=lambda x:-keywords[x])]
vocab_to_idx = {vocab:idx for idx, vocab in enumerate(idx_to_vocab)}
x = vectorize(texts, vocab_to_idx, tokenizer.tokenize)
위의 (scaled) 랭크 값을 벡터로 만듭니다. keyvec 은 키워드의 랭크로 이뤄진 키워드 벡터입니다. 이 벡터가 핵심 문장을 선택하는 초기 기준입니다.
import numpy as np
keyvec = np.asarray([keywords[vocab] for vocab in idx_to_vocab]).reshape(1,-1)
키워드 벡터와의 Cosine distance 가 작은 문장은 여러 키워드를 포함하고 있는 문장입니다.
from sklearn.metrics import pairwise_distances
def select(x, keyvec, texts, topk=10):
dist = pairwise_distances(x, keyvec, metric='cosine').reshape(-1)
idxs = dist.argsort()[:topk]
return [texts[idx] for idx in idxs]
그런데 위의 방법은 한 가지 문제가 있습니다. 한 문장이 키워드 벡터와의 거리가 매우 작아 핵심 문장으로 선택되었다면 이와 대부분의 단어가 비슷한 다른 문장도 핵심 문장으로 선택될 수 있습니다. 즉, 핵심 문장에 비슷한 문장들이 많을 수 있습니다. 이는 TextRank 에서도 문제가 되는 부분입니다. TextRank 의 문장 그래프를 문장 간의 유사도만을 고려할 뿐, 핵심 문장으로 추출되는 문장들이 얼마나 비슷한지에 대한 penalty 는 고려되지 않습니다. 뉴스와 같은 문서 집합에 TextRank 를 적용해도 결과가 좋았던 이유는 애초에 뉴스에는 비슷한 문장이 거의 없기 때문입니다.
그래서 KR-WordRank 에서는 diversity 라는 argument 를 더했습니다. 목적은 핵심 문장으로 선택된 문장들이 다양한 종류의 키워드를 포함하도록 유도하는 것입니다. 한 문장이 핵심 문장으로 선택되면 나머지 모든 문장들과의 Cosine distance 를 계산합니다. 그리고 이 값이 diversity 보다 작은 경우에는 이전에 계산한 키워드 벡터와의 거리에 2 를 추가합니다. Cosine distance 의 최대값이 2 이기 때문입니다. 그 뒤, 다시 한 번 거리값이 가장 작은 문장을 선택합니다. 이 과정을 통하여 한 번 선택된 문장과 매우 유사한 문장은 우선 순위가 크게 밀립니다.
여기에 initial_penalty 라는 argument 도 추가하였습니다. 이는 사용자에 의한 문장의 preference 값입니다. 예를 들어 핵심 문장으로 문장의 길이가 25 ~ 80 자인 문장을 선택하고 싶다면, 이를 만족하지 않는 문장들에 적절한 penalty 를 사전에 부여하는 것입니다. 이 두 arguments 가 추가된 함수는 아래와 같습니다.
def select(x, keyvec, texts, initial_penalty, topk=10):
dist = pairwise_distances(x, keyvec, metric='cosine').reshape(-1)
dist = dist + initial_penalty
idxs = []
for _ in range(topk):
idx = dist.argmin()
idxs.append(idx)
dist[idx] += 2 # maximum distance of cosine is 2
idx_all_distance = pairwise_distances(
x, x[idx].reshape(1,-1), metric='cosine').reshape(-1)
penalty = np.zeros(idx_all_distance.shape[0])
penalty[np.where(idx_all_distance < diversity)[0]] = 2
dist += penalty
return [texts[idx] for idx in idxs]
Software
위의 기능을 함수로 정리하여 KR-WordRank 의 repository 에 올려두었습니다. 또한 PyPI 에도 등록하였기 때문에 pip 으로 설치가 가능합니다. 현재 버전은 1.0.1 입니다.
pip install krwordrank
Stopwords 제거 기능과 initial penalty 를 결정하는 함수 입력, diversity, scaling 함수 설정, 그리고 핵심 문장 추출에 이용하는 키워드의 개수 설정 등의 기능을 포함하는 summarize_with_sentences 함수를 만들었습니다.
from krwordrank.sentence import summarize_with_sentences
penalty = lambda x:0 if (25 <= len(x) <= 80) else 1
stopwords = {'영화', '관람객', '너무', '정말', '진짜'}
keywords, sents = summarize_with_sentences(
texts,
penalty=penalty,
stopwords = stopwords,
diversity=0.7,
num_keywords=100,
num_keysents=10,
scaling=lambda x:1,
verbose=False,
)
그 결과는 아래와 같습니다. 그리고 keywords 에는 KR-WordRank 에 의하여 학습된 100 개의 키워드가 포함되어 있습니다. 앞서 TextRank 포스트에서도 언급하였지만, 적당한 길이의 문장에 키워드가 어느 정도 포함되어 있으면 어떤 문장을 선택하여도 핵심 문장처럼 보입니다.
사랑 꿈 현실 모든걸 다시한번 생각하게 하는 영화였어요 영상미도 너무 예쁘고 주인공도 예쁘고 내용도 아름답네요ㅠㅠ 인생 영화
생각보다 굉장히 재미있는 뻔한 결말도 아니고 아름다운 음악과 현실적인 스토리구성 모두에게 와닿을법한 울림들이 차 좋았어요 추천
남자친구랑 봤는데 진짜 다시 보고싶음 ㅠㅠㅠ너무 좋았어요 재즈좋아하고 뮤지컬같은거 좋아하는사람들한텐 취저영화
인생영화 노래 연기 내용 연출이 다 엄청났다 ㅠㅠ 꿈을 위해 노력하고있는 사람에게 도움이 많이 될것같다
음악과 영상미 모두좋았습니다 특히 마지막 10분은 가히압권이였습니다 이런좋은영화 많이보았으면좋겠네요 ㅎㅎ
처음 써보는 영화에대한 평점 음악부터 연기 배경 그리고 색감 모든게 마음에 들었으며 나의 인생영화가된 영화
마지막 회상신에서 눈물이 왈칵 쏟아질뻔했다 올해중 최고의 영화를 본거 같다음악이며 배우들이며 영상이며 다시 또 보고싶은 그런 영화이다
보는 내내 두근두근 어느 순간도 눈을 뗄수 없는 환상적인 영상과 음악 현실성 높은 스토리에 배우들의 멋진 연기까지 행복한 영화였어요
마지막 장면에서 라이언고슬링의 피아노 연주와 엠마스톤의 눈빛연기 그리고 두 사람이 함께 했다면 어땠을까 하는 상상씬에서의 연출이 인상적이었다
정말 여자들이 좋아할 영화에요 영상이나 ost가 정말 예술이에요 배우들의 노래도 하나하나 다 좋았어요 마지막에 스토리가 좀 아쉽긴 하지만
그리고 핵심 문장을 추출하는 함수와 비슷하게 이용할 수 있도록 키워드만을 선택하는 과정을 간단히 summarize_with_keywords 함수로 정리하였습니다. 여기에도 stopwords 제거 기능이 포함되어 있습니다. 그 외에는 KR-WordRank 클래스의 사용법과 같습니다.
from krwordrank.word import summarize_with_keywords
keywords = summarize_with_keywords(texts, min_count=5, max_length=10,
beta=0.85, max_iter=10, stopwords=stopwords, verbose=True)
keywords = summarize_with_keywords(texts)
Performance evaluation
핵심 문장을 선택하는 기능을 만들고나니 한 가지 확인하고 싶은 점이 있었습니다. 앞서 언급한 것처럼 TextRank 에 의하여 선택되는 핵심 문장은 각 문장이 다양한 관점을 포함되도록 유도되지 않습니다. 그리고 KR-WordRank 는 이왕 선택되는 문장들이 각자 최대한 다양한 키워드를 포함하도록 유도하고 있습니다. 실제로 KR-WordRank 에 의하여 선택된 핵심 문장은 다양한 종류의 키워드를 포함하고 있는지 확인하고 싶어졌습니다. 제가 생각하는 좋은 핵심 문장이란, 앞서 정의한 것처럼 문서 집합 내에서 키워드로 선택된 단어를 많이 포함하는 문장이기 때문입니다.
이는 근본적으로 요약문의 품질을 측정하는 문제입니다. 하지만 요약문의 품질을 측정하기 위해서는 신뢰도가 높은 척도도 없을 뿐더러 심지어 정답 핵심 문장도 없습니다. 물론 competition 용 데이터가 있기는 하지만 이는 영어 텍스트 데이터입니다. 그리고 실제로 핵심 문장을 추출하는 많은 경우에 정답 핵심 문장을 매번 구축할 수도 없는 노릇입니다. (아쉽긴 하지만) 이 때 고려한 방법이 ROUGE 와 키워드를 이용한 핵심 문장의 품질 평가 방법입니다.
ROUGE
ROUGE-N 는 문서 요약 (summarization) 분야에서 자주 이용되는 성능 평가 척도입니다. ROGUE-N 은 reference summaries 와 system summaries 간의 n-gram recall 을 성능 평가 척도로 이용합니다.
예를 들어 아래의 문장이 한 문서의 요약문이라고 가정합니다.
the cat was under the bed
그리고 아래의 문장이 시스템에 의하여 추출된 핵심 문장이라고 가정합니다.
the cat was found under the bed
추출된 핵심 문장이 좋은 문장이라면, 정답 요약 문장의 단어들을 많이 포함해야 합니다. ROGUE-1 은 unigram 에서의 recall 값입니다. 추출된 문장에는 정답 요약 문장의 모든 단어가 포함되어 있기 때문에 recall = 1 입니다. ROGUE-2 는 bigram 에서의 recall 값입니다. 아래는 정답 문장에서의 bigrams 입니다.
the cat
cat was
was under
under the
the bed
아래는 추출된 핵심 문장에서의 bigrams 입니다.
the cat
cat was
was found
found under
under the
the bed
‘was under’ 라는 bigram 이 recall 되지 않았기 때문에 recall = 4/5 입니다.
물론 ROGUE measurement 는 그 성능의 신뢰성에 대해 고민할 부분이 많기는 하지만, 그 외에 이용할 수 있는 적절한 성능 평가 지표가 많지 않습니다. 그렇기 때문에 이번 실험에서도 ROGUE 를 이용하였습니다.
Performance
하지만 한 가지 문제가 더 발생합니다. 적절한 정답 문장을 만들 수가 없습니다. 그래서 생각한 방법은 각각의 알고리즘이 추출한 핵심 단어를 references 로 이용하는 것입니다. 알고리즘이 추출한 핵심 단어 집합을 좋은 summarization keywords 라 가정할 때, 추출된 핵심 문장들은 이 키워드들을 다수 포함해야 합니다. 그리고 KR-WordRank 나 TextRank 는 일반적으로 unigram extraction 을 하기 때문에 ROUGE-1 을 이용하였습니다.
TextRank 를 이용하여 핵심 문장을 추출하기 위해서는 토크나이저가 필요합니다. 이를 위해 KoNLPy 의 Komoran 을 이용하였습니다. 또한 문장 간 유사도 척도로 TextRank 에서 제안된 척도와 Cosine similarity 를 모두 이용했습니다. 아래는 각각의 알고리즘 별로 선택된 5 개의 핵심 문장들입니다. Cosine 을 이용한 경우에는 대체로 짧은 문장들이 선택되는 경향이 있습니다. 이는 앞서 TextRank 포스트에서 그 이유를 설명하였습니다.
| KR-WordRank 의 핵심 문장 5 개 |
|---|
| 여운이 크게남는영화 엠마스톤 너무 사랑스럽고 라이언고슬링 남자가봐도 정말 매력적인 배우인듯 영상미 음악 연기 구성 전부 좋았고 마지막 엔딩까지 신선하면서 애틋하구요 30중반에 감정이 많이 메말라있었는데 오랜만에 가슴이 촉촉해지네요 |
| 영상미도 너무 아름답고 신나는 음악도 좋았다 마지막 세바스찬과 미아의 눈빛교환은 정말 마음 아팠음 영화관에 고딩들이 엄청 많던데 고딩들은 영화 내용 이해를 못하더라ㅡㅡ사랑을 깊게 해본 사람이라면 누구나 느껴볼수있는 먹먹함이 있다 |
| 정말 영상미랑 음악은 최고였다 그리고 신선했다 음악이 너무 멋있어서 연기를 봐야 할지 노래를 들어야 할지 모를 정도로 그리고 보고 나서 생각 좀 많아진 영화 정말 이 연말에 보기 좋은 영화 인 것 같다 |
| 무언의 마지막 피아노연주 완전 슬픔ㅠ보는이들에게 꿈을 상기시켜줄듯 또 보고 싶은 내생에 최고의 뮤지컬영화였음 단순할수 있는 내용에 뮤지컬을 가미시켜째즈음악과 춤으로 지루할틈없이 빠져서봄 ost너무좋았음 |
| 처음엔 초딩들 보는 그냥 그런영화인줄 알았는데 정말로 눈과 귀가 즐거운 영화였습니다 어찌보면 뻔한 스토리일지 몰라도 그냥 보고 듣는게 즐거운 그러다가 정말 마지막엔 너무 아름답고 슬픈 음악이 되어버린 |
| TextRank 의 핵심 문장 5 개 |
|---|
| 시사회 보고 왔어요 꿈과 사랑에 관한 이야기인데 뭔가 진한 여운이 남는 영화예요 |
| 시사회 갔다왔어요 제가 라이언고슬링팬이라서 하는말이아니고 너무 재밌어요 꿈과 현실이 잘 보여지는영화 사랑스런 영화 전 개봉하면 또 볼생각입니당 |
| 황홀하고 따뜻한 꿈이었어요 imax로 또 보려합니다 좋은 영화 시사해주셔서 감사해요 |
| 시사회에서 보고왔는데 여운쩔었다 엠마스톤과 라이언 고슬링의 케미가 도입부의 강렬한음악좋았고 예고편에 나왓던 오디션 노래 감동적이어서 눈물나왔다ㅠ 이영화는 위플래쉬처럼 꼭 영화관에봐야함 색감 노래 배우 환상적인 영화 |
| 방금 시사회로 봤는데 인생영화 하나 또 탄생했네 롱테이크 촬영이 예술 영상이 넘나 아름답고 라이언고슬링의 멋진 피아노 연주 엠마스톤과의 춤과 노래 눈과 귀가 호강한다 재미를 기대하면 약간 실망할수도 있지만 충분히 훌륭한 영화 |
| TextRank + Cosine 의 핵심 문장 5 개 |
|---|
| 좋다 좋다 정말 너무 좋다 그 말 밖엔 인생영화 등극 ㅠㅠ |
| 음악도 좋고 다 좋고 좋고좋고 다 좋고 씁쓸한 결말 뭔가 아쉽다 |
| 제 인생영화 등극이네요 끝나기 전쯤에는 그냥 훌륭한 뮤지컬영화다 라고 생각했는데 마지막에 감독의 메시지가 집약된 화려한 엔딩에서 와 인생영화다 라는생각밖에 안들었네요 개봉하고 2번은 더 보러갈겁니다 |
| 이거 2번보고 3번 보세요 진짜 최고입니다 |
| 너무 아름다운 영화였어요 ㅎ |
Reference summaries 로 키워드를 이용할 경우에도 키워드의 개수 및 핵심 문장의 개수를 사용자가 지정해야 하며, 이에 따라 ROUGE-1 값이 달라질 수 있습니다. 그렇기 때문에 아래처럼 키워드의 개수 및 핵심 문장의 개수를 다양하게 조절하며 각각 ROUGE-1 성능을 측정하였습니다.
그 결과 언제나 KR-WordRank 에 의하여 선택된 핵심 문장들이 다른 방법에 의하여 선택된 핵심 문장들보다 다양한 키워드를 포함하고 있습니다. 그리고 Cosine similarity 를 문장 간 유사도로 이용한 경우에는 매우 적은 수의 키워드를 포함하는 것을 확인할 수 있습니다. 이는 TextRank + Cosine similarity 로 선택된 핵심 문장들은 짧을 뿐 아니라, 키워드도 제대로 포함하고 있지 못한다는 의미입니다.
이 실험은 KR-WordRank 에 유리한 방향으로 설계되었습니다. 정확히 표현하면, 제가 생각하는 핵심 문장의 조건을 TextRank 에서는 고려하지 않았고, KR-WordRank 에는 그 조건이 구현되어 있습니다. 그러니 아래의 성능 표는 TextRank 에서 고려하지 못한 조건이 KR-WordRank 의 핵심 문장 추출 과정에서는 의도한대로 고려되며 작동한다고 해석하는 것이 옳습니다.
꼭 KR-WordRank 에서 핵심 문장 선택 기능을 추가하고 싶었는데, 드디어 이 기능을 추가함과 동시에 좋은 핵심 문장의 조건에 대해서도 고민할 수 있었습니다.
| # keywords | # keysents | KR-WordRank | TextRank | TextRank + Cosine |
|---|---|---|---|---|
| 10 | 3 | 0.8 | 0.6 | 0.4 |
| 10 | 5 | 1.0 | 0.7 | 0.5 |
| 10 | 10 | 1.0 | 1.0 | 0.5 |
| 10 | 20 | 1.0 | 1.0 | 0.5 |
| 10 | 30 | 1.0 | 1.0 | 0.7 |
| 20 | 3 | 0.7 | 0.5 | 0.35 |
| 20 | 5 | 0.9 | 0.65 | 0.45 |
| 20 | 10 | 0.95 | 0.9 | 0.45 |
| 20 | 20 | 1.0 | 1.0 | 0.45 |
| 20 | 30 | 1.0 | 1.0 | 0.55 |
| 30 | 3 | 0.5 | 0.4 | 0.3333 |
| 30 | 5 | 0.7 | 0.5 | 0.4333 |
| 30 | 10 | 0.8667 | 0.7667 | 0.4333 |
| 30 | 20 | 0.9667 | 0.9667 | 0.4667 |
| 30 | 30 | 1.0 | 0.9667 | 0.5667 |
| 50 | 3 | 0.44 | 0.28 | 0.3 |
| 50 | 5 | 0.58 | 0.4 | 0.38 |
| 50 | 10 | 0.74 | 0.6 | 0.38 |
| 50 | 20 | 0.96 | 0.82 | 0.4 |
| 50 | 30 | 0.98 | 0.88 | 0.48 |
| 100 | 3 | 0.3 | 0.2 | 0.23 |
| 100 | 5 | 0.42 | 0.29 | 0.27 |
| 100 | 10 | 0.59 | 0.46 | 0.28 |
| 100 | 20 | 0.78 | 0.67 | 0.32 |
| 100 | 30 | 0.86 | 0.78 | 0.38 |