Word2Vec 을 학습 할 때, 학습할 단어의 최소 빈도수를 설정해야 합니다. 그리고 Gensim 의 Word2Vec 은 단어 빈도수에 편향성이 있습니다. 빈도수가 작은 단어들이 제대로 학습되지 않기 때문에 최소 빈도수를 잘 설정해야 합니다. 이번 포스트에서는 실제로 infrequent words 가 어떻게 학습되는지 살펴보고, 적절한 최소 빈도수 설정을 위한 경험적 방법에 대해서도 논의합니다.
Word2Vec
Word2Vec 은 Softmax regression 을 이용하여 단어의 의미적 유사성을 보존하는 embedding space 를 학습합니다. 문맥이 유사한 (의미가 비슷한) 단어는 비슷한 벡터로 표현됩니다. ‘cat’ 과 ‘dog’ 은 서로 비슷한 문맥에서 이용될 수 있기 때문에 비슷한 embedding vector 를 지닙니다.
Word2Vec 은 softmax regression 을 이용하여 문장의 한 스냅샷에서 기준 단어의 앞/뒤에 등장하는 다른 단어들 (context words) 이 기준 단어를 예측하도록 classifier 를 학습합니다. 그 과정에서 단어의 embedding vectors 가 학습됩니다. Context vector 는 앞/뒤 단어들의 평균 임베딩 벡터 입니다. [a, little, cat, sit, on, the, table] 문장에서 context words [a, little, sit, on] 를 이용하여 cat 을 예측합니다.
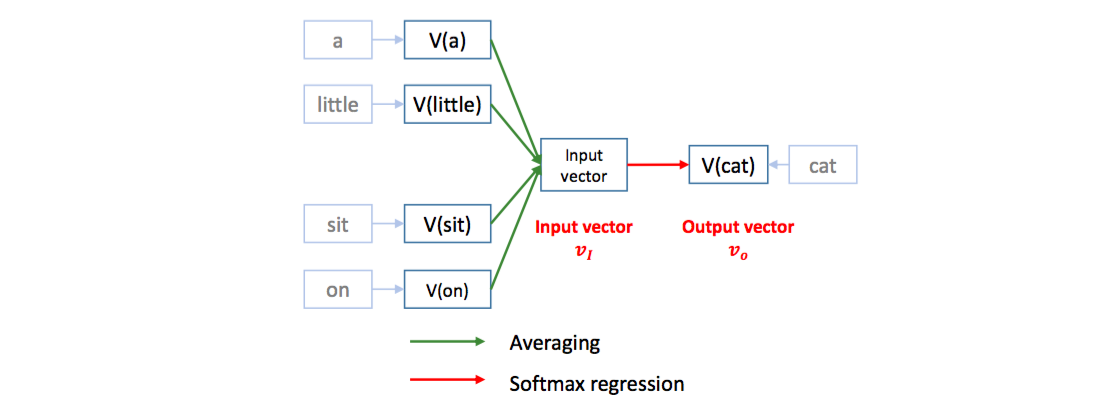
이는 cat 의 임베딩 벡터를 context words 의 평균 임베딩 벡터에 가깝도록 이동시키는 역할을 합니다. 비슷한 문맥을 지니는 dog 도 비슷한 context words 의 평균 임베딩 벡터에 가까워지기 때문에 cat 과 dog 의 벡터가 비슷해집니다.
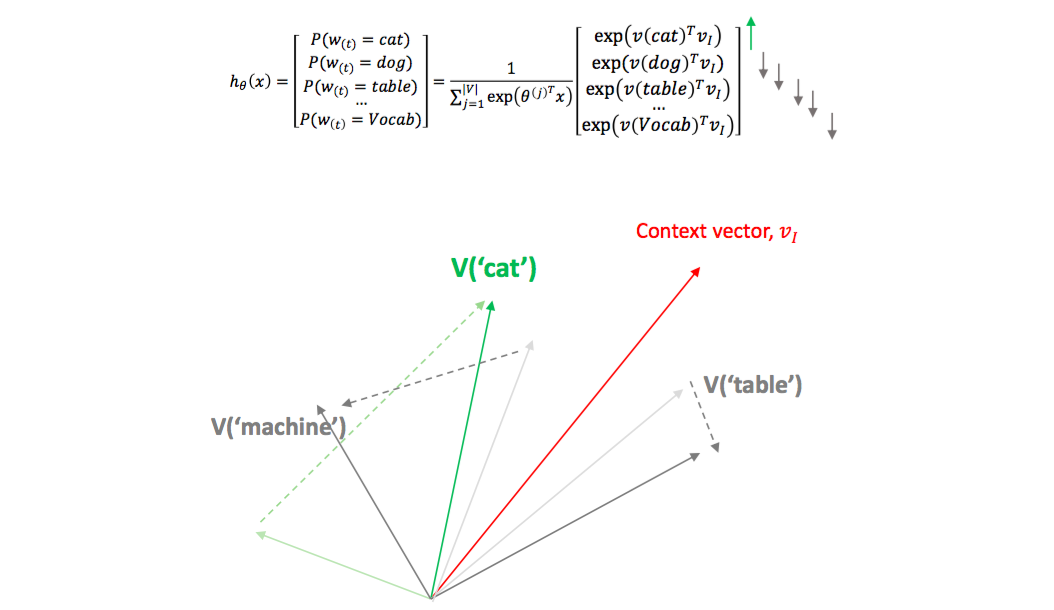
그런데 Softmax regression 을 이용하면 infrequent words 에 대해서는 좋은 embedding vector 가 학습되기 어렵습니다. 한 context 에 여러 단어가 나올 경우 infreqeunt words 는 positive samples 로 선택되는 횟수가 적기 때문입니다. 그래서 저는 Word2Vec 으로 학습된 단어 공간은 단어의 빈도수에 영향을 받아 infrequent words 가 한 공간에 모여있다고 생각합니다.

이에 대한 자세한 설명은 이전 포스트에 있습니다.
인위적으로 생생한 유사어에 대하여 Word2Vec 이 잘 학습되는지 확인하기
그렇다면 최소 몇 번 이상 나온 단어들이 word embedding vector 가 제대로 학습될까요? 이를 확인하기 위해 한 가지 실험을 하였습니다. 2016-10-20 의 뉴스에 대하여 cohesion 을 단어 점수로 학습한 뒤, L-Tokenizer 을 이용하여 토크나이징을 하였습니다. 그 뒤 아래 단어들에 대하여 빈도수만큼 단어에 index 를 추가하였습니다.
| 단어 | 빈도수 | 치환한 단어 개수 |
|---|---|---|
| 트와이스 | 663 | 5, 10, 30 |
| 뉴스 | 4442 | 10, 30, 50 |
| 날씨 | 356 | 10, 20 |
| 정부 | 4237 | 10, 30, 50, 100, 200 |
| 아프리카 | 291 | 10, 20, 30 |
| 경제 | 3096 | 10, 30, 50, 100, 200 |
인위적으로 생성한 유사도의 빈도수를 작게 설정한 경우
트와이스 중 5 개는 트와이스_0, 10 개는 트와이스_1, 30 개는 트와이스_2 로 치환하였습니다. 그 뒤 Gensim 의 Word2Vec 을 학습합니다. 단어의 최소 빈도수는 5 로 설정하였습니다.
from gensim.models import Word2Vec
word2vec_model = Word2Vec(corpus, min_count=5)그 뒤 각 단어마다 Cosine similarity 기준으로 가장 가까운 10 개의 단어를 찾습니다. 맨 윗줄의 괄호는 (빈도수, 원 단어와의 유사도) 입니다. sim(트와이스, 트와이스_0) = 0.631 로 매우 작습니다. 하지만 박재범, 헤이즈 와 같은 단어가 유사어로 학습되었습니다. 그러나 트와이스의 유사 단어들의 빈도수는 주로 100 단위인데, 트와이스_0의 유사어의 빈도수는 작음을 볼 수 있습니다. Gensim 의 Word2Vec 은 단어의 빈도수에 bias 가 있다는 의미입니다.
| 트와이스 | 트와이스_0 (5, 0.631) | 트와이스_1 (10, 0.661) | 트와이스_2 (30, 0.588) |
|---|---|---|---|
| 블랙핑크, (190), 0.825 | 트와이스_1, (20), 0.833 | 트와이스_2, (30), 0.854 | 홍승한기자, (9), 0.860 |
| 치타, (109), 0.819 | 홍승한기자, (9), 0.828 | 트와이스_0, (20), 0.833 | 정병근기자, (14), 0.854 |
| 신곡, (400), 0.813 | 슈퍼주니어, (12), 0.825 | 홍승한기자, (9), 0.794 | 트와이스_1, (20), 0.854 |
| 1주년, (201), 0.765 | 트와이스_2, (30), 0.822 | 브라운아이드걸스, (22), 0.783 | 브라운아이드걸스, (22), 0.844 |
| 블락비, (66), 0.758 | 이엑스아이디, (11), 0.813 | 레오, (33), 0.780 | 백퍼센트, (39), 0.843 |
| 타이틀곡, (311), 0.757 | 엔시티, (11), 0.812 | 걸그룹, (880), 0.774 | 소년공화국, (11), 0.835 |
| 곡, (330), 0.756 | 신혜연기자, (12), 0.810 | 정병근기자, (14), 0.771 | 빅히트엔터테인먼트, (17), 0.826 |
| 컴백, (531), 0.754 | 박재범, (35), 0.800 | 걸그룹의, (18), 0.771 | 정용화, (26), 0.825 |
| 아이오아이, (270), 0.747 | 헤이즈, (13), 0.800 | 경리, (120), 0.759 | 슈가, (23), 0.824 |
| 앨범, (1099), 0.720 | 비니와, (11), 0.793 | 베일을, (34), 0.758 | 경리, (120), 0.822 |
뉴스의 경우에도 빈도수가 작은 뉴스_0, 뉴스_1 의 유사어들의 빈도수는 매우 작게 줄어들었습니다.
| 뉴스 | 뉴스_0 (10, 0.647) | 뉴스_1 (30, 0.536) | 뉴스_2 (50, 0.735) |
|---|---|---|---|
| 뉴스_2, (50), 0.735 | 미란다, (373), 0.798 | 채현식, (7), 0.826 | 미란다, (373), 0.799 |
| 뉴스_0, (20), 0.647 | 뉴스_2, (50), 0.785 | 조혜진, (9), 0.800 | 뉴스_0, (20), 0.785 |
| 기사, (1821), 0.598 | 취재원, (358), 0.749 | 이언, (5), 0.794 | 뉴스, (4342), 0.735 |
| 머니, (173), 0.577 | 뉴스_1, (30), 0.675 | 남소연, (10), 0.794 | 재배포금지, (1044), 0.717 |
| 마이데일리, (1823), 0.563 | 재배포금지, (1044), 0.659 | 특산자원인, (6), 0.793 | 취재원, (358), 0.711 |
| 우한, (20), 0.551 | 몽글몽글한, (10), 0.658 | 숲옛마을, (7), 0.793 | 이심기, (7), 0.655 |
| 무단복제, (907), 0.549 | 뉴스, (4342), 0.647 | 최우정, (6), 0.792 | 최지, (68), 0.653 |
| 영상편집, (147), 0.537 | 돌보며, (13), 0.617 | 주전골은, (5), 0.792 | 펴냄, (15), 0.649 |
| 뉴스_1, (30), 0.536 | 삭스, (12), 0.614 | 입욕제, (5), 0.790 | 뉴스_1, (30), 0.647 |
| 창, (899), 0.533 | 색채, (21), 0.613 | 잼, (7), 0.789 | 바로가기, (27), 0.645 |
| 날씨 | 날씨_0 (10, 0.751) | 날씨_1 (20, 0.739) |
|---|---|---|
| 쌀쌀, (77), 0.800 | 날씨_1, (20), 0.877 | 날씨_0, (20), 0.877 |
| 맑은, (76), 0.753 | 청명한, (16), 0.832 | 서울타워, (23), 0.822 |
| 날씨_0, (20), 0.751 | 더운, (15), 0.826 | 더운, (15), 0.817 |
| 날씨_1, (20), 0.739 | 더위, (20), 0.826 | 두물머리, (12), 0.811 |
| 가을, (1219), 0.739 | 이어지겠습니다, (12), 0.810 | 천불동, (7), 0.808 |
| 단풍, (279), 0.733 | 맑고, (40), 0.809 | 김경목, (11), 0.808 |
| 일교차, (53), 0.706 | 서울타워, (23), 0.807 | 물든, (28), 0.806 |
| 추운, (36), 0.694 | 물든, (28), 0.795 | 되찾겠습니다, (7), 0.805 |
| 낮과, (30), 0.679 | 밤의, (31), 0.782 | 아침고요수목원, (9), 0.802 |
| 기온, (301), 0.672 | 내려가면서, (8), 0.773 | 더위, (20), 0.798 |
그런데 정부_1라는 단어는 빈도수가 30 이나 됨에도 불구하고 문맥을 잘 보존하지 못했다는 느낌이 듭니다. 정부_0 부터 정부_3 까지 비슷한 느낌이 듭니다. 그리고 정부 단어의 유사어들과 정부_3 의 유사어들도 다르게 등장합니다. 빈도수 100 은 작지 않은 숫자임에도 불구하고 정부와 유사어들이 조금 다릅니다.
| 정부 | 정부_0 (10, 0.406) | 정부_1 (30, 0.512) | 정부_2 (50, 0.628) | 정부_3 (100, 0.775) | 정부_4 (200, 0.843) |
|---|---|---|---|---|---|
| 정부_4, (200), 0.843 | 안보문제, (7), 0.784 | 라작, (5), 0.750 | 정부_3, (100), 0.795 | 정부_4, (200), 0.896 | 정부_3, (100), 0.896 |
| 정부_3, (100), 0.775 | 내무부, (8), 0.768 | 신조, (33), 0.726 | 정부_4, (200), 0.754 | 정부_2, (50), 0.795 | 정부, (3837), 0.843 |
| 국가, (1500), 0.672 | 최고지도자, (7), 0.768 | 나집, (7), 0.725 | 정부_1, (30), 0.710 | 정부, (3837), 0.775 | 정부_2, (50), 0.754 |
| 박근혜정부, (59), 0.669 | 서청원, (5), 0.762 | 간에는, (13), 0.724 | 의료계, (31), 0.706 | 지도부, (128), 0.722 | 지도부, (128), 0.720 |
| 정권, (586), 0.667 | 시베리아, (16), 0.761 | 이라크의, (7), 0.721 | 정부부처, (27), 0.687 | 박근혜정부, (59), 0.716 | 행정부, (99), 0.718 |
| 재정, (327), 0.663 | 이란의, (10), 0.757 | 정부_2, (50), 0.710 | 부산교통공사, (39), 0.686 | 정부_1, (30), 0.688 | 박근혜정부, (59), 0.702 |
| 지도부, (128), 0.659 | 왕조, (13), 0.756 | 반군지역, (8), 0.709 | 중소기업계, (27), 0.686 | 행정부, (99), 0.681 | 노조, (575), 0.690 |
| 노조, (575), 0.636 | 우파, (22), 0.753 | 러시아와, (50), 0.707 | 매도세, (20), 0.685 | 정부부처, (27), 0.639 | 협회, (187), 0.681 |
| 경제, (2696), 0.635 | 김준배, (10), 0.752 | 통합국방협의체, (21), 0.703 | 군산시의회, (13), 0.681 | 협회, (187), 0.634 | 정부_1, (30), 0.671 |
| 정부_2, (50), 0.628 | 216억원, (5), 0.744 | 민병대, (34), 0.701 | 이보다는, (6), 0.678 | 노조, (575), 0.626 | 시리아, (279), 0.662 |
아프리카는 더 심합니다. 아프리카_1 은 20 번 등장하였지만 문맥이 전혀 학습되지 않았습니다. 사실 이 날 뉴스에서 아프리카는 대륙을 뜻하는 단어와 아프리카 TV 두 가지의 의미로 이용되었습니다. 아프리카의 유사어 중 대부분은 대륙, 국가이지만 방송사 역시 유사어로 학습이 되었습니다. 이 단어가 아프리카 TV 때문에 유사어로 학습된 단어입니다. 그리고 아프리카 TV 를 의미하는 문서의 개수가 아프리카 대륙을 의미하는 문서의 개수보다 훨씬 적었습니다. 그 결과 아프리카는 대체로 대륙의 의미를 지니게 되었습니다.
인공적으로 단어를 바꿀 때, 같은 문맥의 아프리카에서 선택되지 않았기 때문에 발생한 문제로 생각됩니다. 또한 두 문맥에서 등장한 단어들의 빈도수들도 상대적으로 작기 때문이기도 합니다. 반면 트와이스는 맥락이 명확하기 때문에 같은 빈도수라 하더라도 임베딩 벡터가 더 잘 학습되었습니다.
| 아프리카 | 아프리카_0 (10, 0.342) | 아프리카_1 (20, 0.304) | 아프리카_2 (30, 0.497) |
|---|---|---|---|
| 매체, (251), 0.676 | 주제강연, (7), 0.788 | 교토대, (5), 0.850 | 몽골, (114), 0.792 |
| 남미, (61), 0.671 | 자연생태, (14), 0.787 | 교도, (8), 0.838 | 페퍼, (14), 0.787 |
| 협회, (187), 0.666 | 아시아권, (24), 0.785 | 공차, (5), 0.831 | 리조트, (68), 0.786 |
| 터키, (126), 0.656 | 베르사유, (15), 0.778 | 아델, (7), 0.828 | 관광사, (9), 0.778 |
| 영국, (890), 0.627 | 천국, (19), 0.777 | 치어리더, (7), 0.826 | 인덱스, (33), 0.774 |
| 에어비앤비, (161), 0.617 | 카사블랑카, (11), 0.771 | 체대, (6), 0.825 | 일본사, (22), 0.774 |
| 자국, (125), 0.601 | 메카, (31), 0.771 | 미국교회, (8), 0.821 | 아이슬란드, (19), 0.774 |
| 독일, (967), 0.600 | 티베트, (14), 0.770 | 캠벨, (5), 0.821 | 계측기, (14), 0.773 |
| 방송사, (138), 0.599 | 미야기, (5), 0.766 | 이은상, (5), 0.820 | 향신료, (13), 0.772 |
| 브렉시트, (149), 0.596 | 재즈계, (6), 0.766 | 한베, (5), 0.820 | 남미, (61), 0.770 |
그리고 단어의 빈도수가 많을수록 본래 단어와의 유사도가 높아짐을 확인할 수 있습니다. 이러한 패턴은 다른 단어들에서도 어느 정도 보입니다.
| 경제 | 경제_0 (10, 0.668) | 경제_1 (30, 0.578) | 경제_2 (50, 0.628) | 경제_3 (100, 0.787) | 경제_4 (200, 0.849) |
|---|---|---|---|---|---|
| 경제_4, (200), 0.849 | 경제_3, (100), 0.825 | 경제_2, (50), 0.799 | 경제_3, (100), 0.859 | 경제_4, (200), 0.862 | 경제_3, (100), 0.862 |
| 경제_3, (100), 0.787 | 경제_4, (200), 0.808 | 다운타운, (5), 0.781 | 경제_1, (30), 0.799 | 경제_2, (50), 0.859 | 경제, (2696), 0.849 |
| 저성장, (92), 0.736 | 시장경제, (30), 0.752 | 홍창진, (6), 0.773 | 권위주의, (10), 0.748 | 경제_0, (20), 0.825 | 경제_0, (20), 0.808 |
| 정치, (1520), 0.722 | 경제_2, (50), 0.719 | 심인성, (14), 0.773 | 유라시아, (23), 0.748 | 경제, (2696), 0.787 | 경제_2, (50), 0.730 |
| 저출산, (128), 0.701 | 경제_1, (30), 0.706 | 신자유주의, (6), 0.772 | 발해의, (11), 0.738 | 시장경제, (30), 0.766 | 저출산, (128), 0.725 |
| 재정, (327), 0.687 | 신약개발, (62), 0.689 | 빠지면서, (6), 0.771 | 동아시아, (65), 0.735 | 경제_1, (30), 0.763 | 사회, (1977), 0.698 |
| 위기, (800), 0.685 | 권위주의, (10), 0.681 | 패권, (12), 0.767 | 영토, (41), 0.734 | 새판, (45), 0.731 | 저성장, (92), 0.697 |
| 고령화, (94), 0.683 | 동아시아, (65), 0.678 | 와통일을여는사람들, (15), 0.767 | 경제_4, (200), 0.730 | 동아시아, (65), 0.726 | 정치, (1520), 0.696 |
| 국가, (1500), 0.682 | 사회, (1977), 0.672 | 이란의, (10), 0.766 | 경제_0, (20), 0.719 | 유연성, (30), 0.714 | 파급효과, (32), 0.673 |
| 사회, (1977), 0.675 | 유연성, (30), 0.671 | 풀뿌리, (8), 0.764 | 극단주의, (32), 0.719 | 권위주의, (10), 0.714 | 권위주의, (10), 0.671 |
인위적으로 생성한 유사도의 빈도수를 조금 더 크게 설정한 경우
이번에는 동일한 설정에서 인공적으로 생성한 유사어들의 빈도수를 크게 (더 많은 단어를 유사어로 치환) 설정하였습니다. 트와이스 의 인공 유사어들은 역시 학습이 잘 됩니다. 하지만 트와이스_0 과 트와이스_1 의 유사어의 빈도수는 조금 다릅니다. 아마도 이는 임의로 인공 유사어를 만드는 과정에서 트와이스_0 의 문맥보다 트와이스_1의 문맥이 한 쪽으로 몰려있었기 때문이라 짐작됩니다.
| 트와이스 | 트와이스_0 (20, 0.588) | 트와이스_1 (20, 0.699) | 트와이스_2 (30, 0.688) |
|---|---|---|---|
| 블랙핑크, (190), 0.821 | 홍승한기자, (9), 0.868 | 트와이스_2, (30), 0.857 | 트와이스_0, (20), 0.861 |
| 치타, (109), 0.806 | 트와이스_2, (30), 0.861 | 걸그룹, (880), 0.812 | 트와이스_1, (20), 0.857 |
| 신곡, (400), 0.796 | 슈퍼주니어, (12), 0.856 | 트와이스_0, (20), 0.803 | 홍승한기자, (9), 0.821 |
| 타이틀곡, (311), 0.784 | 베일을, (34), 0.852 | 몬스타엑스, (149), 0.786 | 정용화, (26), 0.811 |
| 블락비, (66), 0.779 | 브아걸, (14), 0.844 | 나인뮤지스, (166), 0.772 | 박재범, (35), 0.807 |
| 컴백, (531), 0.764 | 브라운아이드걸스, (22), 0.841 | 소녀시대, (66), 0.770 | 베일을, (34), 0.802 |
| 아이오아이, (270), 0.760 | 레드벨벳, (10), 0.835 | 경리, (120), 0.766 | 이엑스아이디, (11), 0.800 |
| 곡, (330), 0.746 | 최파타, (6), 0.832 | 블락비, (66), 0.758 | 블락비, (66), 0.800 |
| 신화, (477), 0.742 | 종이학, (15), 0.829 | 베일을, (34), 0.752 | 비투비, (38), 0.798 |
| 1주년, (201), 0.733 | 브랜뉴뮤직, (6), 0.827 | 백퍼센트, (39), 0.743 | 슈퍼주니어, (12), 0.798 |
하지만 뉴스_0 의 유사어들은 거의 모두가 infrequent words 입니다. 뉴스_0 은 지나치게 다양한 문맥에서 샘플링이 되어 임베딩 벡터가 제대로 학습되지 않은 것으로 예상됩니다.
| 뉴스 | 뉴스_0 (20, 0.631) | 뉴스_1 (30, 0.534) | 뉴스_2 (50, 0.656) |
|---|---|---|---|
| 뉴스_2, (50), 0.656 | 뉴스_1, (30), 0.845 | 숲옛마을, (7), 0.856 | 미란다, (373), 0.798 |
| 뉴스_0, (20), 0.631 | 채현식, (7), 0.801 | 특산자원인, (6), 0.855 | 뉴스_0, (20), 0.792 |
| 기사, (1821), 0.573 | 코스모폴리탄, (25), 0.795 | 이재형, (10), 0.852 | 뉴스_1, (30), 0.776 |
| 영상편집, (147), 0.554 | 뉴스_2, (50), 0.792 | 2580, (45), 0.849 | 대학경제, (19), 0.772 |
| 현입니다, (13), 0.554 | 애널리틱스, (10), 0.786 | 정신상태, (5), 0.847 | 임상연, (6), 0.771 |
| 마이데일리, (1823), 0.545 | 술로, (5), 0.783 | 뉴스_0, (20), 0.845 | 취재원, (358), 0.766 |
| 머니, (173), 0.538 | 타듯, (5), 0.778 | 781220, (20), 0.845 | 한종찬, (28), 0.763 |
| 금기, (21), 0.536 | 기프티콘, (6), 0.777 | 노산, (6), 0.844 | 남혁우, (20), 0.760 |
| 뉴스_1, (30), 0.534 | 특산자원인, (6), 0.773 | 화약고, (7), 0.841 | 한주희, (7), 0.759 |
| 재배포금지, (1044), 0.530 | 벗, (5), 0.772 | 바라보았습니다, (6), 0.837 | 손현규, (7), 0.755 |
그 외 아래의 결과들도 인공 유사어의 임베딩 벡터가 잘 학습된 경우에는 유사어들의 빈도수가 작지 않고 다양하며, 최소 빈도수에 가까운 빈도수를 지니는 단어들이 유사어로 검색된다는 것은 그 단어의 임베딩 벡터가 제대로 학습되지 않았다는 의미임을 알 수 있습니다.
| 날씨 | 날씨_0 (20, 0.732) | 날씨_1 (20, 0.745) |
|---|---|---|
| 맑은, (76), 0.794 | 더운, (15), 0.832 | 물든, (28), 0.782 |
| 쌀쌀, (77), 0.783 | 완연한, (21), 0.829 | 더웠던, (8), 0.781 |
| 단풍, (279), 0.751 | 청명한, (16), 0.818 | 더운, (15), 0.775 |
| 날씨_1, (20), 0.745 | 이어지겠습니다, (12), 0.817 | 맑고, (40), 0.770 |
| 가을, (1219), 0.744 | 더위, (20), 0.796 | 노랗게, (8), 0.767 |
| 날씨_0, (20), 0.732 | 되찾겠습니다, (7), 0.793 | 내음, (6), 0.766 |
| 추운, (36), 0.729 | 더웠던, (8), 0.784 | 산과, (16), 0.764 |
| 안개, (177), 0.721 | 밤부터는, (6), 0.771 | 붉게, (17), 0.755 |
| 일교차, (53), 0.715 | 넘친다, (11), 0.771 | 헤비다운, (8), 0.755 |
| 미세먼지, (323), 0.691 | 내려가면서, (8), 0.766 | 낮과, (30), 0.754 |
| 정부 | 정부_0 (20, 0.545) | 정부_1 (30, 0.586) | 정부_2 (50, 0.663) | 정부_3 (100, 0.762) | 정부_4 (200, 0.843) |
|---|---|---|---|---|---|
| 정부_4, (200), 0.843 | 정부_1, (30), 0.761 | 정부_2, (50), 0.839 | 정부_1, (30), 0.839 | 정부_4, (200), 0.877 | 정부_3, (100), 0.877 |
| 정부_3, (100), 0.762 | 신용평, (9), 0.749 | 정부_3, (100), 0.776 | 정부_3, (100), 0.828 | 정부_2, (50), 0.828 | 정부, (3837), 0.843 |
| 국가, (1500), 0.686 | 정부_2, (50), 0.744 | 정부_0, (20), 0.761 | 정부_4, (200), 0.788 | 정부_1, (30), 0.776 | 정부_2, (50), 0.788 |
| 정권, (586), 0.674 | 헤이그, (12), 0.704 | 지도부, (128), 0.734 | 정부_0, (20), 0.744 | 정부, (3837), 0.762 | 지도부, (128), 0.750 |
| 지도부, (128), 0.674 | 집행부, (14), 0.695 | 정부_4, (200), 0.730 | 전국경제인연합회, (60), 0.711 | 지도부, (128), 0.694 | 정부_1, (30), 0.730 |
| 정부_2, (50), 0.663 | 리비아, (17), 0.694 | 각료, (13), 0.728 | 지도부, (128), 0.705 | 정부_0, (20), 0.680 | 행정부, (99), 0.668 |
| 재정, (327), 0.657 | 노동계, (26), 0.691 | 전국경제인연합회, (60), 0.694 | 한국전력공사, (36), 0.698 | 행정부, (99), 0.666 | 지방정부, (41), 0.667 |
| 박근혜정부, (59), 0.655 | 쿠르드계, (8), 0.689 | 행정부, (99), 0.692 | 세르비아, (9), 0.684 | 한국전력공사, (36), 0.646 | 시리아, (279), 0.665 |
| 경제, (2696), 0.652 | 정윤회씨, (8), 0.688 | 수뇌부, (19), 0.676 | 동구의회, (6), 0.681 | 중앙정부, (45), 0.644 | 박근혜정부, (59), 0.663 |
| 노조, (575), 0.633 | 터키군, (9), 0.687 | 김광림, (23), 0.666 | 협회, (187), 0.679 | 전국경제인연합회, (60), 0.643 | 국가, (1500), 0.655 |
| 아프리카 | 아프리카_0 (20, 0.322) | 아프리카_1 (20, 0.562) | 아프리카_2 (30, 0.434) |
|---|---|---|---|
| 남미, (61), 0.656 | 레탑코리아, (9), 0.820 | 카타르, (22), 0.781 | 향신료, (13), 0.816 |
| 이슬람, (129), 0.645 | 시장의, (20), 0.816 | 아프리카_2, (30), 0.761 | 제국주의, (11), 0.802 |
| 매체, (251), 0.645 | 시아, (7), 0.795 | 핀란드, (31), 0.759 | 문화도시, (7), 0.798 |
| 종교, (111), 0.639 | 오세아니아, (26), 0.792 | 지수인, (11), 0.754 | 불가리, (20), 0.797 |
| 영국, (890), 0.637 | 핀란드, (31), 0.789 | 왕조, (13), 0.741 | 조선왕조, (12), 0.793 |
| 브렉시트, (149), 0.631 | 센트럴, (6), 0.778 | 지리, (19), 0.740 | 왕조, (13), 0.791 |
| 에어비앤비, (161), 0.622 | 다국적기업, (9), 0.775 | 단세포, (23), 0.739 | 차이콥스키, (7), 0.786 |
| 전근대, (5), 0.619 | 재즈계, (6), 0.773 | 미네, (10), 0.738 | 피렌체, (19), 0.785 |
| 오늘날, (109), 0.618 | 심포니, (12), 0.773 | 뉴질랜드, (86), 0.737 | 다이어리, (5), 0.785 |
| 일본, (2728), 0.618 | 회사인, (16), 0.773 | 동남아시아, (48), 0.735 | 스페인의, (13), 0.780 |
| 경제 | 경제_0 (20, 0.496) | 경제_1 (30, 0.388) | 경제_2 (50, 0.648) | 경제_3 (100, 0.807) | 경제_4 (200, 0.835) |
|---|---|---|---|---|---|
| 경제_4, (200), 0.835 | 경제_1, (30), 0.851 | 향신료, (13), 0.855 | 경제_3, (100), 0.842 | 경제_4, (200), 0.910 | 경제_3, (100), 0.910 |
| 경제_3, (100), 0.807 | 경제_2, (50), 0.817 | 경제_0, (20), 0.851 | 경제_0, (20), 0.817 | 경제_2, (50), 0.842 | 경제, (2696), 0.835 |
| 저성장, (92), 0.733 | 헤게모니, (5), 0.792 | 시간대별, (9), 0.850 | 경제_1, (30), 0.786 | 경제, (2696), 0.807 | 경제_2, (50), 0.781 |
| 정치, (1520), 0.727 | 르완다, (10), 0.792 | 청심국제고, (5), 0.844 | 경제_4, (200), 0.781 | 저성장, (92), 0.735 | 저성장, (92), 0.761 |
| 위기, (800), 0.697 | 왕조, (13), 0.786 | 9만6497개, (12), 0.837 | 권위주의, (10), 0.740 | 시장경제, (30), 0.731 | 민주화, (64), 0.751 |
| 저출산, (128), 0.694 | 향신료, (13), 0.778 | 진리탐구, (6), 0.834 | 공동화, (8), 0.729 | 경제_0, (20), 0.730 | 정치, (1520), 0.747 |
| 재정, (327), 0.693 | 나가서까지, (7), 0.778 | 가로뷰, (12), 0.834 | 우선순위, (27), 0.728 | 권위주의, (10), 0.700 | 새판, (45), 0.733 |
| 국가, (1500), 0.687 | 선비들, (15), 0.769 | 제국주의, (11), 0.833 | 굴기, (5), 0.725 | 저출산, (128), 0.692 | 산업화, (145), 0.725 |
| 고령화, (94), 0.661 | 비수도권, (6), 0.765 | 안산동산고, (5), 0.832 | 꺼졌습니다, (9), 0.717 | 경제활성화, (38), 0.692 | 짜기, (46), 0.714 |
| 산업화, (145), 0.653 | 발자취, (11), 0.762 | 선비들, (15), 0.830 | 신용평, (9), 0.716 | 동아시아, (65), 0.683 | 동아시아, (65), 0.713 |
Discussion
위 관찰을 통해 우리가 얻을 수 있는 몇 가지 발견이 있습니다.
첫째, Gensim 의 Word2Vec 은 분명 단어 빈도수의 영향을 받으며 임베딩 벡터를 학습합니다. Infrequent words 들이 모이는 공간이 있음이 분명합니다. 그 근거로 infrequent words 의 유사어는 대체로 infrequent 합니다.
둘째, 한 단어의 유사어들의 빈도수가 매우 작을 경우 (특히 min_count 에 가까울 경우) 그 단어는 임베딩 벡터가 제대로 학습되지 않았을 가능성이 있습니다. 하지만 그 단어가 등장하는 맥락이 모호하지 않은 경우에는 infrequent words 사이에서도 맥락이 어느 정도 보존이 됩니다. 이는 트와이스 의 경우에서 살펴 볼 수 있습니다.
셋째, 각 단어마다 문맥이 학습되기 위한 최소 빈도수가 다릅니다. 정확히는 단어의 빈도수가 어느 정도 이상이 된다고 반드시 질좋은 임베딩 벡터를 학습하는 것은 아닙니다. 트와이스_n 은 빈도수가 5 나 10 임에도 좋은 임베딩 벡터가 학습되지만 아프리카_n 은 빈도수가 20, 30 이 되어도 좋은 임베딩 벡터를 얻지 못했습니다. 이 이유는 단어의 빈도수가 아니라 단어의 문맥이 명확하지 않았기 때문입니다 (해당 날의 뉴스에서 아프리카는 적어도 대륙의 의미와 아프리카 TV, 두 가지 이상의 의미로 이용되었습니다)
넷째, 문맥이 두 가지 이상으로 이용되는 경우에는 가장 많이 나온 문맥으로 학습될 가능성이 높습니다.
이 네가지 관찰을 정리하면, 문맥만 뚜렷하다면 단어 빈도수가 작더라도 임베딩 벡터는 문맥 정보를 포함할 것입니다. 그리고 모든 단어에 대하여 일률적으로 최소 빈도수 threshold 를 이용하기도 어렵습니다.
이로부터 Gensim 의 Word2Vec 을 사용할 때의 min_count 설정에 대한 의사결정을 할 수 있습니다. 학습하는데 큰 부담이 되지 않는다면 일단 min_count 는 어느 정도로 작게 설정합니다. 학습이 끝난 뒤 임베딩 벡터를 이용하기 전에 각 단어의 유사어들의 빈도수 분포를 확인합니다. 유사어들의 빈도수들이 대부분 min_count 에 가깝다면 그 단어는 사용하지 않습니다. 이처럼 단어 벡터를 선택적으로 이용한다면 정말로 임베딩 벡터가 제대로 학습되지 않은 단어들을 걸러낼 수 있고, infrequent 하지만 운이 좋게도 임베딩 벡터가 잘 학습된 단어의 벡터를 버리지 않을 수도 있을 것입니다.
이를 위해 학습된 Word2Vec model 에서 임베딩 벡터와 단어의 빈도수를 가져옵니다.
from gensim.models import Word2Vec
import numpy as np
word2vec_model = Word2Vec(corpus, min_count=5)
# embedding vector
wv = word2vec_model.wv.syn0
# idx to count
vocabs = word2vec_model.wv.vocab
idx_to_count = np.asarray([vocab.count for vocab in sorted(vocabs.values(), key=lambda x:x.index)])단어의 개수가 많을 수 있기 때문에 batch_size 개수의 단어만을 선택하여 pairwise distance 를 계산합니다. 그리고 가장 가까운 topk 개의 빈도수의 평균값을 mean_count 에 저장합니다.
from math import ceil
from sklearn.metrics import pairwise_distances
def check_count_of_similars(batch_size=500, topk=10):
n_vocabs = wv.shape[0]
max_batch = ceil(n_vocabs / batch_size)
mean_count = np.zeros(n_vocabs)
for b in range(max_batch):
begin = b * batch_size
end = min((b + 1) * batch_size, n_vocabs)
dist = pairwise_distances(wv[begin:end], wv, metric='cosine')
idxs = dist.argsort(axis=1)[:,1:topk+1]
for i in range(idxs.shape[0]):
mean_count[begin + i] = idx_to_count[idxs[i]].sum()/topk
print('\r{} / {}'.format(b+1, max_batch), end='')
print('\r{0} / {0} done'.format(max_batch))
return mean_count
mean_count = check_count_of_similars()mean_count 를 바탕으로 빈도수가 5 인 세 개의 단어의 mean_count 와 그 유사어들을 확인해봅니다. 2016-10-20 일 근처에 갤럭시노트7 의 화재 위험성으로 유럽항공안정청에서 갤럭시 노트를 기내에 가져오지 못하게 하는 발표들이 있었습니다. 그리고 이날 오패산 터널에서 총격 사건이 있었습니다. 유럽항공안정청과 폭행용의자는 빈도수가 적지만 문맥을 반영한 단어 벡터가 학습되었습니다. 하지만 천재교육의 유사어들은 특별한 맥락을 유추하기가 어렵습니다. 그리고 유사어들의 빈도수도 매우 작습니다.
| 유럽항공안전청 (mean_count=319.200) | 폭행용의자 (mean_count=199.000) | 천재교육 (mean_count=11.100) |
|---|---|---|
| 은행들 (130, 0.548) | 출동 (603, 0.760) | 패럴림픽 (7, 0.826) |
| 통신 (416, 0.544) | 구급대 (9, 0.759) | 90명 (10, 0.797) |
| 업체들 (244, 0.531) | 난사 (170, 0.749) | 750명 (5, 0.796) |
| 노트7 (140, 0.518) | 쏜 (457, 0.726) | 문화관광권역 (5, 0.791) |
| 은행 (1110, 0.516) | 총탄 (148, 0.704) | 연대파업 (30, 0.791) |
| 증권 (167, 0.511) | 총을 (474, 0.704) | 노크 (9, 0.789) |
| 리콜 (176, 0.508) | 숨어있다가 (10, 0.698) | 재즈페스티벌 (18, 0.781) |
| 구매자들 (59, 0.503) | 쓰러졌다 (44, 0.691) | 선발시험 (8, 0.779) |
| 갤럭시노트7 (351, 0.497) | 치여 (19, 0.687) | 3조원대 (7, 0.775) |
| 애플 (399, 0.496) | 풀숲 (56, 0.684) | 과학기술전시회 (12, 0.774) |
이처럼 단어의 출현 빈도수가 작다하여 단어 임베딩 벡터가 완전히 학습되지 않는 것도 아닙니다. 학습 후 후처리 과정을 거쳐 질 좋은 단어들의 벡터만을 선택할 수도 있습니다.