Doc2Vec 은 단어와 문서를 같은 임베딩 공간의 벡터로 표현하는 방법으로 알려져 있습니다. 하지만 대부분의 경우 단어와 문서는 공간을 나누어 임베딩 되는 경우가 많습니다. 그리고 단어 벡터와 문서 벡터 간의 상관성을 표현하는 그림을 그리기 위해서는 두 벡터 공간이 일치하는지를 반드시 따져봐야 합니다. 이번 포스트에서는 Doc2Vec 으로 학습한 문서와 단어 벡터를 2 차원의 그림으로 그리는 방법과 주의점에 대하여 알아봅니다. 이를 통하여 Doc2Vec 모델이 학습하는 공간에 대하여 이해할 수 있습니다.
Doc2Vec
Doc2Vec 은 Word2Vec 이 확장된 임베딩 방법입니다. Document id 를 모든 문맥에 등장하는 단어로 취급합니다. 예를 들어 ‘a little dog sit on the table’ 이란 문장에 해당하는 document id, #doc5 는 dog 의 문맥에도 [a, little, sit, on, #doc5] 로, sit 의 문맥에도 [little, dog, on, the, #doc5] 로 등장합니다. 결국 document id 에 해당하는 벡터는 해당 문서에 등장하는 모든 단어들과 가까워지는 방향으로 이동하여 아래의 그림과 같은 벡터를 지닙니다. 그렇기 때문에 두 문서에 등장한 단어가 다르더라도 단어의 벡터들이 비슷하다면 두 문서의 벡터는 서로 비슷해집니다.
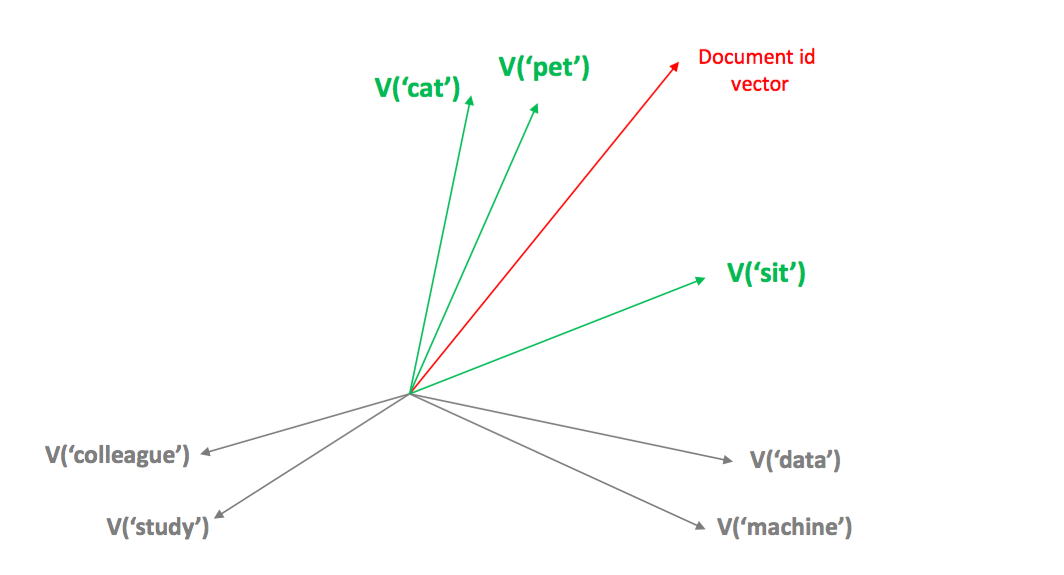
Document id 는 반드시 각 문서마다 서로 다르게 정의할 필요는 없습니다. 리뷰들을 기반으로 영화 벡터를 학습하고 싶다면 각 리뷰마다 해당하는 영화의 아이디를 document id 로 정의할 수도 있습니다. 이때는 한 영화에 대한 모든 리뷰들이 합쳐져 하나의 가상의 문서가 만들어지는 것과 같은 효과가 생깁니다. 이에 대한 더 자세한 이야기와 Word2Vec, Doc2Vec 설명은 이전 포스트를 참고하세요.
그리고 영화 “라라랜드” 의 벡터 근처에 “뮤지컬”이라는 단어가 위치하길 기대합니다. 혹은 영화 평점을 document id 로 학습한 뒤, “1점” 벡터 주변에는 “심한 욕”이, “10점” 벡터 주변에는 칭찬에 해당하는 단어가 위치하길 기대합니다. 하지만 실제로 영화평 데이터를 이용하여 Doc2Vec 을 학습하면 이러한 일은 발생하지 않습니다. 이번 포스트에서는 이에 대한 이유에 대해 알아보려 합니다.
문서와 단어는 서로 다른 공간에 임베딩 될 수 있다.
Word2Vec 은 단어의 앞, 뒤에 등장하는 context words 의 분포가 유사한 두 단어 \(w_1, w_2\) 가 서로 비슷한 벡터로 표현되도록 softmax regression 을 학습합니다. 앞서 설명한 것처럼 Doc2Vec 은 한 document id 에 해당하는 모든 문서에서 등장한 모든 단어가 context words 가 됩니다. 하지만 문서 \(d\) 의 context words와 단어 \(w\) 의 context words 는 분포가 매우 다릅니다. 이는 이전의 (Levy & Goldberg, 2014) 의 논문을 리뷰한 포스트에서 언급한 개념으로 생각하면 쉽습니다. Word2Vec 의 공간에서 두 단어 \(w_1, w_2\) 의 유사도는 각 단어의 context words 와의 co-occurrence 에 postive Point Mutual Information 을 적용한 벡터 간의 유사도와 같습니다. 즉, 해석을 위하여 context words 와의 co-occurrence vector 를 생각해보면 단어의 context words 벡터에는 실제로 앞, 뒤에 등장한 단어만 등장하지만, 문서의 context words에는 문맥과 상관없는 단어들도 다수 포함됩니다. 대체로 단어의 context words 벡터는 문서의 context words 벡터보다 훨씬 sparse 합니다. 그리고 이 벡터가 함께 Singular Value Decomposition 에 의하여 저차원 공간으로 치환됩니다. 이 공간을 Doc2Vec 공간으로 생각할 수 있습니다. 원 공간의 벡터가 서로 다르니 저차원 공간의 벡터도 서로 떨어져 있습니다.
이를 entity - descriptor 의 관계로 해석하면 단어 벡터는 문맥 공간에 위치하지만, 문서 벡터는 토픽 공간에 위치하는 것입니다. 이 두 공간이 서로 비슷한 경우는 단어와 문서의 context words 가 비슷한 경우, 즉 문서가 단어 분포가 비슷한 짧은 문장들로 이뤄졌거나, 문장에서 명사만 남겨 단어의 문맥 범위를 강제로 넓히는 경우입니다. 이 경우에도 짧은 문장으로 이뤄진 영화평 데이터에서 영화 아이디와 단어를 임베딩 하는 경우에는 효과가 있겠지만, 평점과 단어는 여전히 다른 공간에 존재합니다. 어떤 수단을 쓰더라도 평점의 context words 는 단어의 종류가 매우 다양할 것이기 때문입니다.
이를 확인해 보기 위해 영화평 데이터를 이용하여 Doc2Vec 을 학습합니다. 평점과 단어의 벡터를 모두 합하여 평점 별 가장 유사한 벡터가 무엇인지 상위 10 개를 검색해 봅니다. 결과는 아래처럼 대부분의 평점 벡터 주변에는 평점 벡터들이 위치합니다.
sim(#10) : #10, #9, #8, #7, #6, #5, ㅎㅎ잼있네용/NA, 사랑해ㅠㅠ/NA, things/SL, #4
sim(#8) : #8, #9, #7, #6, #10, #5, #4, #3, #2, ㅎㅎ잼있네용/NA
sim(#3) : #3, #4, #2, #5, #1, #6, #7, #8, OOㅋ배트맨/NA, #9
sim(#9) : #9, #8, #10, #7, #6, #5, #4, ㅎㅎ잼있네용/NA, #3, things/SL
sim(#6) : #6, #5, #7, #4, #3, #2, #8, #1, #9, #10
sim(#7) : #7, #6, #8, #5, #9, #4, #3, #2, #10, #1
sim(#2) : #2, #3, #4, #1, #5, #6, #7, #8, OOㅋ배트맨/NA, ㅎㅇㅎㅇ/NA
sim(#4) : #4, #3, #5, #2, #6, #1, #7, #8, #9, OOㅋ배트맨/NA
sim(#5) : #5, #4, #6, #3, #2, #7, #1, #8, #9, #10
이러한 현상은 영화 아이디를 document id 로 이용하여도 동일합니다. 영화 ‘라라랜드’의 아이디 주변 30 개의 벡터 중 28 개는 다른 영화 아이디였습니다. 이처럼 애초에 단어와 문서는 서로 공간이 나뉘어져 있습니다.
t-SNE 는 원 공간을 왜곡한다.
시각화의 목적으로 고차원 벡터를 2 차원으로 변화하기 위하여 가장 많이 이용하는 알고리즘은 아마도 t-SNE 일 것입니다. 그러나 t-SNE 는 원 공간의 밀도를 잘 반영하지 못하는 단점이 있습니다. t-SNE 는 밀도가 높은 공간의 점들을 서로 떨어트리고, 밀도가 낮은 공간의 점들은 서로 가까이 붙여서 2 차원 공간의 점으로 변환합니다. 2 차원 공간에서 서로 비슷한 밀도를 지니도록 유도합니다. 이는 모든 점이 동일한 perplexity 를 지니도록 학습되기 때문에 발생하는 현상입니다. 그리고 그 결과로 원 공간의 구조가 많이 왜곡되어 시각화됩니다. 하지만 원 공간에서 가까운 점은 2 차원에서도 가까우며, 이 점이 시각화에서 가장 중요하기 때문에 t-SNE 는 시각화의 목적으로 자주 이용됩니다.
또한 t-SNE 는 넓은 영역의 공간을 휘어서 표현합니다. 이는 t-SNE 가 오로직 가까운 점들 간의 관계만 고려하기 때문에 발생하는 문제입니다. 데이터의 전체적인 구조는 Principal Component Analysis (PCA) 가 더 잘 표현합니다. 아래 그림들은 뉴스 데이터를 이용하여 단어와 뉴스에 대한 벡터를 학습한 그림입니다. 첫번째 그림은 PCA 를 이용하여 단어와 뉴스 벡터를 함께 2 차원으로 표현한 경우입니다. 파란색이 뉴스 벡터입니다. 뉴스가 원점 주변에 몰려있고 단어가 많은 공간에 퍼져있다는 것은 Doc2Vec 의 많은 공간에 단어가 흩뿌려져 있고, 문서는 좁은 공간에 몰려있음을 의미합니다.

하지만 t-SNE 를 이용하여 아래 그림을 그리면 좁은 영역에 몰려 있어야 하는 뉴스 문서 벡터들이 널리 퍼져 단어 벡터들을 감싸는 모양을 하고 있습니다. 학습 시 문서는 약 3 만개, 단어는 약 2 만 3 천개였습니다. 원 공간에서는 서로 다른 밀도로 존재하지만 2 차원에서는 서로 비슷한 밀도로 그려지면서 아래와 같은 왜곡이 발생합니다.

우리가 원하는 시각적인 공간이 무엇인지부터 정의해야 한다.
영화 평점을 document id 로 학습한 뒤, 단어와 함께 t-SNE 나 PCA 를 이용하여 2 차원의 벡터로 표현하면 아래와 같습니다. 일단 t-SNE 에서는 고작 10 개의 점인 영화 평점 벡터들을 한쪽 구석의 점들로 표현합니다.

PCA 의 경우에는 조금 더 넓게 펼쳐져 있습니다. 자세히 보면 살짝 곡선 형태가 보이기도 합니다.

영화 평점 벡터 10 개 만을 따로 PCA 를 이용하여 그려봅니다. 10 개의 점이 위치하는 공간은 100 차원이 아닙니다. 비록 벡터는 100 차원의 공간이지만, 그들의 특성을 표현하는 manifold 의 차원의 크기는 훨씬 적습니다. 그렇기 때문에 PCA 는 10 개 평점 간의 관계를 잘 표현할 수 있습니다. 1 점부터 10 점까지 곡선 형태를 그리며 펼쳐져 있습니다. 영화 평점과 단어를 함께 2 차원의 그림으로 그리려 할 때 아마도 많은 사람들이 기대하는 것은 이와 같은 그림 위에 각 점수와 상관이 높은 단어들이 그 점수 근처에 위치하는 그림일 것입니다. 그리고 이 관점은 단어 간의 관계를 문맥적 유사성이 아닌 단어 - 점수 간 유사성으로 보는 것입니다. 즉 우리가 그림을 그리려 했던 공간은 context space 가 아닌 topic (rate) space 입니다.

이런 그림을 그릴 때에는 뼈대를 먼저 잘 세우는 것이 좋습니다. 영화 평점만을 2 차원으로 표현한 뒤, 단어 벡터들을 이 2 차원 공간에 투영시킵니다. 가장 간단한 방법으로 각 단어가 특정 점수에 등장했던 비율, 혹은 lift 와 같은 값을 이용하여 단어와 점수 간의 상관성을 수치로 표현합니다. 이를 가중치로 이용하여 각 단어의 2 차원 벡터를 점수 벡터의 가중 평균으로 취합니다. 그 결과는 아래와 같습니다. 위의 그림에서 점수 벡터들이 일종의 convex 형식의 공간을 만들었고, 단어 벡터는 이 점수 벡터 간의 가중 평균이기 때문에 점수 안에 단어가 들어있는 모양의 그림이 그려졌습니다. 그리고 드럽/VA, 역겹/VA 과 같은 단어는 2, 3 점에 짱/MAG, 재밌어요/NA 와 같은 단어는 9, 10 점 근처에 위치함을 볼 수 있습니다.
이처럼 Doc2Vec 에서 단어와 문서 벡터는 한 집에 살지만 서로 각방을 쓰는 사이처럼 반드시 같은 공간에 위치하지 않을 수도 있습니다. 이런 상황에서 단어와 문서 벡터를 한 장의 그림에 함께 그리기 위해서는 두 개의 레이어를 겹쳐줘야 합니다. 우리가 표현할 기준 공간의 레이어가 무엇인지를 먼저 정의합니다. 그리고 나머지 레이어들을 기준 레이어에 맞춰 그리면 (아마도) 우리가 원하는 그림을 그릴 수 있습니다.
[이 링크]는 Bokeh 를 이용하여 위의 그림을 interactive 하게 살펴보도록 만든 것입니다. 위의 그림을 그리기 위한 Bokeh 코드와 실험에 이용한 데이터 및 Doc2Vec 학습 코드는 모두 이 repository 에 올려두었습니다.