PageRank 나 HITS 같은 graph ranking 알고리즘은 natural language processing 에서 이용되기도 합니다. WordRank 는 일본어와 중국어의 unsupervised word segmentation 을 위하여 제안된 방법입니다. 하지만 이 알고리즘을 한국어에 그대로 적용하기는 어렵습니다. 한국어와 일본어, 중국어는 언어적 특성이 다릅니다. KR-WordRank 는 한국어의 특징을 반영하여 비지도학습 기반으로 한국어의 단어를 추출합니다. 그리고 단어 점수는 키워드 점수로 이용될 수도 있습니다. 즉, KR-WordRank 는 토크나이저를 이용하지 않으면서도 단어/키워드 추출을 비지도학습 기반으로 수행합니다.
Brief review of HITS
PageRank 와 HITS 는 비슷한 시기에, 비슷한 아이디어로, 비슷한 문제를 해결하였습니다. HITS 의 아이디어는 “중요한 웹페이지는 좋은 웹페이지로부터 링크를 많이 받은 페이지이고, 각 페이지의 authority 는 중요한 웹페이지로부터의 링크가 많을수록 높다” 입니다. 이 아이디어를 그대로 공식으로 표현하였습니다.
마디 p 의 hub score 는 backlinks 의 출발 마디인 q 의 authority score 의 합입니다. 마디 p 의 authotiry score 는 backlinks 의 출발 마디인 q 의 hub score 의 합입니다. 이 식을 hub and authority score 가 수렴할 때 까지 반복합니다. 초기화는 모든 마디에 같은 값을 hub and authority score 로 설정합니다.
\[hub(p) = \sum_{q:(q \rightarrow p)} authority(q)\] \[authority(p) = \sum_{q:(q \rightarrow p)} hub(q)\]이는 PageRank 의 아이디어와도 비슷합니다. PageRank 는 중요한 web pages 로부터 많은 backlinks 를 받을수록 그 페이지도 중요한 web pages 라 가정합니다. PageRank 와 HITS 모두 각 마디의 중요성을 다른 마디와의 관계식으로 표현합니다.
두 알고리즘의 차이점 중 하나는, PageRank 는 아래처럼 각 페이지의 랭크를 링크의 개수만큼 나눠서 연결된 페이지로 보내주는 반면, HITS 는 점수가 복제되어 링크된 페이지로 전달됩니다. 그리고 점수의 총합을 유지하기 위하여 normalize 를 합니다.
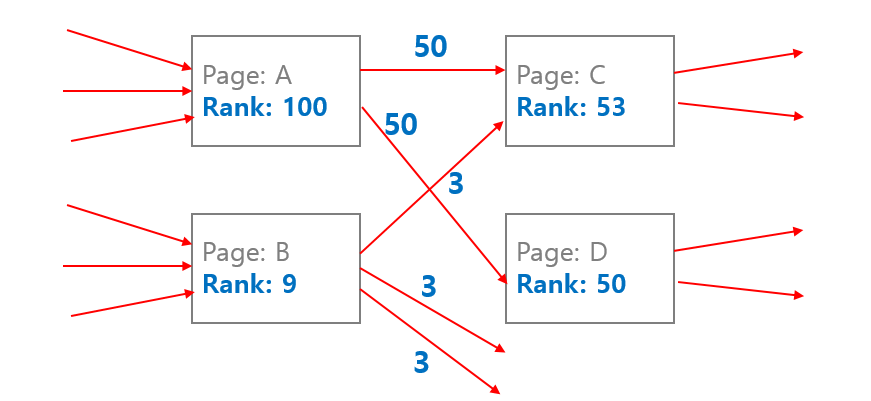
더 자세한 내용은 PageRankd and HITS post 를 참고하세요.
WordRank
WordRank 는 띄어쓰기가 없는 중국어와 일본어에서 graph ranking 알고리즘을 이용하여 단어를 추출하기 위해 제안된 방법입니다. Ranks 는 substring 의 단어 가능 점수이며, 이를 이용하여 unsupervised word segmentation 을 수행하였습니다.
WordRank 는 substring graph 를 만든 뒤, graph ranking 알고리즘을 학습합니다. Substring graph 는 아래 그림의 (a), (b) 처럼 구성됩니다.
먼저 문장에서 띄어쓰기가 포함되지 않은 모든 substring 의 빈도수를 계산합니다. 이때 빈도수가 같으면서 짧은 substring 이 긴 substring 에 포함된다면 이를 제거합니다. 아래 그림에서 ‘seet’ 의 빈도수가 2 이고, ‘seeth’ 의 빈도수가 2 이기 때문에 ‘seet’ 는 graph node 후보에서 제외됩니다.
두번째 단계는 모든 substring nodes 에 대하여 links 를 구성합니다. ‘that’ 옆에 ‘see’와 ‘dog’ 이 있었으므로 두 마디를 연결합니다. 왼쪽에 위치한 subsrting 과 오른쪽에 위치한 subsrting 의 edge 는 서로 다른 종류로 표시합니다. 이때, ‘do’ 역시 ‘that’의 오른쪽에 등장하였으므로 링크를 추가합니다.
이렇게 구성된 subsrting graph 에 HITS 알고리즘을 적용하여 각 subsrting 의 ranking 을 계산합니다.
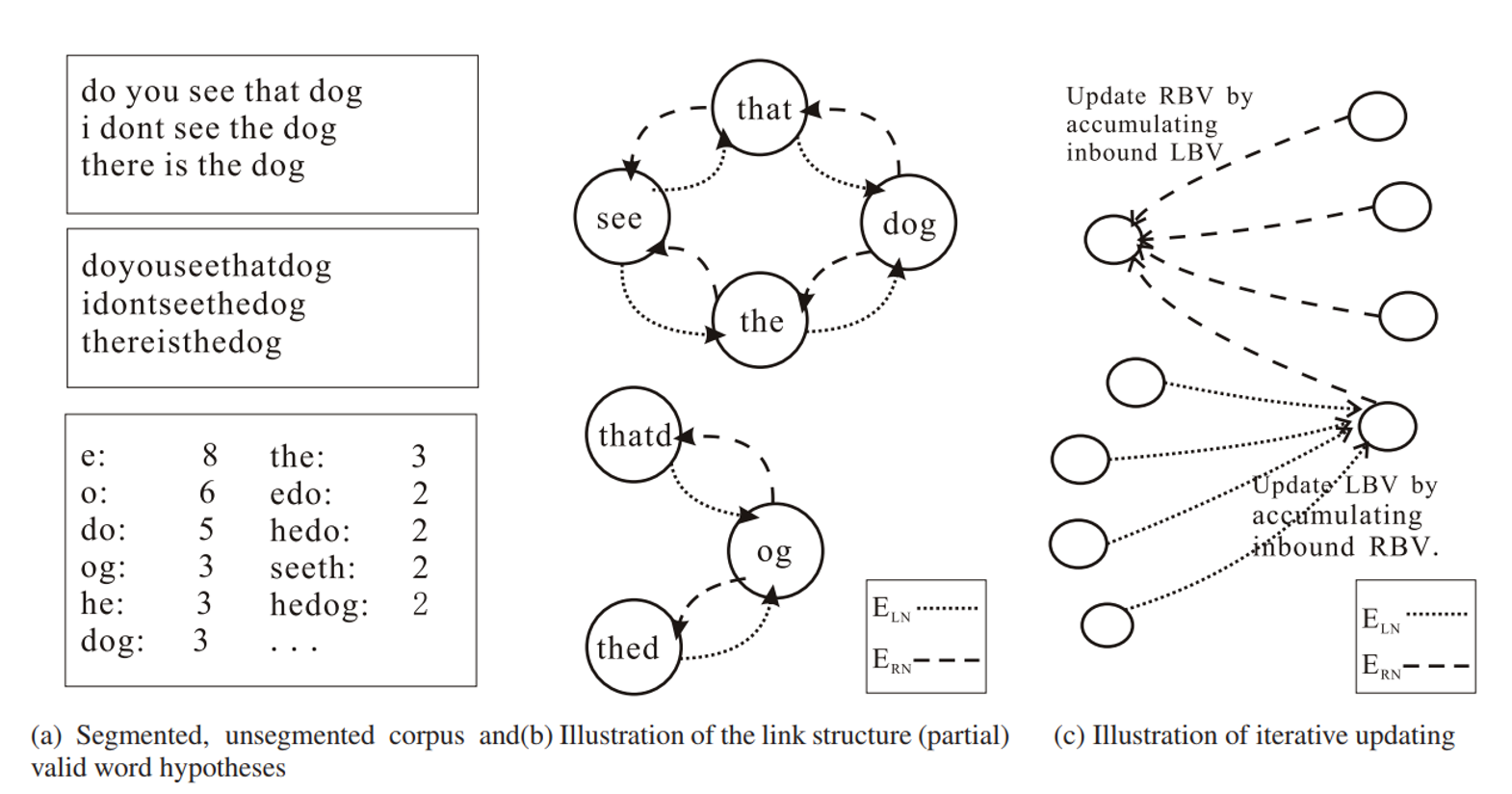
WordRank 의 가설은 HITS 와 비슷합니다. 단어의 좌/우에는 단어가 등장하고, 단어가 아닌 substring 좌/우에는 단어가 아닌 substring 이 등장합니다. 단어는 다른 많은 단어들과 연결되기 때문에 질 좋은 links 가 많이 연결되며, 단어가 아닌 substring 은 소수의 backlinks 를 받습니다. 그마저도 단어가 아닌 substring 으로부터 출발한 links 입니다. Ranking update 를 하면, 단어들은 rank 가 높아집니다.
한 subsrting 의 왼쪽이 단어의 경계일 점수는 왼쪽에 위치한 subsrtings 의 오른쪽 단어 경계 점수의 합으로, 한 subsrting 의 오른쪽이 단어의 경계일 점수는 오른쪽에 위치한 subsrting 의 왼쪽 단어 경계 점수의 합으로 표현됩니다. 왼쪽이 단어 경계라면 같은 경계를 마주한 다른 단어의 오른쪽 단어 경계 점수가 높아야 하기 때문입니다. 이는 HITS 처럼 아래의 식으로 표현할 수 있습니다. \(lbv(s)\) 는 substring \(s\) 의 left boundary value 이며, \(L(s)\) 는 \(s\) 의 왼쪽에 위치한 substrings 집합입니다.
- \[lbv(s) = \sum_{a \in L(s)} rbv(a)\]
- \[rbv(s) = \sum_{a \in R(s)} lbv(a)\]
WordRank 를 한국어 데이터에 적용하였습니다. 이를 위하여 원빈 주연의 한국 영화 ‘아저씨’의 사용자 영화평 데이터를 이용하였습니다.
WordRank 알고리즘을 한국어에 그대로 적용하는데는 무리가 있습니다. 한국어 데이터에 WordRank 를 적용하면 한 글자들이 높은 ranking 을 지닙니다. 한국어의 한글자는 그 자체로 단어이기도 하며, 관형사나 조사로 이용되는 글자들이 많아 단어로 등장합니다.
| 이 (14448) | 나 (4069) | 점 (2893) |
| 영화 (10559) | 말 (4501) | 인 (3948) |
| 다 (14351) | 기 (4988) | 그 (2830) |
| 원빈 (9248) | 화 (11114) | 시 (2437) |
| 액션 (3767) | 의 (4621) | 전 (1989) |
| 정말 (2783) | 대박 (2009) | 감동 (1109) |
| 도 (5684) | 연기 (2460) | 무 (2588) |
| 한 (7061) | 어 (4585) | 보 (5782) |
| 만 (6004) | 요 (6073) | 원 (9855) |
| 가 (5036) | 로 (3066) | 스토리 (1022) |
| 아 (5769) | 너무 (1860) | 완전 (1074) |
| 최고 (4255) | 대 (4137) | 감 (2388) |
| 고 (11221) | 아저씨 (1281) | 원빈의 (1390) |
| 는 (8919) | 은 (3812) | 한국영화 (1041) |
| 에 (5386) | 진 (3331) | 원빈이 (1078) |
| 지 (6908) | 정 (3962) | 라 (2474) |
| 진짜 (2105) | 내 (2145) | 하 (5565) |
한글자 단어를 제거하여 살펴보면 ‘-지만’, ‘-네요’와 같은 suffix 들이 높은 rank 를 받습니다. 어근이나 명사들의 종류가 조사나 어미보다 다양하여 조사나 어미의 ranking 이 상대적으로 높습니다.
또한 ‘영화’, ‘원빈’이 높은 ranking 을 받음에도 ‘원빈이’, ‘원빈의’, ‘영화가’ 등의 어절도 높은 ranking 을 받습니다. 중복된 정보가 출력됩니다.
| 영화 (10559) | 하지만 (718) | 액션이 (357) |
| 원빈 (9248) | 지만 (1995) | 영화는 (433) |
| 액션 (3767) | 그냥 (789) | 원빈은 (432) |
| 정말 (2783) | 네요 (1670) | 영화가 (465) |
| 최고 (4255) | 하고 (960) | 잔인 (1608) |
| 진짜 (2105) | 평점 (1245) | 최고의 (842) |
| 대박 (2009) | 테이큰 (753) | 간만에 (331) |
| 연기 (2460) | 한국 (1868) | 까지 (521) |
| 너무 (1860) | 이영화 (504) | 연기력 (437) |
| 아저씨 (1281) | 최고의영화 (519) | 처음 (676) |
| 감동 (1109) | 에서 (753) | 오랜만에 (337) |
| 스토리 (1022) | 배우 (685) | 봤는데 (398) |
| 완전 (1074) | 내용 (566) | 최고다 (407) |
| 원빈의 (1390) | 이런 (573) | 이다 (687) |
| 한국영화 (1041) | 보다 (578) | 입니다 (566) |
| 원빈이 (1078) | 으로 (987) | 재미 (1283) |
| 보고 (1875) | 액션영화 (505) | 근데 (208) |
KR-WordRank
WordRank 를 한국어 데이터에 그대로 적용하는 것은 무리가 있습니다. WordRank 는 중국어와 일본어에 적용하기 위하여 개발된 알고리즘이기 때문입니다. 언어적 특징이 다르니, 그 특징을 잘 이용해야 합니다.
한국어는 띄어쓰기 정보를 이용해야 합니다. 띄어쓰기 정보를 이용하지 않으면 두 어절의 양끝에 걸친 substring 역시 단어 후보에 포함됩니다. 띄어쓰기로 구분되는 ‘번봄’은 subsrting graph 에 추가할 필요가 없습니다. 물론 띄어쓰기 오류가 일부 존재하여 ‘번봄’이 마디에 포함될 수 있습니다. 하지만 그 빈도는 매우 작기 때문에 ranking 이 매우 낮게 계산될 겁니다.
substring('이번봄에는') = [이번, 번봄, 봄에, 에는, 이번봄, 번봄에, ...]
subsrting('이번 봄에는') = [이번, 봄에, 에는, 봄에는]
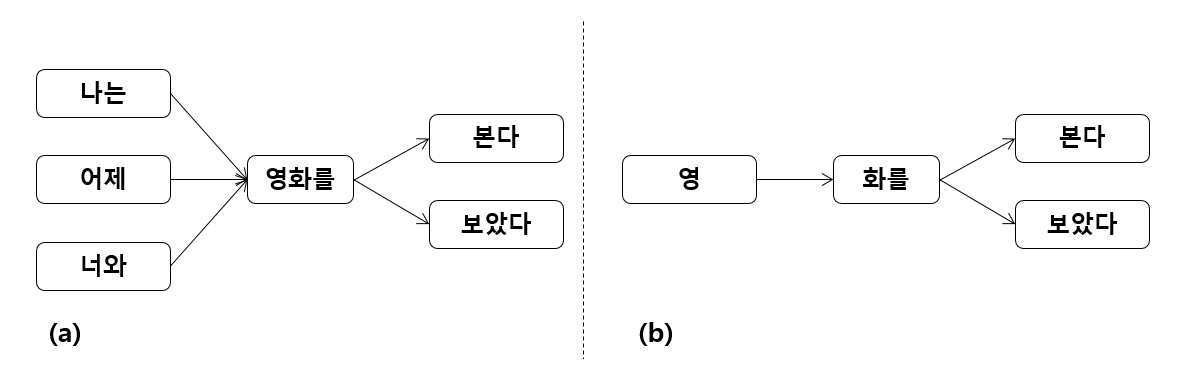
한국어 어절 구조의 특징인 L + [R] 을 이용해야 합니다. 어절의 왼쪽에 위치한 글자들이 의미를 지니는 단어들이며, 오른쪽에 위치한 글자들은 문법기능을 하는 조사와 어미입니다. 우리가 단어 사전으로 만들고 싶은 단어들은 L parts 입니다.
더하여 WordRank 알고리즘은 keyword extraction 능력이 있습니다. Substring graph 에서 ranking 이 높은 마디는 단어일 뿐 아니라, 그 데이터셋에서 자주 등장하는 단어입니다. 데이터를 요약하는 keywords 로 이용될 수 있습니다.
KR-WordRank 는 이러한 성질을 바탕으로 unsupervised Korean keyword extraction 을 수행합니다.
KR-WordRank 역시 WordRank 와 같은 가정을 합니다. 단어의 좌/우에 등장하는 subsrting 은 단어일 것이며, 단어가 아닌 subsrtings 은 단어가 아닌 subsrtings 와 연결됩니다.
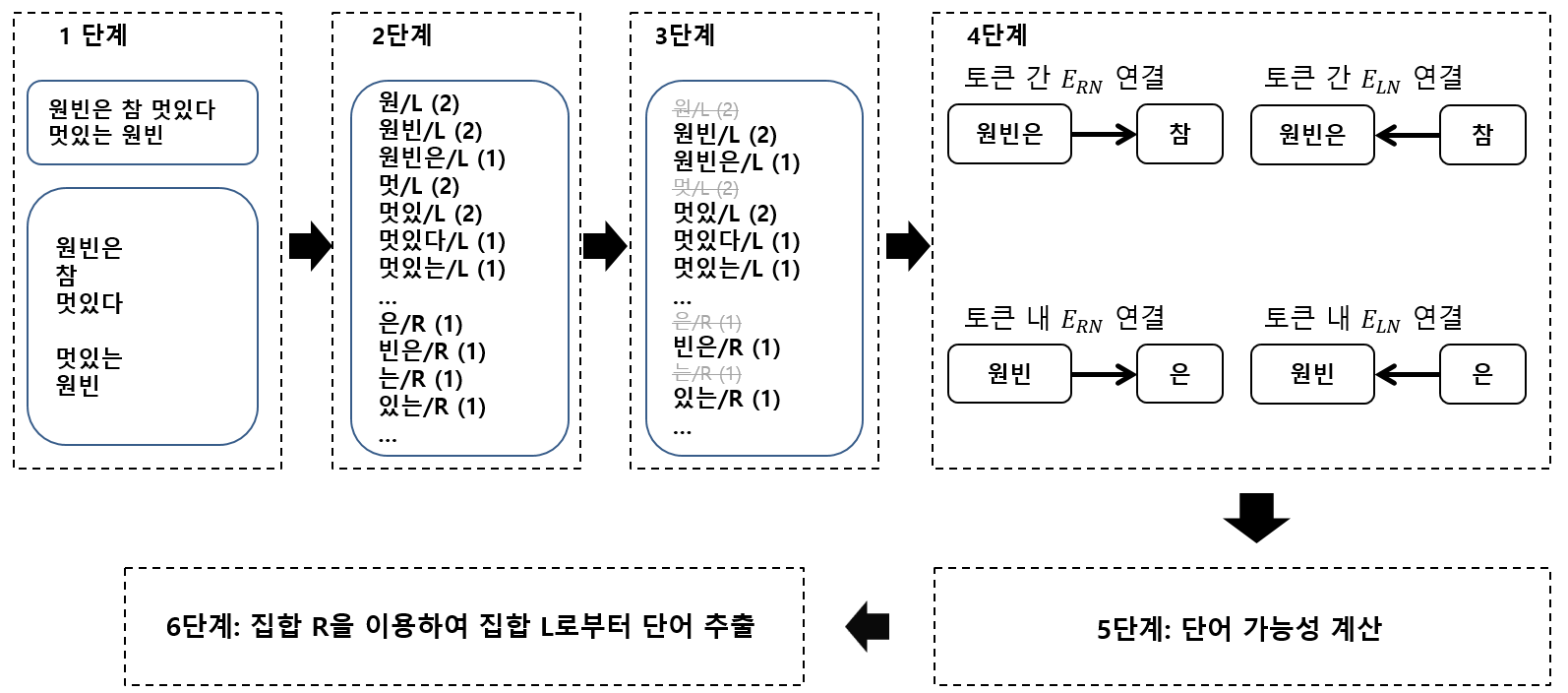
KR-WordRank 의 학습 과정은 WordRank 과정과 조금 다릅니다. 첫 단계는 substring frequency counting 입니다. 빈도수를 계산할 substrings 은 어절의 왼쪽에 위치하거나 (어절 전체는 어절 왼쪽에 위치하는 것으로 간주합니다), 어절의 오른쪽에 위치한 subsrting 입니다. 그리고 각각의 position 을 L과 R로 구분합니다.
3 단계에서 가능한 모든 subsrting 의 빈도수를 계산하고, 같은 position 이면서 빈도수가 같은 subsrtings 은 제거합니다.
4 단계에서는 subsrtings 간의 링크를 만듭니다. 어절 내 L 과 R 와 어절 간 링크를 구성합니다.
5 단계에서 graph ranking 을 학습하고, 6 단계에서 후처리를 진행합니다. 5 단계의 결과 영화 ‘아저씨’의 리뷰에서는 ‘원빈/L’과 ,원빈은/L’ 모두 높은 ranking 을 가집니다. 상위 rank 를 지닌 R 은 조사나 어미일 가능성이 높습니다. top k (약 300개) 의 상위 rank R 을 suffix set 으로 선택합니다. 그 뒤, rank 기준으로 L 을 필터링합니다.
‘원빈/L’, ‘원빈은/L’, ‘원빈이/L’, ‘아저씨/L’ 순서로 ranking 을 지니고 ‘은/R’, ‘이/R’ 이 suffix set 에 포함되어 있다면, ranking 이 높은 순서대로 L 을 확인합니다. 필터링의 첫 시작은 ranking 이 가장 높은 단어를 filtered set 에 추가하는 것입니다. ‘원빈/L’이 filtered set 에 추가되었습니다. 그 다음부터는 L 이 이미 filtered set 에 포함된 L 과 suffix set 으로 조합되는지 확인합니다. ‘원빈은/L = 원빈/L + 은/R’ 이므로 filtered set 에 추가하지 않습니다. ‘원빈이/L = 원빈/L + 이/R’ 이므로 filtered set 에 추가하지 않습니다. 하지만 ‘아저씨/L’는 filtered set + suffix set 으로 조합할 수 없기 때문에 filtered set 에 추가합니다.
필터링을 하기 전 상위 랭크의 L parts 는 아래와 같습니다. ‘영화’, ‘영화가’, ‘영화는’ 이 중복적으로 추출되었습니다.
| 영화 (10559) | 그냥 (789) | 처음 (676) |
| 원빈 (9243) | 평점 (1245) | 연기력 (437) |
| 정말 (2783) | 테이큰 (753) | 이렇게 (345) |
| 액션 (3766) | 본 (1441) | 잔인 (1608) |
| 최고 (4251) | 굿 (578) | 간만에 (330) |
| 진짜 (2105) | 좀 (557) | 강추 (445) |
| 대박 (1988) | 한국 (1867) | 재미 (1283) |
| 너무 (1859) | 이런 (573) | 봤는데 (398) |
| 연기 (2460) | 또 (966) | 오랜만에 (334) |
| 아저씨 (1280) | 원빈은 (432) | 근데 (208) |
| 완전 (1073) | 액션이 (346) | 액션영화 (401) |
| 원빈의 (1387) | 영화는 (433) | 재밌다 (285) |
| 감동 (1109) | 영화가 (459) | 멋있다 (376) |
| 원빈이 (1025) | 최고다 (393) | 영화를 (452) |
| 스토리 (1022) | 배우 (685) | 액션은 (215) |
| 보고 (1875) | 내용 (566) | 그리고 (177) |
| 한국영화 (944) | 최고의 (842) | 멋진 (399) |
중복된 substrings 을 제거하면 서로 다른 의미의 L parts 가 영화 ‘아저씨’의 리뷰 중에서 높은 점수를 지닌 단어로 선택됩니다. 즉 영화 ‘아저씨’의 키워드입니다.
| 영화 (10559) | 테이큰 (753) | 오랜만에 (334) |
| 원빈 (9243) | 본 (1441) | 근데 (208) |
| 정말 (2783) | 굿 (578) | 액션영화 (401) |
| 액션 (3766) | 좀 (557) | 재밌다 (285) |
| 최고 (4251) | 한국 (1867) | 멋있다 (376) |
| 진짜 (2105) | 이런 (573) | 그리고 (177) |
| 대박 (1988) | 또 (966) | 멋진 (399) |
| 너무 (1859) | 배우 (685) | 보는 (552) |
| 연기 (2460) | 내용 (566) | 왜 (304) |
| 아저씨 (1280) | 처음 (676) | 이영화 (252) |
| 완전 (1073) | 연기력 (437) | 역시 (220) |
| 감동 (1109) | 이렇게 (345) | 레옹 (391) |
| 스토리 (1022) | 잔인 (1608) | 남자 (757) |
| 보고 (1875) | 간만에 (330) | 솔직히 (208) |
| 한국영화 (944) | 강추 (445) | 하나 (340) |
| 그냥 (789) | 재미 (1283) | 많이 (261) |
| 평점 (1245) | 봤는데 (398) | 참 (198) |
Softwards
KR-WordRank 는 github/lovit/kr-wordrank 에 구현체를 올려두었습니다. 영화 ‘라라랜드’의 영화평도 샘플데이터로 함께 올려두었습니다.
설치는 git clone 과 pip 으로 할 수 있습니다.
pip install krwordrank
Input data 는 list of str 형식입니다. normalize 함수는 불필요한 특수기호를 제거하는 전처리 함수입니다. english=True, number=True 를 입력하면 한글, 영어, 숫자를 제외한 다른 글자를 제거합니다. Default 는 english=False, number=False 입니다.
from krwordrank.hangle import normalize
texts = ['이것은 예문입니다', '각자의 데이터를 준비하세요', ... ]
texts = [normalize(text, english=True, number=True) for text in texts]학습은 KRWordRank 를 생성한 뒤, extract() 함수에 input 을 입력합니다. Beta 는 PageRank 의 damping factor 이며, default 는 0.85 입니다.
from krwordrank.word import KRWordRank
wordrank_extractor = KRWordRank(
min_count = 5, # 단어의 최소 출현 빈도수 (그래프 생성 시)
max_length = 10, # 단어의 최대 길이
verbose = True
)
beta = 0.85 # PageRank의 decaying factor beta
max_iter = 10
keywords, rank, graph = wordrank_extractor.extract(texts, beta, max_iter)Return 은 keywors, rank, graph 세 가지 입니다. Keywords 는 filtering 이 적용된 L parts 이며, rank 는 substring graph 의 모든 subsrting 에 대한 rank 입니다. 둘 모두 dict 형식입니다. graph 는 substring graph 입니다.
라라랜드 영화평을 적용한 결과, 이 영화의 키워드는 ‘음악, 사랑, 뮤지컬, 꿈’ 등입니다. 우리가 생각하는 라라랜드의 평과 일치합니다.
for word, r in sorted(keywords.items(), key=lambda x:x[1], reverse=True)[:30]:
print('%8s:\t%.4f' % (word, r))키워드 rank
---------------
영화: 229.7889
관람객: 112.3404
너무: 78.4055
음악: 37.6247
정말: 37.2504
마지막: 34.9952
최고: 22.4425
사랑: 21.1355
뮤지컬: 20.7357
꿈을: 19.5282
여운이: 19.4032
보고: 19.4005
아름: 18.6495
진짜: 18.5599
영상: 18.1099
좋았: 17.8625
노래: 16.9019
스토리: 16.2600
좋은: 15.4661
그냥: 15.2136
현실: 15.0772
생각: 14.6264
인생: 14.2642
좋고: 13.9971
지루: 13.8732
다시: 13.7812
감동: 13.4817
느낌: 12.3127
ㅠㅠ: 12.1447
좋아: 11.9586
References
- Chen, S., Xu, Y., & Chang, H. (2011, August). A Simple and Effective Unsupervised Word Segmentation Approach. In AAAI.
- Kim, H. J., Cho, S., & Kang, P. (2014). KR-WordRank: An Unsupervised Korean Word Extraction Method Based on WordRank. Journal of Korean Institute of Industrial Engineers, 40(1), 18-33.