Word2Vec 은 비슷한 문맥을 지니는 단어를 비슷한 벡터로 표현하는 distributed word representation 방법입니다. 또한 word2vec 은 embedding 의 원리에 대하여 이해할 수 있는 아주 좋은 주제이기도 합니다. 이 방법을 확장하면 Doc2Vec 같은 문서의 distributed representation 도 학습할 수 있습니다.
Word2Vec, as softmax regression
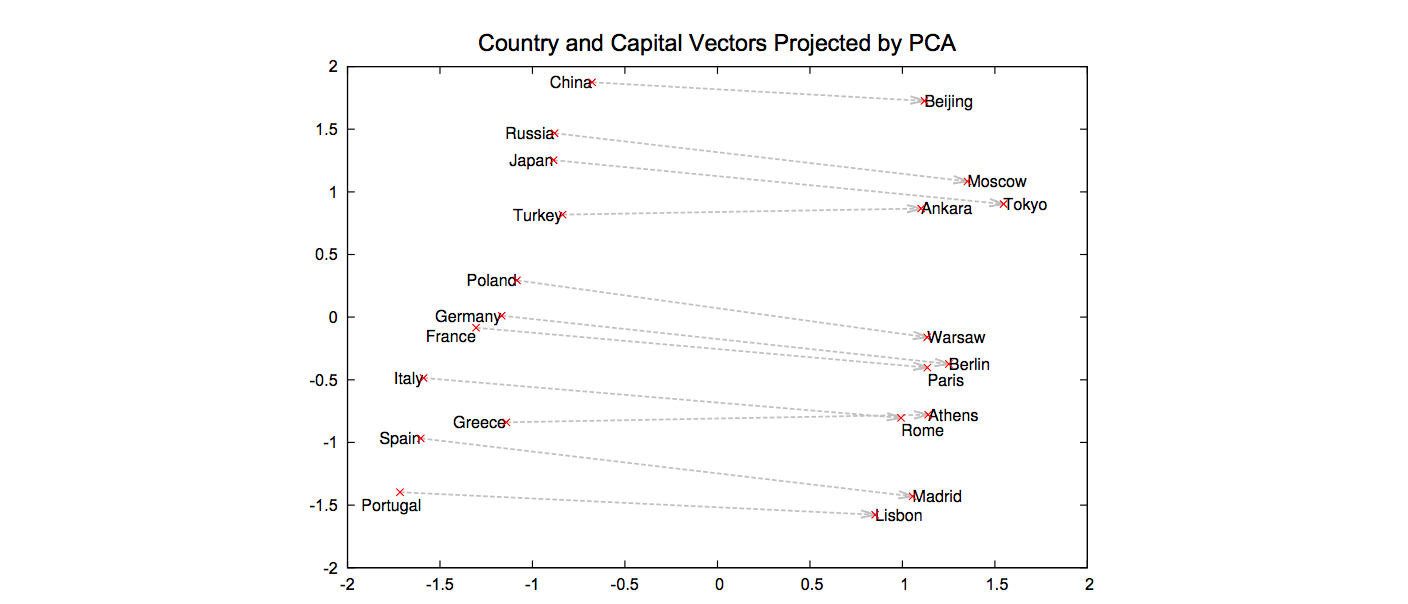
2014 년 Word2Vec (Mikolov et al., 2013b) 논문을 처음 보았을 때가 기억이 납니다. v(China) - v(Beijing) = v(Russia) - v(Moscow) 그림이 정말 신기했습니다. 데이터 만으로도 단어의 의미적 관계가 학습이 되었으니까요. 저는 Word2Vec 논문 이후로 ‘딥러닝 + 자연어처리’와 embedding 주제에 대하여 공부를 시작하게 되었습니다. 아마도 저뿐 아닌 많은 분들이 Word2Vec 을 시작으로 ‘딥러닝 + 자연어처리’를 공부하실거라 생각합니다. 이번 포스트에서는 word2vec 의 원리에 대하여 알아보고, 이를 embedding, representation learning 의 일반적인 원리로 확장합니다.
Word2Vec 은 Softmax regression 입니다. 이전 softmax 포스트의 설명을 이어서 Word2Vec 원리를 이야기하기 때문에 이전의 포스트를 먼저 읽어주세요.
Word2Vec 은 의미공간이라는 고차원 공간에 각 단어의 좌표값을 부여합니다. 이 공간에서 각 좌표값의 숫자는 의미를 지니지 않습니다. 이는 지구의 위도, 경도와 같습니다. (동경 127, 북위 37) 이라는 숫자는 절대적인 의미를 지니지 않습니다. 기준점이 달라지면 숫자도 달라질테니까요. 하지만 (동경 130, 북위 36) 은 그 근처라는 것을 알 수 있습니다. 상대적인 거리는 의미를 지닙니다. 단어의 의미공간도 비슷합니다. 비슷한 벡터좌표를 지니는 두 단어는 비슷한 느낌의 단어입니다.
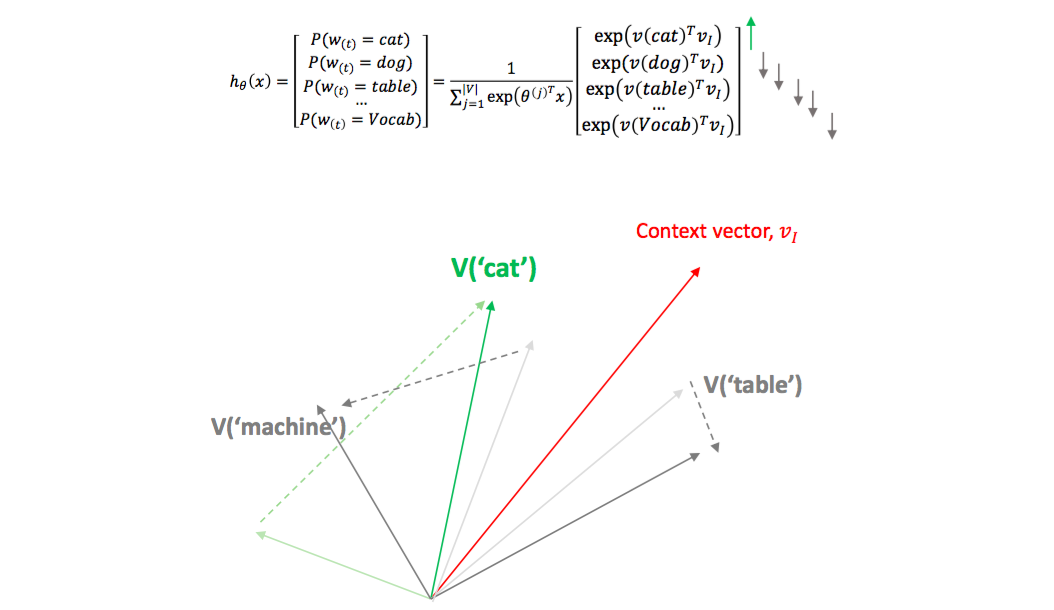
Word2Vec 은 softmax regression 의 확장입니다. Softmax regression 은 데이터 \((X, Y)\) 를 이용하여, 입력된 input \(x\) 가 클래스 \(y\) 가 될 확률을 최대화 시키는 방향으로 클래스 \(y\) 의 대표벡터를 coefficient \(\beta\) 에 학습합니다. 아래 식을 살펴보면 \(x\)에 대한 \(y\) 의 확률은 \(x\) 와 모든 클래스 종류의 \(y_j\) 와의 내적을 exponential 함수에 넣어 non-negative 로 만든 뒤, 모든 \(exp(\beta_j^Tx)\) 의 합으로 나눠서 확률 형식을 만듭니다. \(x\) 가 입력되었을 때 \(y\) 가 가장 큰 확률을 가지기 위해서는 해당 \(y\) 와 \(x\) 의 내적은 가장 크고 다른 \(y_j\) 와 \(x\) 의 내적은 작아야 합니다. Softmax regression 을 다시 생각해보세요. \(x\) 와 이에 해당하는 클래스의 대표벡터가 같은 방향이어야 \(P(y \vert x)\) 가 커집니다.
\[maximize P(y_k \vert x) = \frac{exp(\beta_{y_k}^Tx)}{\sum_{j} exp(\beta_{j}^Tx)}\]흔히 생각하는 softmax regression 은 문장의 단어들 \(X\) 를 이용하여 문장의 긍부정 \(Y\) 를 예측합니다. \(X\) 와 \(Y\) 의 종류가 다릅니다. 하지만 Word2Vec 은 단어 \(X\)로 단어 \(Y\) 를 예측합니다. \(X\), \(Y\) 가 모두 단어입니다.
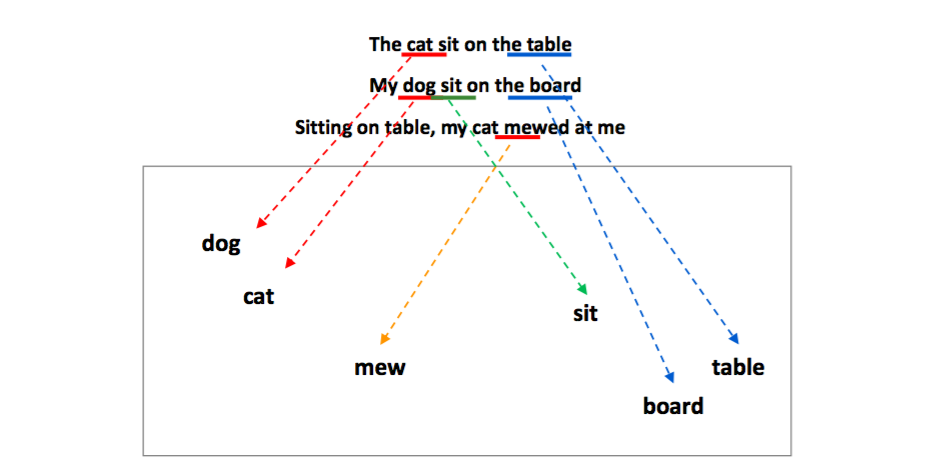
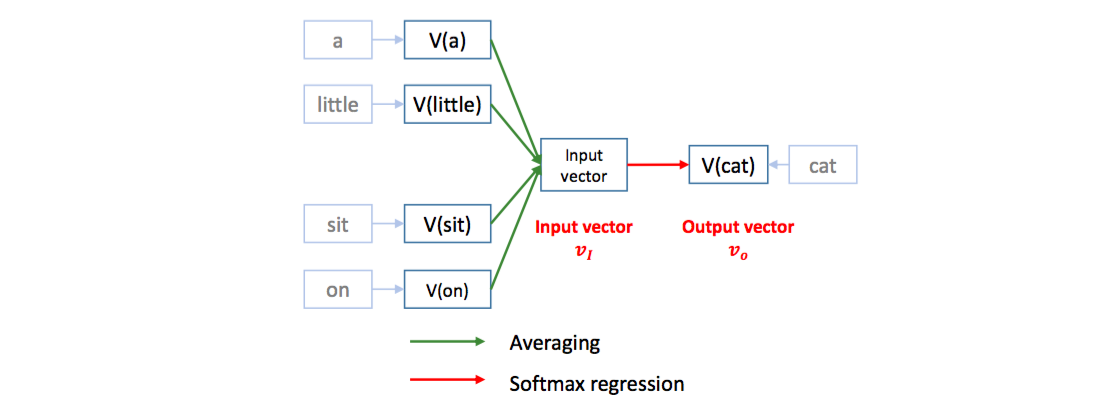
Word2Vec 은 window classification 처럼, 긴 문장에 스캐너가 이동하며 스냅샷을 찍듯이 작동합니다. 예를 들어 [a, little, cat, sit, on, the, table] 이라는 문장이 주어졌을 때, 크기 5인 (-2, 2) 의 스캐너를 이동하여 [a, little, cat, sit, on] 이라는 스냅샷을 하나 만듭니다. 스냅샷의 양 옆의 [a, little, sit, on] 네 단어로 ‘cat’ 이라는 가운데 단어를 예측하는 regression 문제를 학습합니다. 즉 [a, little, sit, on] 네 단어가 \(X\), ‘cat’ 이 \(Y\) 입니다. 단어를 \(X\) 로 이용하기 위해서 각 단어의 의미공간에서의 위치좌표, 벡터값을 이용합니다. 각 단어는 의미공간에서 각자의 좌표값을 가지고 있습니다. ‘a’ 가 입력되면 이에 해당하는 좌표값을 가지고 옵니다. \(X, Y\) 의 내적이 성립하려면 두 벡터의 차원의 크기가 같아야 합니다. [a, little, sit, on] 의 네 단어에 대한 좌표값을 모두 가지고 온 뒤 평균을 취하면 \(Y\) 와 같은 차원의 벡터가 됩니다. 이 과정이 한 스냅샷에서 이뤄지는 학습입니다.
학습이 끝나면 스캐너를 옆으로 한 칸 이동시킵니다. 이번에는 [little, cat, on, the] 로 ‘sit’ 을 예측하도록 학습합니다.
Word2Vec 의 학습은 의미공간에서의 각 단어의 위치좌표를 수정하는 것입니다. 각 단어의 위치좌표는 random vector 로 초기화 합니다. 이때는 당연히 위의 softmax regression 공식이 잘 맞지 않습니다. \(P(cat \vert [a, little, sit, on])\) 이 커지도록 각 단어의 좌표를 조절해야 합니다. [a, little, sit, on] 의 평균벡터를 context vector, \(v_I\) 라 하면, ‘cat’ 의 위치벡터는 \(v_I\) 와 비슷하고, 다른 단어의 벡터는 \(v_I\) 와 달라야 합니다. Softmax regression 이니까요. \(v_I\) 와 비슷한 위치에 있는 cat 이 아닌 단어들은 밀어버리면 \(P(cat \vert v_I)\) 가 좀 더 커집니다. 그리고 내적을 크게 만들기 위해서 cat 의 벡터 크기도 좀 늘리면서요.
‘a little dog sit on the table’ 이란 문장도 나올법합니다. 즉 cat 과 dog 은 비슷한 문맥에서 등장합니다. 우리는 context vector 에 \(Y\) 의 벡터가 가까워지도록 학습을 하고 있습니다. 그렇다면 좌/우에 등장하는 단어가 비슷한 cat 과 dog 은 서로 같은 목적지를 향하여 위치벡터를 움직입니다. 이런 원리로 비슷한 문맥을 지니는 단어는 비슷한 벡터값을 가지게 됩니다.
Negative sampling
하지만 위 공식대로 cat 을 context vector 방향으로 당겨오고, 다른 단어들을 모두 밀어버리면 학습량이 엄청납니다. 데이터 전체에 10 만개 정도의 단어가 존재한다면, cat 한 개를 \(v_I\) 로 당겨오고, 99,999 개의 단어를 밀어내야 합니다. 사실 softmax regression 입장에서 충분히 떨어진 단어는 영향력이 적습니다. exp(-1) 이나 exp(-10) 의 크기는 exp(10) 과 비교하면 둘 모두 무시할만큼 작습니다. 중요한 것은 cat 을 context vector 방향으로 당겨오는 것입니다. 그렇기 때문에 99,999 개의 단어 중에 몇 개만 대표로 뽑아서 context vector 반대 방향으로 밀어냅니다. 이를 negative sampling 이라 합니다. cat 은 positive sample, 나머지 단어가 negative samples 입니다.
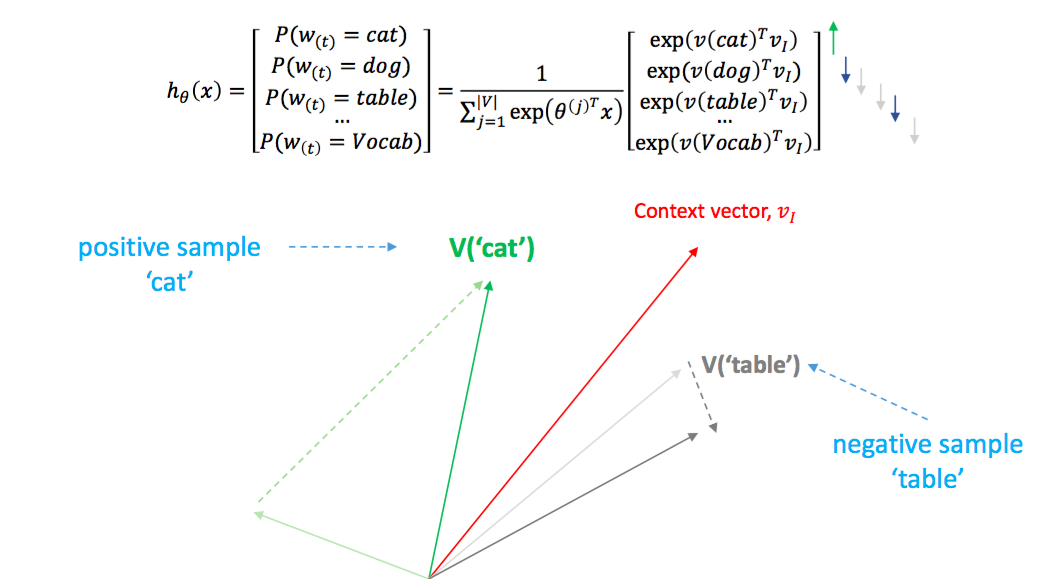
Negative sampling 은 각 단어의 빈도수를 고려해야 합니다. 자주 등장한 단어를 높은 확률로 선택되도록 샘플링 확률을 만듭니다. 자주 등장한 단어만큼은 제대로 학습을 하려함입니다. 수식은 크게 중요하지는 않습니다만, 빈도수를 고려하여 샘플링을 한다는 점이 중요합니다.
위 그림에서 negative samples 로 dog 이 선택될 수도 있습니다. cat 과 dog 은 비슷한 위치벡터를 지녀야 하는데, negative samples 로 선택되면 dog 이 서로 다른 벡터로 밀려납니다. 하지만 단어가 워낙 많기 때문에 dog 이 cat 의 negative samples 로 선택될 가능성은 작습니다. 더하여 negative samples 의 이동량과 positive sample 의 이동량이 다릅니다. cat 을 context vector 주위로 빡세게 당기고, dog 을 조금만 바깥으로 밀어냅니다. dog 이 아닌 table 같은 단어라면 본인이 위치할 자리로 당겨지기 때문에 cat 과 충분히 멀리 떨어집니다.
Doc2Vec
Word2Vec 이 등장한 이후 몇 달 지나지 않아 의미공간에 document 의 위치좌표를 학습하는 방법이 제안됩니다. Doc2Vec 은 document id 를 하나의 단어처럼 생각합니다. ‘a little dog sit on the table’ 이란 문장에 해당하는 document id, #doc5 역시 의미공간에서의 위치 좌표를 지닙니다. 그리고 모든 스냅샷에서 다른 단어들의 위치좌표와 함께 평균을 취하여 context vector 를 만듭니다. 그 다음은 Word2Vec 과 같습니다. document id + 4 개의 단어로 이뤄진 context vector 에 가깝도록 \(Y\), cat 의 위치를 조절합니다.
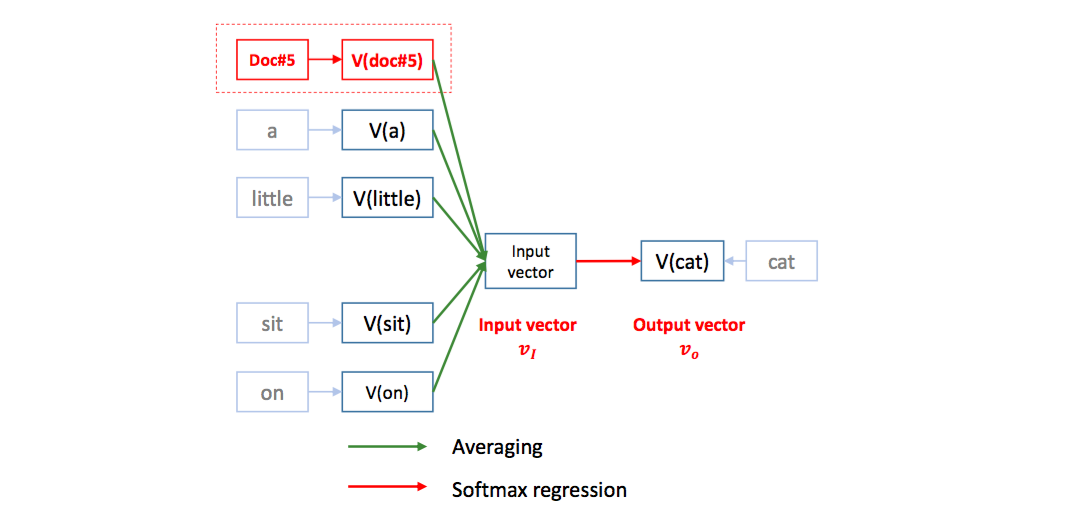
Word2Vec 의 수식에서 \(exp({v_I}^{T}v_y) = exp\left(\left(\frac{v_{x1} + \cdots + v_{x4}}{4}\right)^T v_y\right)\) 입니다. cat 을 각 네 단어의 가운데 방향으로 이동시킨 것과 비슷합니다. 각 \(X_i\) 의 네 방향으로 \(Y\) 를 당깁니다. 비슷하게 Doc2Vec 은 document id 와 각 문서 (혹은 문장)에 등장하였던 단어들이 서로 가까워지도록 document vector 를 움직입니다.
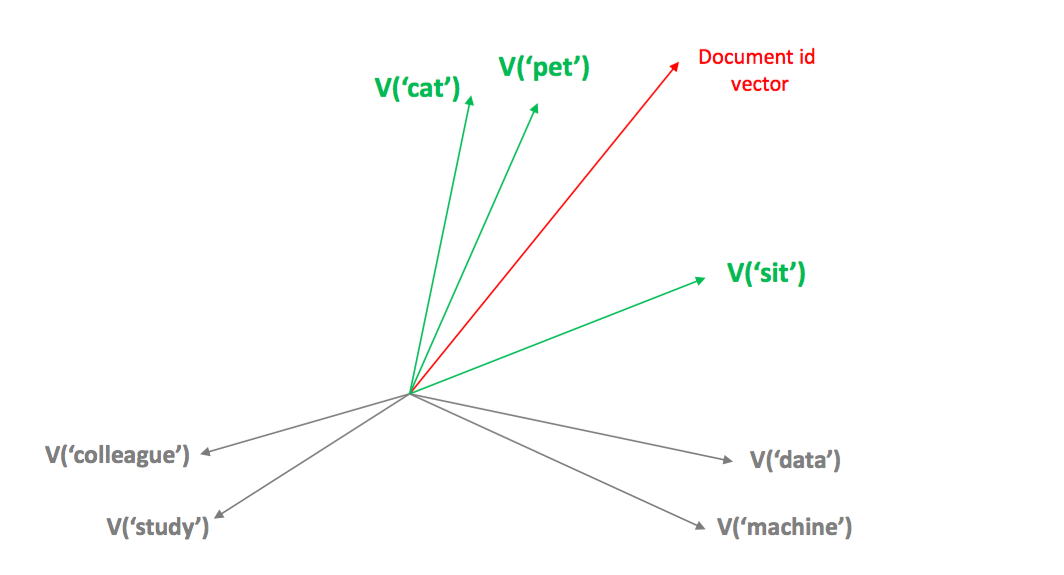
단어가 다르더라도 단어의 벡터들이 비슷하다보니 각 문장의 document vectors 가 비슷해집니다. v(cat) \(\simeq\) v(dog), v(table) \(\simeq\) v(board) 이기 때문에 v(‘a little cat sit on table’) \(\simeq\) v(‘a little dog sit on board’) 가 됩니다. 이는 entity - descriptor 의 관계로 생각할 수 있습니다. 임베딩을 하고 싶은 entity 에 대하여 이를 기술할 수 있는 단어, 혹은 이와 비슷한 list of descriptor 를 정의할 수 있다면 entity 의 임베딩 벡터를 학습할 수 있습니다.
Pharagraph2Vec
Doc2Vec 은 재밌는 결과를 보여줍니다. (Dai et al., 2015) 에서는 Wikipedia 의 영어 문서에 Doc2Vec 를 적용하였습니다. 그리고 “Lady Gaga” 페이지의 document vector 와 비슷한 다른 페이지의 document vector 를 찾았습니다. 아래 그림의 (a) 처럼 리한나, 비욘세 같은 다른 미국의 팝 여가수들이 비슷한 document vector 를 지닙니다. 이처럼 동지역, 동시대에 활동한 여가수들이 비슷한 벡터를 지니는 것은 각 페이지에 등장하는 단어의 분포가 비슷하기 때문입니다. 물론 다른 단어들도 많겠지만, 그 단어들의 임베딩 벡터들이 비슷했을 겁니다. Doc2Vec 은 단어의 의미를 고려한 term frequency vector 의 압축으로 해석할 수 있습니다.
더 재밌는 결과는 그림 (b) 입니다. v(“Lady Gaga”) - v(“American”) + v(“Japanese”) 을 계산한 뒤, 비슷한 벡터를 찾아보니 아무로 나미에, 나카가와 쇼코 같은 일본 가수, 혹은 배우 였습니다. 이런 결과가 등장하는 이유는 v(“Lady Gaga”) - v(“Namie Amuro”) \(\simeq\) v(“American”) - v(“Japanese”) 이기 때문입니다. 레이디 가가와 아무로 나미에에 등장하는 공통된 단어들은 가수, 음악 활동과 관련된 단어일 것입니다. 미국인과 일본인의 문맥에 등장하는 공통된 단어들은 경제, 사회, 문화와 관련된 일반적인 단어일 것입니다. 공통된 단어가 서로 제외되면 두 나라의 고유한 단어들이 남았을테고, 그 차이가 비슷하다는 의미입니다. 위 식을 정리하면 v(“Lady Gaga”) - v(“American”) + v(“Japanese”) \(\simeq\) v(“Namie Amuro”) 입니다.
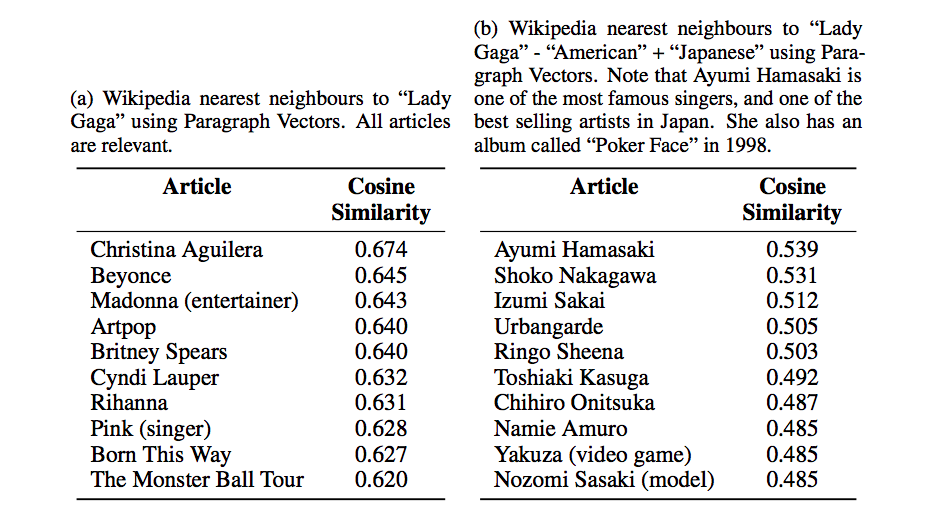
영어 wikipedia 는 그만큼 각 문서의 형식이 통일되어 있다는 의미입니다. 어떤 데이터에 이와 같은 벡터 연산을 수행했는데 잘 되지 않는다면 entity 를 설명하는 descriptor 들이 이 공식에 적용할 수 있는지 확인해 보세요.
History: Feed-forward neural network language model
\(P(cat \vert [a, little, sit, on])\) 처럼 문장의 일부 단어를 이용하여 가운데, 혹은 그 다음에 등장할 단어를 예측하는 문제를 language model 이라 합니다. 서로 다른 단어는 완전히 다른 것으로 취급하는 language model 을 statistical langauge model 이라 불렀으며 n-gram 은 statistical language model 을 계산하기 위한 방법입니다. 그런데 세상에는 너무나 많은 단어가 있습니다. 2006년에 발표한 Google n-gram corpus 의 크기만 보더라도 단어의 수가 …
File sizes: approx. 24 GB compressed (gzip'ed) text files
Number of tokens: 1,024,908,267,229
Number of sentences: 95,119,665,584
Number of unigrams: 13,588,391
Number of bigrams: 314,843,401
Number of trigrams: 977,069,902
Number of fourgrams: 1,313,818,354
Number of fivegrams: 1,176,470,663
(refer. Google blog)
Language model 을 압축할 필요가 있었고, Bengio 교수는 feed-forward neural network 를 이용한 language model 을 만듭니다. 이때에는 \(P(on \vert [a, little, cat, sit])\) 을 학습하였습니다. 그리고 input 으로 입력되는 단어의 벡터를 연속으로 이어붙였습니다 (concatenation). 각 단어가 100 차원의 위치벡터를 지녔다면 input 으로 400 차원의 벡터가 만들어집니다. 그리고 이를 hidden layer 에 입력합니다. Hidden 의 output 이 ‘on’ 과 같은 차원이면 내적을 할 수 있습니다. 그 다음은 softmax regression 입니다. 사실 word embedding 은 neural language model 의 부산물입니다.
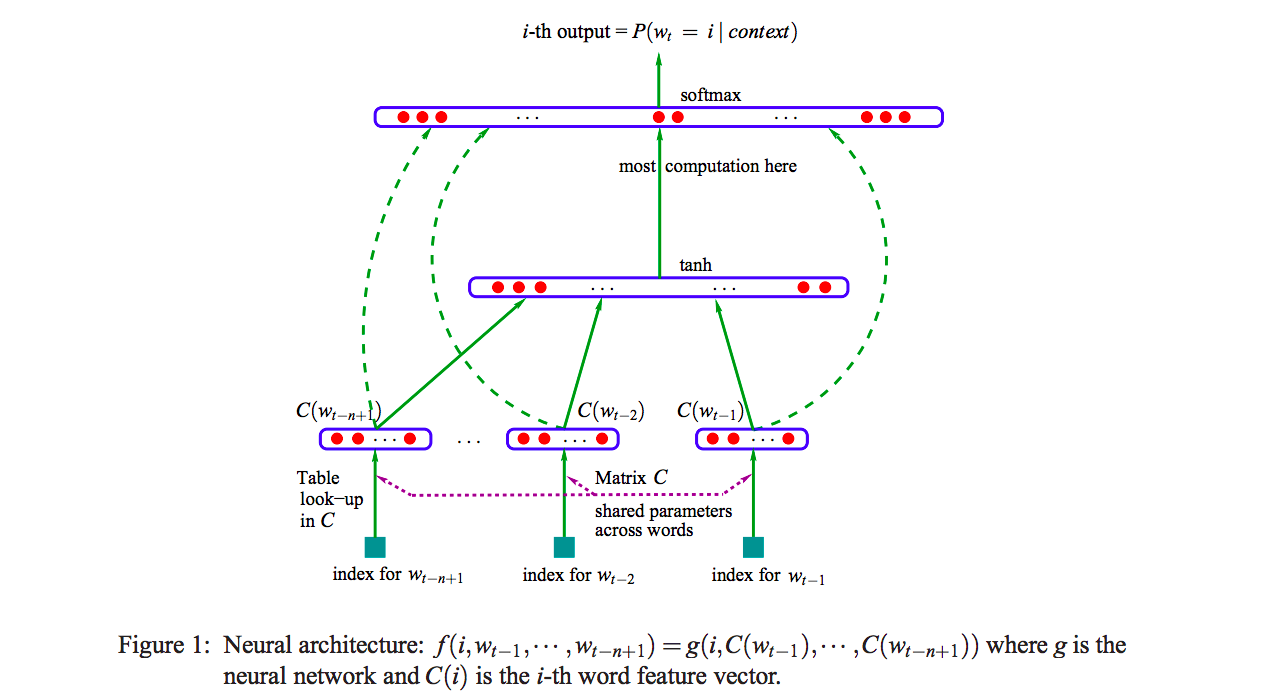
이런 구조로 모델을 학습하면 학습시간이 15일, 한 달 정도 걸렸습니다. Word2Vec 은 feed-forward neural language model 에서 불필요한 부분들을 걷어냈습니다. 반드시 hidden 을 거칠 필요가 없었습니다. 또한 concatenation 도 굳이 필요가 없었습니다. Hidden layer 를 제거하고 concatenation 대신 평균을 취했더니 매우 빠르게 word embedding 을 학습하였습니다. 여기에 negative sampling 까지 더해져 속도가 훨씬 빨라졌습니다. 일반적인 컴퓨터 환경에서도 word embedding vector 를 빠르게 학습을 할 수 있다보니 Word2Vec 이 다양한 분야에서 이용되기 시작했습니다.
Gensim
Gensim 은 topic modeling 에 자주 이용되는 Latent Dirichlet Allocation (LDA) 이나 Random Projection (RP) 와 같은 방법들이 구현되어 있는 Python 라이브러리였습니다. 덕분에 Python 사용자들이 topic modeling 을 편하게 이용하게 되었습니다. Version 이 업데이트 되면서 Word2Vec 과 Doc2Vec 같은 embedding 방법들도 포함이 되었습니다.
2016.12 ~ 2018.1 사이에 gensim 의 버전은 0.12 에서 3.1+ 까지 바뀌었습니다. 이용하실 때 반드시 버전 확인을 하시기 바랍니다. 저는 gensim 2.x 을 이용할 때 다른 패키지들, 혹은 이전 버전과 많은 충돌이 났었습니다. 반드시 최신버전으로 업데이트를 하셔서 이용하세요.
Gensim 의 Word2Vec, Doc2Vec 을 학습하기 위해서는 list of str (like) 구조의 input 이 필요합니다. 물론 파일을 모두 읽어 메모리에 띄어둬도 좋지만, 학습할 문서가 크다면 좋은 방법은 아닙니다. 어자피 한 문장 단위로 스냅샷을 만들기 때문입니다. DoublespaceLineCorpus 와 같이 iter() 함수를 구현한 class 면 다 좋습니다. 단, Word2Vec 과 Doc2Vec 은 yield 할 때 document id 의 유무가 다릅니다.
class Word2VecCorpus:
def __init__(self, fname):
self.fname = fname
def __iter__(self):
with open(self.fname, encoding='utf-8') as f:
for doc in f:
yield doc.split()학습은 매우 간단합니다. gensim.models.Word2Vec 의 맨 앞 위치변수에 학습데이터를 입력합니다.
그 외에 신경써야 할 arguments 에 대하여 알아봅니다. size 는 임베딩 벡터의 크기입니다. 아주 작은 수준만 아니라면 벡터의 차원이 커진다고 학습의 경향이 달라지진 않습니다. 적당히 큰 숫자면 충분합니다. alpha 는 learning rate 입니다. 기본값 쓰셔도 됩니다. window 는 스냅샷의 크기입니다. “a little, (cat), sit, on”의 windows 는 2 입니다. 앞 뒤로 고려하는 단어의 개수입니다. Word2Vec 에서는 2 ~ 5 정도면 비슷한 경향을 보입니다. min count 는 데이터에서 등장하는 단어의 최소빈도수입니다. Word2Vec 은 자주 등장하지 않은 단어에 대해서는 제대로 학습이 이뤄지지 않습니다. 또한 min_count 가 작으면 모델에 지나치게 많은 단어가 포함되어 모델의 크기가매우 커집니다. sg 는 skip-gram 옵션입니다. Word2Vec 의 구조를 skip-gram, cbow 두 가지로 설명하는데, 이는 포스트에서 언급하지 않았습니다. negative 는 negative samples 의 개수입니다. 이 역시 기본값 쓰셔도 됩니다. 클수록 학습속도가 느려집니다. 하지만 지나치게 작으면 학습이 제대로 이뤄지지 않습니다.
from gensim.models import Word2Vec
word2vec_model = Word2Vec(
word2vec_corpus,
size=100,
alpha=0.025,
window=5,
min_count=5,
sg=0,
negative=5)실험을 위하여 네이버 영화의 댓글 데이터를 이용하였습니다. 리뷰가 많은 상위 172 개 영화의 리뷰만을 이용하여 Word2Vec 을 학습하였습니다. 학습된 모델을 이용하여 벡터가 비슷한 단어를 찾을 때는 most_similar() 를 이용합니다. topn 은 출력할 비슷한 단어의 개수입니다. 기본값은 10 입니다.
word2vec_model.most_similar('영화', topn=30)Return type 은 list of tuple 이며, (단어, cosine similarity) 형식입니다. ‘영화’와 비슷한 문맥을 지니는 단어는 ‘애니, 애니메이션, 작품, 명화, .. ‘ 등이 있습니다.
[('애니', 0.7358444929122925),
('애니메이션', 0.6823039650917053),
('작품', 0.6504106521606445),
('명화', 0.6343749761581421),
('드라마', 0.6164193153381348),
('에니메이션', 0.5870470404624939),
('엉화', 0.5800251960754395),
('수작', 0.5750955939292908),
('양화', 0.5740913152694702),
('블록버스터', 0.5722830295562744),
('경우', 0.5505275726318359),
...
배우 이름을 검색하면 다른 배우 이름들이 return 됩니다. 배우 이름이 등장하는 문맥이 비슷하다는 의미입니다.
word2vec_model.most_similar('하정우', topn=10)[('송강호', 0.8988009691238403),
('공유', 0.8613319993019104),
('이정재', 0.8584579825401306),
('황정민', 0.8367886543273926),
('유해진', 0.8114255666732788),
('유아인', 0.8047819137573242),
('박해일', 0.7996563911437988),
('조진웅', 0.7989823222160339),
('송광호', 0.7985018491744995),
('윌스미스', 0.7959412336349487)]
1점이라는 단어를 입력하면 ‘일점, 별1개, … 3점, 5점, … 십점’의 순서로 단어가 비슷하게 학습되었음을 볼 수 있습니다. 점수라는 문맥에서는 모두 비슷한 단어이지만, 1점과 2점의 문맥이 1점과 10점의 문맥보다는 더 비슷하기 때문입니다.
word2vec_model.most_similar('1점', topn=10)[('일점', 0.8926405906677246),
('별1개', 0.8522111773490906),
('2점', 0.8321202397346497),
('별반개', 0.8262494802474976),
('별한개', 0.8256757259368896),
('3점', 0.8106338977813721),
('5점', 0.7885047793388367),
('4점', 0.7837859392166138),
('십점', 0.7627658247947693),
('삼점', 0.7567068934440613)]
그리고 Word2Vec 은 언어 의존적인 알고리즘이 아닙니다. 일단 문장이 단어열로 잘 나뉘어져 있다면 어떤 언어로 기술된 단어인지는 관심이 없습니다. 그래서 ‘4d’ 의 유사어로 ‘포디, 쓰리디’가 학습됩니다. 그렇기 때문에 토크나이저가 중요합니다. 토크나이징만 제대로 되었다면 이런 작업들이 가능합니다.
word2vec_model.most_similar('4d')[('4D', 0.9113297462463379),
('3d', 0.8544139862060547),
('2d', 0.848015546798706),
('IMAX', 0.8241705894470215),
('3D', 0.8238675594329834),
('2D', 0.8155646324157715),
('imax', 0.8152340650558472),
('3디', 0.8137110471725464),
('포디', 0.8120430707931519),
('쓰리디', 0.7974785566329956)]
Gensim 에서 Doc2Vec 은 Word2Vec 과 매우 비슷합니다. Doc2Vec 학습에 이용할 데이터가 label\tsentence 형식으로 탭 구분이 되어있다면 다음처럼 input class 를 만들면 됩니다.
from gensim.models.doc2vec import TaggedDocument
class Doc2VecCorpus:
def __init__(self, fname):
self.fname = fname
def __iter__(self):
with open(self.fname, encoding='utf-8') as f:
for doc in f:
movie_idx, text = doc.split('\t')
yield TaggedDocument(
words = text.split(),
tags = ['MOVIE_%s' % movie_idx])
doc2vec_corpus = Doc2VecCorpus(path)학습 역시 동일합니다. 이번에는 기본 설정이 되어 있는 arguments 에 대해서는 설명하지 않습니다.
from gensim.models import Doc2Vec
doc2vec_model = Doc2Vec(doc2vec_corpus)gensim.models.Doc2Vec 은 gensim.models.Word2Vec 을 상속하기 때문에 비슷한 단어를 찾는 부분은 인터페이스가 동일합니다.
doc2vec_model.most_similar('영화', topn=10)Document vector 에 관련된 부분은 Doc2Vec.docvecs 에 저장되어 있습니다.
len(doc2vec_model.docvecs) # 172docvecs.doctags 에는 각 document idx 에 대한 정보가 담겨 있습니다.
for idx, doctag in sorted(doc2vec_model.docvecs.doctags.items(), key=lambda x:x[1].offset):
print(idx, doctag)제가 학습에 이용했던 데이터의 스냅샷입니다.
72523\t이 영화 진짜 재미 있다
72523\t와 개명작
...
59845\t .....
Doc2VecCorpus class 에서 tags = [‘MOVIE_%s’ % movie_idx]) 로 document idx 를 만들었기 때문에 ‘MOVIE_72523’ 같은 형식이 보입니다. 그리고 offset 은 docvecs 의 array 의 row idx 입니다. word_count 는 이 영화에 대하여 94,513 개의 단어가 등장했단 의미이며, doc_count 인 10,187 개의 평점이 학습되었다는 의미입니다.
MOVIE_72523 Doctag(offset=0, word_count=94513, doc_count=10187)
MOVIE_59845 Doctag(offset=1, word_count=144494, doc_count=13095)
MOVIE_109753 Doctag(offset=2, word_count=202367, doc_count=10361)
MOVIE_45321 Doctag(offset=3, word_count=294482, doc_count=26915)
MOVIE_45290 Doctag(offset=4, word_count=775777, doc_count=48273)
MOVIE_47385 Doctag(offset=5, word_count=412600, doc_count=41653)
MOVIE_78726 Doctag(offset=6, word_count=326349, doc_count=20615)
비슷한 entity (영화)를 검색하고 싶다면 두 가지 방법이 있습니다. 직접 태그를 입력할 수 있습니다.
doc2vec_model.docvecs.most_similar('MOVIE_59845')[('MOVIE_72408', 0.837012529373169),
('MOVIE_45232', 0.7936373949050903),
('MOVIE_42589', 0.7711942195892334),
...
혹은 offset 을 입력할 수도 있습니다. ‘MOVIE_59845’ 은 offset=1 이므로 int 1 을 입력합니다. 동일한 결과가 출력됩니다.
doc2vec_model.docvecs.most_similar(1)[('MOVIE_72408', 0.837012529373169),
('MOVIE_45232', 0.7936373949050903),
('MOVIE_42589', 0.7711942195892334),
...
이 실험에서는 각 영화에 대하여 평점의 단어를 descriptor 로 이용하였습니다. 평점의 단어 분포가 비슷한 영화는 비슷한 벡터로 학습되었을 겁니다. 영화 idx 를 타이틀로 바꿔서 비슷한 벡터를 지닌 영화를 찾아봅니다. ‘라라랜드’ 와 평점의 텍스트가 비슷한 영화입니다.
영화명 아이디 cosine similarity
('비긴 어게인', '96379', 0.9032233953475952)
('어바웃 타임', '92075', 0.8765992522239685)
('인턴', '118917', 0.7271023988723755)
('레미제라블', '89755', 0.723423421382904)
('시간을 달리는 소녀', '63513', 0.7076219320297241)
('어거스트 러쉬', '66158', 0.7059367299079895)
('인사이드 아웃', '115622', 0.703054666519165)
('뷰티 인사이드', '129050', 0.6897991895675659)
('겨울왕국', '100931', 0.6725324392318726)
('건축학개론', '88426', 0.6720962524414062)
이는 영화 ‘관상’과는 서로 다름을 알 수 있습니다. 라라랜드는 로맨틱한 영화 혹은 감동을 주는 영화들과 비슷한 리뷰가 달립니다만, ‘관상’은 한국 배우들이 출연하고 (특히 송강호) 박진감이 있으나 무겁지 않은 영화들이 비슷한 리뷰가 달려있음을 확인할 수 있습니다.
영화명 아이디 cosine similarity
('광해, 왕이 된 남자', '83893', 0.8137872219085693)
('역린', '108225', 0.8076189160346985)
('사도', '121922', 0.7572917938232422)
('군도:민란의 시대', '99752', 0.7350413203239441)
('신세계', '91031', 0.6875192523002625)
('검사외전', '130903', 0.6713172793388367)
('도둑들', '78726', 0.6678873300552368)
('신의 한 수', '107373', 0.6661410927772522)
('의형제', '52548', 0.6627491116523743)
('밀정', '137952', 0.654565691947937)
Reference
- Bengio, Y., Ducharme, R., Vincent, P., & Jauvin, C. (2003). A neural probabilistic language model. Journal of machine learning research, 3(Feb), 1137-1155.
- Dai, A. M., Olah, C., & Le, Q. V. (2015). Document embedding with paragraph vectors. arXiv preprint arXiv:1507.07998.
- Mikolov, T., Chen, K., Corrado, G., & Dean, J. (2013a). Efficient estimation of word representations in vector space. arXiv preprint arXiv:1301.3781.
- Mikolov, T., Sutskever, I., Chen, K., Corrado, G. S., & Dean, J. (2013b). Distributed representations of words and phrases and their compositionality. In Advances in neural information processing systems (pp. 3111-3119).
- Google Research blog, All Our N-gram are Belong to You